百度可观测系列 | 采集亿级别指标,Prometheus 集群方案这样设计
作者:技术小智2022.02.22 18:07浏览量:1420简介:采集亿级别指标,Prometheus集群方案这样设计
【百度云原生导读】在前一篇《基于 Prometheus 的大规模线上业务监控实践》中,我们为大家介绍了针对大规模业务监控场景,百度云原生团队基于 Prometheus 技术方案的一些探索,包括基于 Prometheus 进行指标降维、Prometheus 的自动分片采集、以及基于 Flink 流式计算构建的预计算。
本文将深入采集专题,为大家介绍如何构建采集亿级别指标的高可靠Prometheus 集群。
采集亿级别指标,通常会面临三大类问题:一是网络带宽打满、Prometheus大内存、Prometheus计算 CPU 利用率高等一系列资源类问题;二是如何构建高可用、高可靠的集群,如何确保监控数据的不丢不重等高可用类问题;三是集群的自动弹性扩缩,如何进一步降低运维成本等运维类问题。只有解决好这三类核心问题才能构建出一套理想的 Prometheus 采集集群。
为此,百度云原生团队针对 Prometheus 提出了“流计算加速”、“高可用HA”、“感知采集压力的自动分片管理”等多项“外科手术式打击”般的精准解决方案,最终实现了亿级别指标的采集。
下文将从“资源、高可用、运维”三个方面,为大家带来我们的实战经验。
资源
采集开压缩,降低网络带宽压力
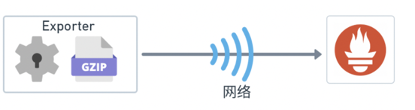
按照单指标100b大小、5s采集一次计算,采集亿级别指标,采用千兆网卡也存在网卡被打满现象;另外监控作为服务的旁路系统,首先要保证的是不能影响业务的正常使用。Prometheus 自身支持带压缩的采集,只需将 Exporter 中 HTTP Content-Encoding 设置为 Gzip 即可开启。经实际测试,开启压缩后,压缩率通常在几十分之一,这样就可降低网络带宽压力;如果 Exporter 吐出数据块相同部分较多,压缩将更加有效。
指标压缩+加快数据落盘,避免大内存问题
Prometheus 大内存问题是被经常诟病的问题之一,随着数据采集时长增加,Prometheus CPU 和内存都会升高,但内存会首先达到瓶颈,这会导致 Prometheus 发生OOM 造成重启,采集发生中断。为解决这个问题,我们可以从以下两方面入手:
减少维度数量,缩短指标、维度长度来减少内存使用:Prometheus 将最近拉取的数据保存在内存中,提供实时数据的高效查询;另外加载查询历史数据时,需要将历史数据加载到内存中。如果维度数量多或者指标、维度字符长度过长,内存使用量就会越大。因此可以通过减少维度数量、或者缩短指标、维度字符长度来降低内存使用量。需要注意的一点是缩短指标和维度时,对于指标能够反映出其所属的域以及指标单位,对于维度可反映该实例的维度特征。
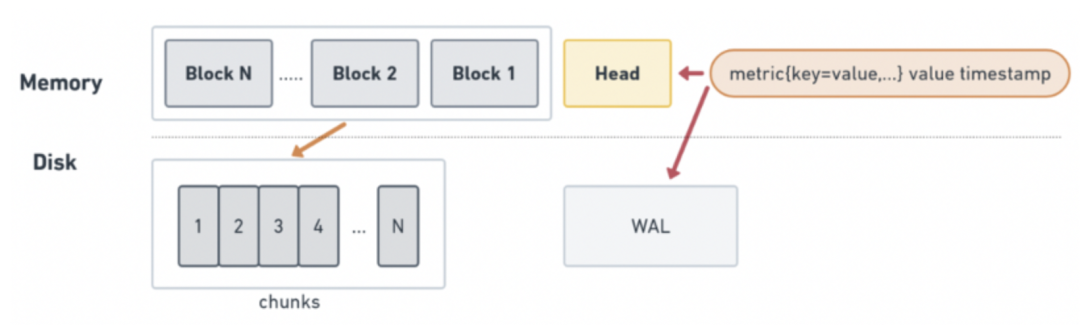
加快 block 数据落盘频率来释放内存:Prometheus 内存消耗主要是因为每隔2小时做一次 block 数据落盘,落盘之前所有数据都在内存里面,默认是2h落盘一次。因此可以通过调整 Prometheus 内存数据保存时长,加快落盘频率来释放内存。在生产环境可根据实际情况进行缩短,如调整到半小时级别。
引入流式计算,降低 CPU 使用
Prometheus 提供了预聚合 (Recording Rule) 可以让我们对一些常用的指标或者计算相对复杂的指标提前计算,然后将这些数据存储到新的数据指标中,查询这些计算好的数据将比查询原始的数据更快更便捷。但 Prometheus 提供的预聚合采用的是“批计算”,Prometheus 首先会缓存所有指标,在窗口将要关闭时进行实时查询计算,这对于承担大规模采集任务的 Prometheus 是致命的,因为在每次执行计算时,会消耗大量的CPU,同时计算的延迟特别大,对于万级别的指标量计算延迟将达到分钟级别,考虑到后续报警等通路的延迟,这样的延迟在预计算侧显然是不能接受的。
针对预计算慢的问题,通过自研 Adapter 模块将“批计算”改为“流计算”来加速。以计算每个周期的总请求数为例,使用 PromQL 可以通过前后两个周期的 Sum 值相减来计算,并在 PromQL 中指定需要保留的维度,但 PromQL 计算时减法、求和是发生在计算窗口关闭时;而使用 Adapter 的流计算,其具体做法是:
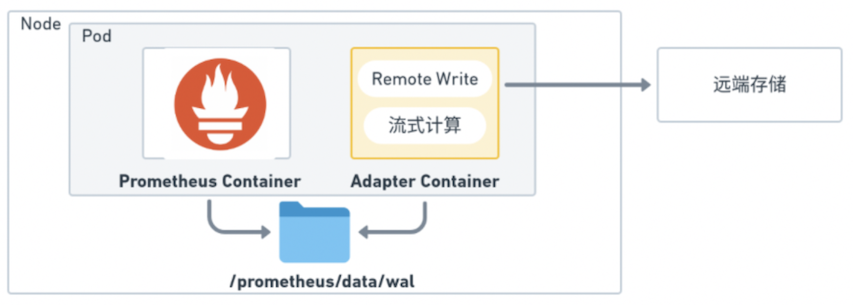
1. Adapter 模块与 Prometheus 同 Pod 部署,并实时读取 Prometheus 的 WAL 数据;
2. Adapter 模块缓存了该 Prometheus 上个采集周期所有时序数据的值,读取到本周期的值后减去上个周期值,作为该时序数据本周期的增量值;
3. 求得本周期增量值后,根据用户配置的汇聚规则直接将该增量值累加为和值;
4. 当计算窗口关闭时,可直接输出累加的和值;
可以看到 Adapter 通过以数据驱动的流处理达到了计算加速的效果。同时 Adapter 模块同时还可执行指标的黑白名单过滤、指标标签的 Relabel 等操作。常规的 Prometheus数据发送是通过 Remote Write 方案,使用该方案需要对时序数据经过多次的序列化与反序列化,同时还有数据传输上的消耗,使用 Adapter 直接读取 WAL 数据则避免了这些消耗,降低了 CPU 的使用。
高可用 HA
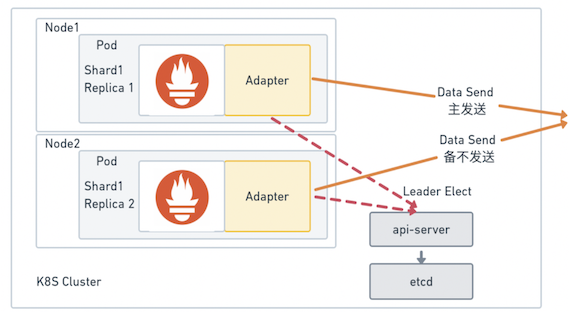
Prometheus 有本地存储数据能力,但 Prometheus 之间没有数据同步能力。所以要想在保证可用性的前提下再保持高可用,使用 HA 是最佳的方案。将采集的任务分 Shard,每个 Shard 包含两个 Prometheus 副本。每个副本都有自己对应的 Sidecar Adapter。Adapter 做选主逻辑,只有主 Adapter 对应的 Prometheus 副本数据能推送到后续通路,这样可以保证一个异常,另一个也能推送成功,确保数据的不丢不重。在实现 Adapter 的选主可以有多种方案,比如 Raft、依赖 Zookeeper 等。由于部署在 K8s 集群中,从时效性、可运维性等方面考虑,基于 K8s Lease 资源,实现租约机制的选主方案是最佳方案。采用该方案在 Prometheus 异常、Adapter 异常甚至两者都异常时都可在5s内实现主备切换,确保了采集数据的不丢失。
与常见的 Prometheus 高可用方案 Federate、Cortex、Thanos 相比,使用基于Adapter 做数据去重的方案可以避免如下问题:Federate 方案需要逐层做数据聚合,将减少的后的数据传输到中央 Prometheus 中,故其适用于最终分析的数据量偏少的场景。Thanos 的数据去重是查询时数据去重,这意味着 Thanos 会存储多份的冗余数据,存储的开销也会相应地更大 。
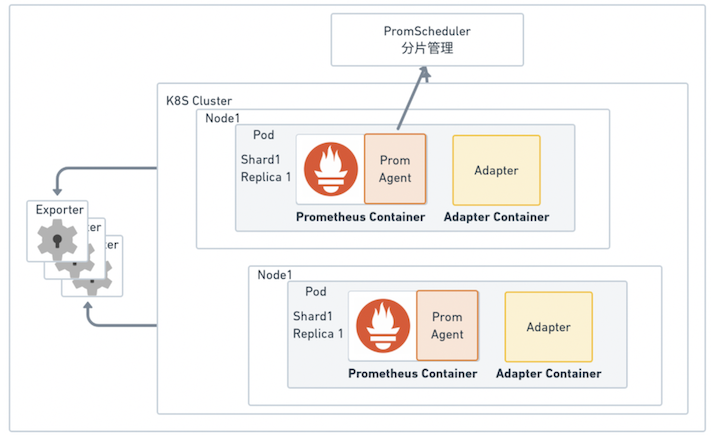
采用云原生部署,降低运维成本
作为新一代的开源监控解决方案,Prometheus 自身具有强大的采集性能,单实例采集能力可达百万级别指标。如果采集亿级别指标,粗略估算需要几百台服务器;再考虑采集集群的容灾、冗余等问题,消耗的服务器资源甚至可达上千台。若维护这上千台服务器需要耗费大量的成本。为降低运维成本,在这里我们采用 容器+K8S 的云原生部署模式,将 Prometheus 部署到 K8S 集群中。
考虑到 Exporter 吐出的指标量会随着新指标、新维度的出现发生变化,导致 Prometheus 的采集压力发生变化。我们还自研了 PromAgent 与 PromScheduler 模块,PromAgent实时感知 Prometheus 采集压力的变化,并上报给 PromScheduler;PromScheduler 收到采集压力数据后,其分片管理功能根据自动分配算法进行自动伸展。
结语
在本文中,我们聚焦于采集专题,介绍了采集亿级别指标的 Prometheus 集群设计方案,包括“资源、高可用、运维“这三方面。在后续的系列文章中,我们将继续从计算、存储和报警等各环节出发,继续探讨如何基于 Prometheus 构建高性能、低延迟、高可用的监控系统,敬请期待。
相关文章推荐
发表评论
关于作者

- 被阅读数
- 被赞数
- 被收藏数
登录后可评论,请前往 登录 或 注册