无服务器系统的设计模式
作者:技术大发2022.03.02 17:06浏览量:707简介:无服务器系统的设计模式
作者 | Tridib Bolar
译者 | 张卫滨
策划 | 丁晓昀
在软件架构和应用设计领域,设计模式是基本的构建块之一。设计模式的概念是由 Christopher Alexander 在上世纪 70 年代末提出来的(The Timeless Way of Building, 1979 以及 A Pattern Language—Towns, Buildings, Construction, 1977):
每个模式都描述了一个在我们的环境中不断出现的问题,然后描述了该问题的解决方案的核心。通过这种方式,我们可以无数次地使用那些已有的解决方案,而无需重复相同的工作。—— Alexander et al
随后,这个概念被软件社区所采用,从而产生了应用于软件设计领域的不同种类的设计模式。
面向对象的设计模式是一个抽象工具,用来设计遵循 OOP 方式的代码级别的构建块。Erich Gamma、Richard Helm、Ralph Johnson 和 John Vlissides(Gangs of Four - GoF)合作撰写的图书 Design Patterns Elements of Reusable Object-Oriented Software(中译本名为《设计模式:可复用面向对象软件的基础》由机械工业出版社出版——译者注)为开发人员提供了面向对象设计领域的一个指导手册。这本书于 1994 年首次出版,从那时起,设计模式就成为了软件设计的一个组成部分。
设计模式也适用于组织。一个大型的组织确实就像一台庞大的机器,它有很多的齿轮、管道、过滤器、马达等等。在数字时代,我们正在试图将人脑数字化,因此将企业机器进行数字化并不是什么了不起的事情。将企业的某一组成部分或者某一区域实现数字化是不够的。实际上,要操控一个企业,就必须要集成其所有不同的组成部分。企业和解决方案架构师在尝试使用模式来解决日常的集成场景。这个过程是真正敏捷的。每天,来自世界各个角落的思想家们都在解决问题,并发明新的企业集成模式。在这里,我想要提及该领域的两位大师,Martin Fowler 和 Gregor Hohpe。
高层管理人员在不断追逐新的技术趋势,每天都有新的数字产品变种问世。商业人士都想方设法在这个数字海洋中获取最大的利益,所以有必要对遗留系统进行现代化改造,也就是所谓的数字化转型。在这个领域中,像 Ian Cartwright、Rob Horn、James Lewis 这样的研究人员也基于他们多年的迁移经验,在最近的 Patterns of Legacy Displacement 文章中提出了一些模式。
在这个快速变更的时代,敏捷性是成功的关键。弹性、持续交付、更快的上市时间、高效开发等等,这些都是推动系统向微服务架构转移的力量。但与此同时,并不是所有的场景都适合微服务。为了帮助我们理解这个边界在哪里,微服务模式的作者 Chris Richardson 为不同的使用场景提出了大量的微服务模式。
除了我上面提到的这些之外,还有更多的模式类别。事实上,关于企业系统架构和软件的模式有大量的文献。这意味着,架构师们需要明智地选择该如何满足他们的要求。
进入无服务器的领域
到目前为止,我们已经讨论了针对不同需求和架构的不同类型的模式,但是我们忽略了一个重要的场景,也就是无服务器的系统。在当前的技术范围内,无服务器是最重要和最有活力的方式之一,尤其是在 IaaS 和云计算领域。
无服务器平台可以分为两大类,分别是函数即服务(Function as a Service,FaaS)和后端即服务(Backend as a Service,BaaS)。FaaS 模式允许客户建立、部署、运行和管理他们的应用,而无需管理底层的基础设施。与之不同的是,BaaS 提供在线服务,通过云的方式处理特定的任务,比如认证、存储管理、通知、消息等等。
所有面向无服务器计算的服务都属于 FaaS 这一类别(比如 AWS Lambda、Google Cloud Function、Google Run、Apache OpenWhisk),而其他的无服务器服务则可以归为 BaaS,比如无服务器存储(AWS DynamoDB、AWS S3、Google Cloud Storage)、无服务器工作流(AWS Step Function)、无服务器消息(AWS SNS、AWS SQS、Google PubSub)等等。
无服务器这个术语非常具有吸引力,但是它可能会有一定的误导性。真的有服务能够无需服务器就能存在吗?在云供应商提供的所有无服务器组件的背后,隐藏着一个很简单的魔法:在这些组件幕后,都有一个服务器。云提供商负责管理物理机和 / 或虚拟服务器的可扩展性(自动扩展)、可调用性、并发、网络等,同时还会为终端用户提供一个接口来配置它们,包括像自定义运行时、环境变量、版本、安全库、并发、读 / 写容量等。
如果我们专注于使用无服务器方式实现一个架构的话,那么随之而来的是一些基本的、高层次的问题。
使用无服务器构建块设计一个系统时,首选的架构风格是什么?
我们的应用要采取纯粹的无服务器方式,还是采用混合方式?
我们该在哪些用例中采用无服务器方式呢?
在实现无服务器应用的时候,有哪些可重用的架构构建块或模式呢?
在本文剩余的内容中,我将会阐述上述四个问题的答案。
无服务器模式
在技术领域,无服务器模式相对比较新,而且正处于快速发展之中。它所涉及的不同方面,包括运行机制、适用性、使用场景、使用模式、实现模式等,每一步都在不断发生着变化。不仅如此,随着云供应商不断发明新的无服务器产品,同样的微服务模式可以通过各种方式来实现,它们的价格和性能也各不相同。在世界范围内,软件工程师都在从不同的视角出发,使用不同的方式在思考。因此,到目前为止,尚未形成构建无服务器系统的通用方式。
在 API Days 澳大利亚会议上,来自亚马逊云科技的解决方案架构师 Cassandra Bonner 做了一个关于 Lambda 无服务器服务的五个主要使用模式的演讲。她从需求的角度定义了这五个模式:
事件驱动的数据处理。
Web 应用。
移动和物联网应用。
应用生态系统。
事件工作流。
Peter Sbarski 在他的 Serverless Architectures on AWS 一书中给出了在无服务器架构下解决通用设计问题的五个模式。它们是:
命令(Command)
消息(Messaging)
优先级队列(Priority queue)
扇出(Fan-out)
管道和过滤器(Pipes and filters)
这些模式并不是无服务器架构所特有的。实际上,它们是分布式系统模式的一个子集,比如由 Gregor Hohpe 和 Bobby Woolf 总结整理的 65 个消息模式,它们代表了这种模式最广泛的集合。
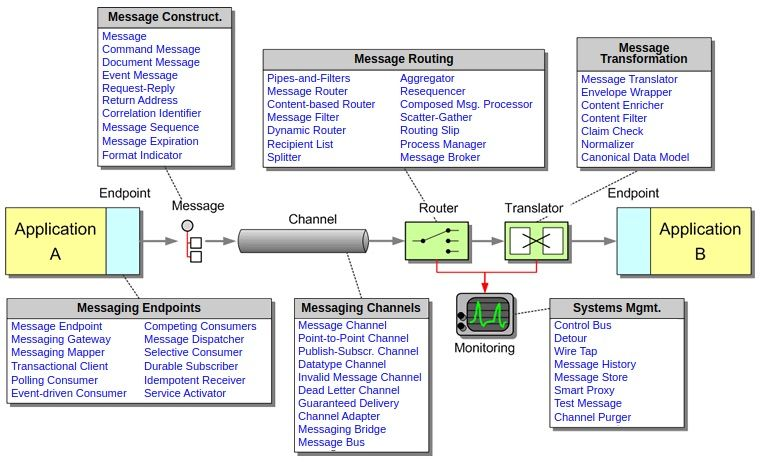
我撰写本文的目的是在 AWS 云环境中按照无服务器的方式实现管道(Pipe)和过滤器(Filter)模式。我将会讨论一些可供选择的实现方式以及它们各自的优势和劣势。在实现过程中,可重用性是我要考虑的一个具体的方面。
无服务器架构的管道和过滤器模式
在敏捷编程中,以及对微服务友好的环境中,设计和编码的方式已经与单体时代不同了。敏捷和微服务开发者不再把所有的逻辑放到一个功能单元中,而是倾向于更加细粒度的服务和任务,遵循单一职责原则(single responsibility principle,SRP)。有了这一点,开发人员就可以将复杂的功能分解成一系列可独立管理的任务。每个任务会从客户端获取一些输入,然后消费这些输入以执行其特定的职责,并生成一些输出,这些输出会转移到下一个任务中。根据这一原则,多个任务构成了一个任务链。每个任务都将输入数据转换成所需的输出,而这些输出又会作为下一个任务的输入。这些转换器(transformer)传统上被称为过滤器,而将数据从一个过滤器传递到另一个过滤器的连接器(connector)被称为管道。
管道和过滤器一个非常常见的用法是这样的:当客户端的请求到达服务器的时候,请求载荷必须要经历一个过滤和认证的过程。当请求被处理的时候,可能会有新的流量进来,在执行业务逻辑之前,系统必须要执行一些通用的任务,比如解密、认证、校验并从请求载荷中移除重复的消息或事件。
另外一个场景就是在电子商务应用中将商品添加到购物车的过程。在这种情况下,任务链可能会包含如下的任务:检查商品的可用性、计算价格、添加折扣、更新购物车总数等。对于其中的每个步骤,我们都可以编写一个过滤器,然后使用管道将它们全部连接起来。
实现这种模式最简单的方式就是使用 lambda 函数。我们知道,有两种调用 AWS 服务的方式,也就是同步方式或异步方式。在同步场景中,lambda 运行函数并等待,直到发起调用的 lambda 接收到被调用 lambda 的响应为止,而在异步的情况中,不需要等待。AWS 支持回调方法和 future 对象来异步接收响应。在这里,管道的角色就由内部网络来扮演。

在这种直接的 lambda 到 lambda 的调用中,不管是同步还是异步,都有可能出现节流的情况。当请求的流入速度超过了函数的扩展能力,并且函数已经到了最大的并发水平(默认是 1000),或者 lambda 的实例数量达到了配置的预留并发限制,所有额外的请求都会因为节流错误(状态码为 429)而失败。为了处理这种情况,我们需要在两个 lambda 之间添加一些中间存储,这样能够临时存储无法立即处理的请求并实现针对被节流消息的重试机制,一旦有 lambda 实例可用,它就会获取这些消息并开始对其进行处理。
我们可以通过使用 AWS 的简单队列服务(Simple Queue Service,SQS)来实现这一点,如下图所示。每个 lambda 过滤器处理一个事件并将其推送到队列中。在这种设计中,Lambda 可以从 SQS 轮询多个事件,并作为一个批次进行处理,这也可以提高性能和降低成本。

这种方式可以减少节流的风险,但是并不能完全避免。这里有一些可配置的参数,我们可以使用它们来平衡节流。除此之外,我们还可以为 lambda 实现一个死信队列(Dead Letter Queue,DLQ)来处理被节流的事件 / 消息,并能够防止这些消息丢失。有一篇很好的文章题为“在数据项目中组合使用 SQS 和 Lambda 的经验教训”,读者可以通过它来了解解决该问题的关键参数。
在下一节中,我将会构建一个通用的、可重用的解决方案,该方案会用到另外一个适用于无服务器事件处理的 AWS 组件,即 Amazon EventBridge,我会实现管道和过滤器设计模式。
在无服务器架构中实现管道和过滤器模式
Amazon EventBridge 是一个无服务器事件总线,它可以利用从你的应用程序、集成的软件即服务(SaaS)应用程序和 AWS 服务中产生的事件,从而能够更容易地构建大规模的事件驱动应用。
在了解它如何运行之前,我们需要理解一些与 AWS EventBridge 相关的术语。
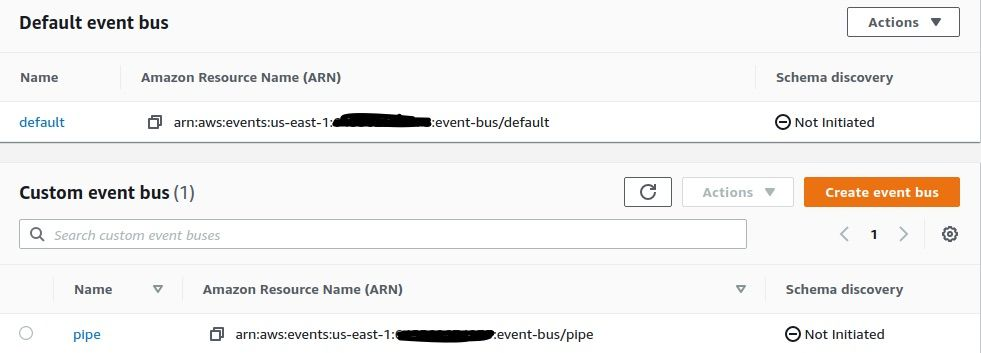
事件总线是 EventBridge 的关键组件之一。事件总线接收来自不同源的事件 / 消息,并将它们与一组定义的规则相匹配。EventBridge 有一个默认的事件总线,但用户也可以创建自己的事件总线。在这个 POC 中,我创建了一个名为“pipe”的事件总线。
规则(Rule)必须要与特定事件总线关联。在这个 POC 中,我为三个不同的过滤器创建了三个规则,如下图所示。
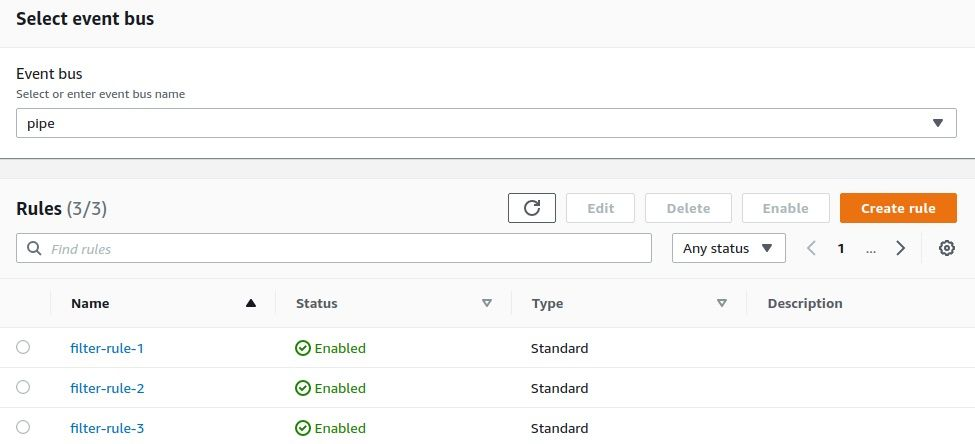
对于每个规则来讲,事件模式和目标是两个非常基本的配置。
事件模式是一个条件。它与自己所匹配的事件具有相同的结构。如果传入的事件具有相匹配的模式,那么规则就会被激活,并将传入的事件传递给目标(目的地)。目标是一个资源或端点,EventBridge 能够将事件发送给它。对于特定的模式,我们可以设置多个目标。
在我们的例子中,我将 lambda 名设置为模式中的detail.target,一旦 lambda 名称匹配,目标 lambda 就会被触发。
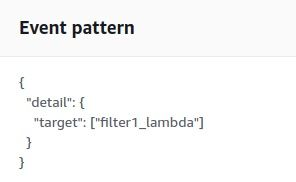
注意:detail.target是一个 json 字段。目标是事件的一个可配置的端点 / 目的地。
在事件流中,可以执行的不同步骤如下所示:
源生成一个事件(它必须遵循事件源生成器和 event bridge 规则创建者所定义的模式)。
为了测试我们的实现,我使用了如下的事件:
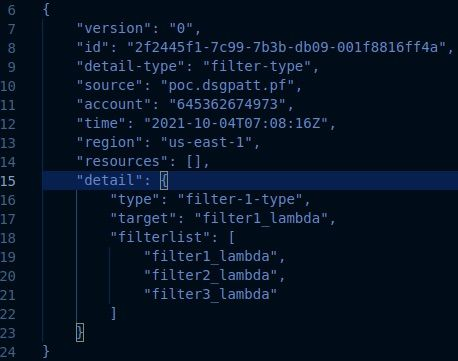
基于测试事件的具体detail.target 值,会有一个规则匹配并执行。在我们的场景中,这将会导致事件 / 消息会路由到与规则关联的目标 lambda 上,即filter1_lambda。
目标 lambda 完成其任务,并将事件目标(detail.target)替换为detail.filterlist json 列表中的下一个 lambda,也就是filter2_lambda。
目标 lambda 随后调用 lambda 层的工具函数next_filter()。
next_filter() 函数负责构建最终的事件并将其放到 event bridge 中。
基于新的目标值(即filter2_lambda),另外一条规则能够被匹配,从而会调用一个单独的过滤器 lambda。
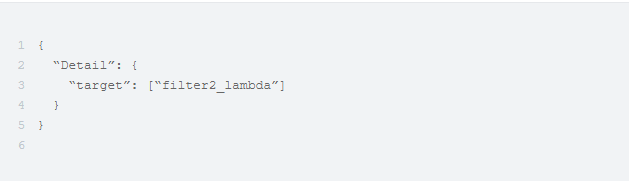
在完成所有的任务之后,终端过滤器会将消息发送给下一个非过滤器的目的地。在本 POC 中,终端过滤器是filter3_lambda。这个 lambda 不再调用next_filter函数,而是调用 DynamoDb API,将数据保存到 DynamoDb 的表中。
正如我们所看到的,借助 EventBridge 的模式匹配路由功能,我们可以用单一的事件总线来实现管道和过滤器模式,即便链中的某个后继阶段依然在忙于处理前一个事件,链中的其他阶段都可以自由地开始处理下一个事件,从而提高整体效率。
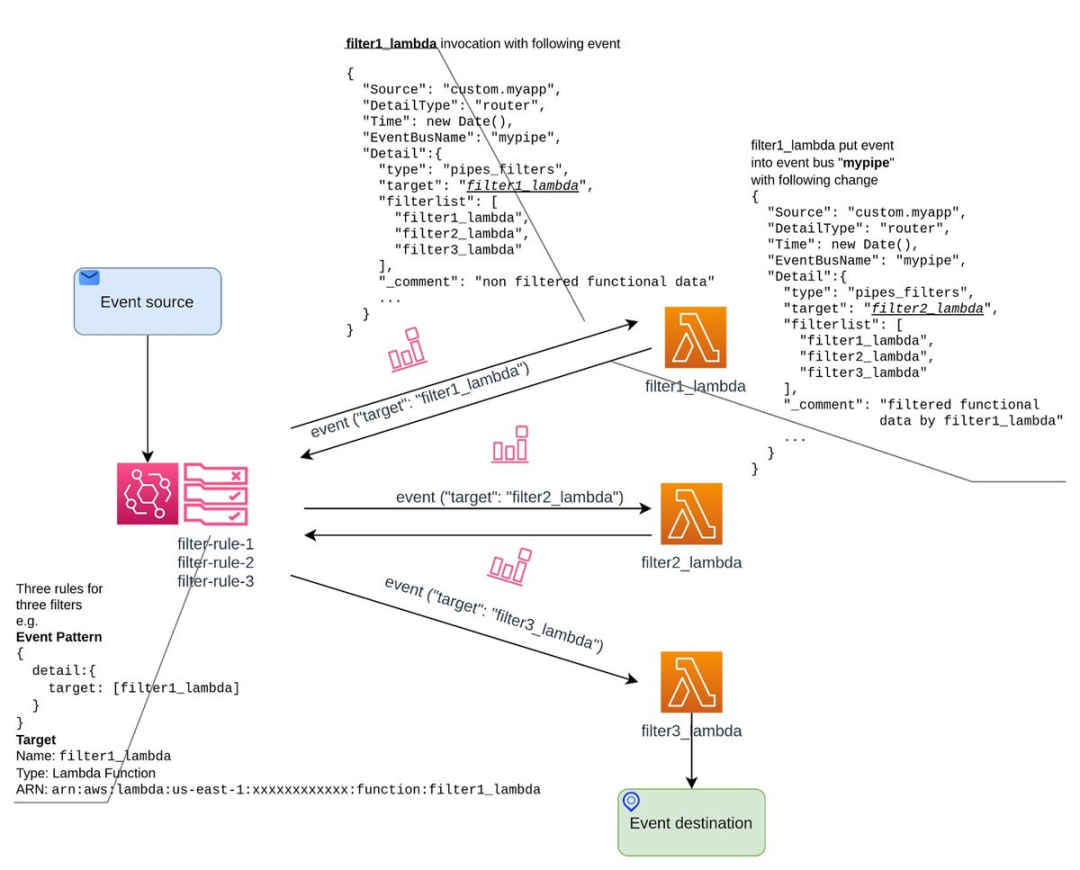
如上图所示,事件最初会到filter1_lambda中,因为客户端事件的detail.target属性与目标为 filter1_lambda 的filter-rule1事件模式相匹配。执行完成后,filter1_lambda 将事件的detail.target设置为下一个lambda,即filter2_lambda,并将修改后的事件发回给事件总线。由于 detail.target 的值是filter2_lambda,所以 filter-rule2就会被触发,如此反复。通过这个递归过程,所有的过滤器都会被执行。最后一个过滤器可以调用一些其他资源,而非调用next_filter() 工具层。
在上面的实现中,每个 lambda 共同的重要任务之一就是将事件目标(detail.target)修改成 filterlist中的下一个 lambda。为了完成这个任务,我们使用了 lambda 层(lambda layer)。
lambda 层是 lambda 的一个特性,它可以帮助开发者从 lambda 代码中提取通用功能或库,并将其放入一个层中。这个层可以作为一个工具式的代码块,实际的 lambda 代码可以在这个层上面执行。Lambda 可以根据需要重用该层的通用功能和 / 或库。AWS 文档这样说:
Lambda 层是一个包含额外代码的归档文件,如库、依赖,甚至是自定义运行时。
对于这个 POC 来讲,我写了一个工具层,它导出了 next_filter 函数。Lambda 过滤器使用这个函数从 filterlist 中推断出下一个过滤器的名字。相关的代码片段在本文末尾的附录中给出。

整个 POC 代码以及 AWS 云开发工具包(AWS Cloud Development Kit,CDK)的基础设施代码可以在 github 仓库中找到。
总 结
模式是软件设计领域中最有用、最有效的工具之一。为了以标准的方式解决常见的设计问题,我们可以使用合适的设计模式。模式就像一个设计插件。在技术方面,无服务器是一个快速增长的领域,所有的云计算供应商都在定期推出新托管的无服务器服务。因此,要决定一个合适的无服务器管理服务的技术栈是很困难的。在这篇文章中,我讨论了如何使用不同的 AWS 无服务器托管服务,以无服务器的方式完成一种设计模式的不同实现方法。
附 录
next_filter的代码片段:
module.exports.next_filter = (async function (event) {
var i = event.detail.filterlist.indexOf(event.detail.target);
if (event.detail.filterlist.length === i + 1) {
return null;
} else {
event.detail.target = event.detail.filterlist[i + 1];
var finalEvent = {
“Source”: event.source,
“EventBusName”: “mypipe”,
“DetailType”: event[“detail-type”],
“Time”: new Date(),
“Detail”: JSON.stringify(event.detail, null, 2)
}
var Entries = [];
Entries.push(finalEvent);
var entry = { "Entries": Entries };
var result = await eventbridge.putEvents(entry).promise();
return result;
}
});
参考资料
Lambda SQS 扩展
(https://aws.amazon.com/cn/premiumsupport/knowledge-center/lambda-sqs-scaling/)
SQS 消息的短轮询和长轮询
(https://docs.aws.amazon.com/AWSSimpleQueueService/latest/SQSDeveloperGuide/sqs-short-and-long-polling.html#sqs-long-polling)
节流
(https://docs.aws.amazon.com/lambda/latest/operatorguide/throttling.html)
在数据项目中组合使用 SQS 和 Lambda 的经验教训
(https://data.solita.fi/lessons-learned-from-combining-sqs-and-lambda-in-a-data-project/)
作者简介:
Tridib Bolar 在印度加尔各答工作,是一家 IT 公司的云计算解决方案架构师。他已经在编程领域工作了 18 年以上。他主要从事 AWS 平台相关的工作,同时也在探索 GCP。除了是云计算无服务器模式的支持者之外,他也是物联网技术的爱好者。
原文链接:
https://www.infoq.com/articles/design-patterns-for-serverless-systems/
相关文章推荐
发表评论
关于作者

- 被阅读数
- 被赞数
- 被收藏数
登录后可评论,请前往 登录 或 注册