【技术加油站】揭秘百度智能测试规模化落地
作者:技术小猪AI2022.03.16 18:53浏览量:616简介:揭秘百度智能测试规模化落地
摘要:上一篇《【技术加油站】浅谈百度智能测试的三个阶段》,介绍了百度智能测试三阶段,本篇我们提出以挖掘场景为驱动的方式有序推进智能测试三阶段分节奏的规模化落地。
场景从何而来,是我们首先就要面临的问题,为此还是从测试活动本质去寻找答案。测试活动其实大概可以分为测试输入、测试执行、测试分析、测试定位和测试评估五个步骤。这五步测试活动目标是不一样的,因此不能笼统对整体测试活动进行智能化,容易造成目标混乱,影响落地开展。
我们开展的思路是:某服务的某项测试中的某个测试活动为一个场景为试点,从而形成点线面体的推进方式。如下图所示:
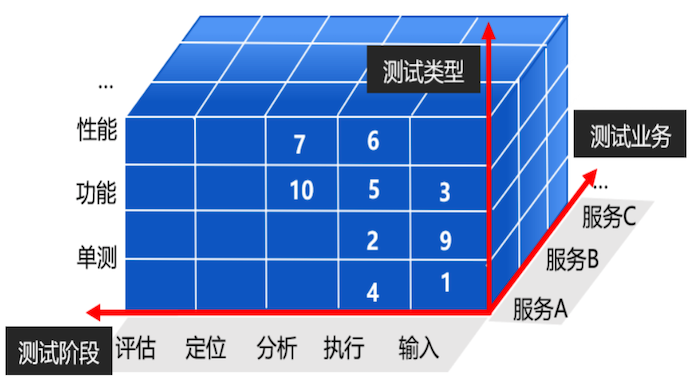
01.测试输入阶段中的智能化探索
测试输入:找出覆盖足够全、准确的测试行为、数据集合和构建真实的环境,以去覆盖更多的测试场景和更高的代码覆盖,该阶段决定测试活动发现问题能力上限。在传统测试方式中,测试输入的选择很大程度上依赖经验和历史case。
在智能化测试的探索中,通过智能异常单测用例生成、海量query寻找最合理的query、页面遍历推荐动作集、fuzz函数或接口的入参等手段,可以进一步完善测试输入,提升测试阶段召回能力。
如测试流量扩流与初筛场景中,通过扩大流量覆盖面,扩大的测试输入范围的同时,通过特征分桶,覆盖率插桩等手段,剔除无效特征数据以及特征去重来实现流量初筛。针对异常场景,基于控制流图,数据建模等思想,针对值类型与路径频率等通过变异策略生成异常用例。在保证测试输入完备性与执行效率的同时,提高测试的覆盖率。
02.测试执行阶段中的智能化探索
测试执行阶段:结合测试输入集合以及变更详情,以较小的代价,在不降低发现问题能力的前提下有效执行完该执行的质量活动,本质上是效率问题。
传统做法是:将所有确定的测试用例不做筛选优化、对测试过程不做精简全量执行,往往存在用例冗余度高、长尾用例分组异常,最终导致测试执行效率低、资源消耗大;
而智能测试下的做法是: 对测试集合进行精选、相似度去重、分组均衡、资源调度来智能执行测试过程,进而极大的提升测试执行效率,降低成本;在该阶段, 我们通过静态评估(静态扫描用例内容)、动态评估(执行用例并结合过程与结果的状态来判断用例质量)、变异测试(注入源代码异常算子,检测用例是否有效)、Flaky监测(检出与剔除源代码不相关的用例)等手段来确定所有该执行的用例,通过智能取消、跳过、裁剪、排序、组合等策略来保障该执行的用例能在最短时间内有效执行完成。
03.测试分析阶段中的智能化探索
测试分析阶段是将测试执行的结果进行系统整体的分析判断,确认测试执行的结果是否有问题,尽可能高准召的分析暴露问题,本质上是质量问题,即将测试输入阶段该召回的问题披露出来。
传统的做法是有经验的测试专家,来制定各测试任务是否有问题的标准,包括不限于特定指标是否存在;特定指标的大小和对比;阈值设定等,这种做法比较依赖人的判断能力,随着系统和环境的变化导致抗干扰能力不足。
智能场景是通过测试执行任务的历史表现,智能化进行决策分析,判断测试执行结果是否有问题。
例如1、数据测试中可使用历史数据的指数平滑计算方法,计算数据大小,行数和内容的合理波动范围,进而在下次测试任务执行时,智能自动判断任务结果是否有问题。
2、业务指标测试场景中,各指标的阈值波动范围,也可以通过借鉴线上的波动范围以及历史测试任务的数据,通过智能计算的方式自动化的产出合理波动范围。
3、通过视觉技术分析前端用例执行过程中,截图内容是否有问题,而不用担心人工判断导致的漏出;
4、通过DTW曲线拟合算法判断内存泄露是否存在,而不是传统的阈值方法。
04.测试定位阶段中的智能化探索
测试定位,主要是快速判断导致测试活动“失败”原因,以快速修复,本质上是个效率问题。测试活动中经常会遇到执行失败的情况,常规情况下经常要去排查工具、环境、代码等情况来判断活动失败的原因,最终决策是否进行对应行为,在智能化的探索中,我们希望通过智能定位快速找到测试任务失败的归因,第一步可以找到工具/环境问题来判断是否要进行重新构建或自愈;第二步可以找到代码导致的失败,以协助研发快速定位问题快速修复提升效率。
在该过程中,我们探索了基于决策树的测试失败智能定位,实现了工具失败自动rebuild和自愈。在监控领域,我们利用变更墙、线上系统关系知识图谱实现监控问题的范围定位,以协助研发或运维快速做出止损动作。
05.测试分析阶段中的智能化探索
测试评估,是测试活动最容易忽视的阶段,从业者经常因为某测试任务红/绿灯来判断测试是否通过;而测试评估是结合测试执行和系统变更,整体评估待实施或实施过测试活动的系统风险,以进一步指导我们是否要测试活动,本质上是个质量问题。
测试评估,首先是由历史数据形成风险判断的范式,然后用来评估新项目的风险。形成范式的阶段,我们探索了基于测试全流程数据的质量度模型,需要选取合适的风险因素,建立数据采集和变化感知的体系,采集数据并转化为特征,利用机器学习训练大量真实数据,对特征进行定性(一个因素对风险是正向还是负向)和定量(对风险的影响有多大)分析,得出风险预估模型,将人工的经验转化为客观的判断。项目使用阶段,由于已经建立了数据感知系统,新数据可以直接输入到模型,得到即时的风险结论和特征对风险的影响情况,让质量可见。落地积累的项目数据又能反哺模型,形成有效闭环。
在项目待实施测试活动时,我们先进行一次测试评估,即可决定项目是否需要测、辅助判断如何测。采取了对应的质量活动后,再做一次风险评估,以进一步检验测试结果,发现风险。如此,测试决策将变得更有效、更可积累、更可持续。
相关文章推荐
发表评论
关于作者

- 被阅读数
- 被赞数
- 被收藏数
登录后可评论,请前往 登录 或 注册