GPU云产品体系介绍和应用场景分享
2022.03.25 17:32浏览量:804简介:GPU云产品体系介绍和应用场景分享
百度智能云异构计算产品经理:玄凌博
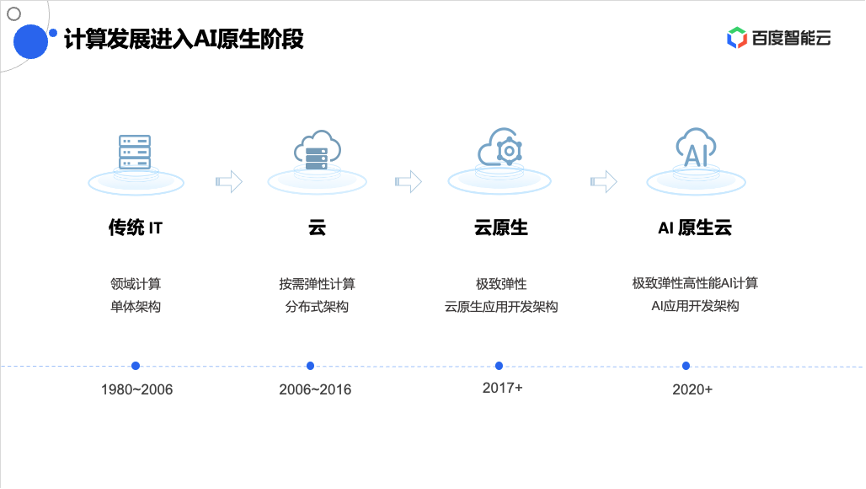
由于今天主要围绕算力维度进行讨论,所以首先回顾下企业在计算方面的发展。按照时间维度,企业有四个典型的计算发展阶段:
1、2006年以前,大多数企业仍是以传统物理机为主的单体IT架构;
2、2006年以后,随着企业上云的大趋势,迎来了云计算的时代,并随着云服务器、弹性裸金属等产品的爆发,能够弹性按需的满足企业对IT资源的使用诉求;
3、2017年以后,随着云原生技术的成熟,像容器、微服务等技术不断的商业化落地,能够为企业提供极致弹性,云原生应用的开发架构;
4、2020年以后,随着人工智能技术不断的爆发及增长,现在正迎来一个AI原生云的阶段。企业需要极强的AI算力,来满足各个 AI应用相关的开发及训练。在这个时代,云服务器厂商需要提供极致弹性且高性能AI算力,是适用于AI应用开发的云架构。
为了更好的解决人工智能计算的并发问题,通常会使用适用于计算密集且易于并行计算的GPU。
随着计算架构的不断发展,异构计算加速器通常会包含多种计算核心,来更有效率的加速特殊数据格式的计算。以NVIDIA GPU为例,通常CUDA Core是面向通用计算的计算核,能够计算几乎所有的数据格式。RT Core则是面向渲染里做光线追踪的加速单元,而Tensor Core则是面向人工智能或深度学习里做矩阵向量乘加的核心。近年来,很多国产的AI芯片也采取了类似的思路和策略,例如昆仑芯,包含拥有大量的面向矩阵做加速的处理单元。
异构计算是AI原生时代重要的算力底座。百度内部拥有大量的AI应用场景,多年的AI算力建设经验和技术积累,通过百度智能云对外提供的异构计算云服务,能够赋能千行百业。

云上的异构计算服务主要分为两种:一种是以BCC异构计算云服务器的形态,提供极致弹性、灵活、高性价比的算力规格。而搭配BBC异构计算的弹性裸金属服务器,能够做到算力的零虚拟化损失、百分百服务于客户业务,提供极高性能的算力,且满足部分客户对安全隔离性的要求。
回到异构加速卡,百度智能云支持丰富的异构加速卡的型号,支持英伟达最新的安培架构计算卡,也提供自研的加速芯片昆仑芯。在高性能的异构计算上,用户可以在分钟级创建以往可能花费需要数月来构建的InfiniBand集群环境。
在产品命名上,主力产品的实例规格族和异构卡类型是一一对应的,比如GN5通常会支持英伟达安培架构的卡,GN3会支持上一代的架构,像V100、T4等。在实例规格的搭配方面,实例根据GPU的一些物理规格,例如显存、SM等,经过了合理CPU、内存配比。针对部分的异构计算卡也提供了像vGPU的实例,能够提供更具性价比的计算算力和渲染算力服务。
在面向AI应用爆发的时代,异构计算产品也在不断打磨,推出新的产品特性。除了业界对云服务的一些通用要求,像运维及弹性按需之外,百度智能云也深耕GPU虚拟化技术,通过透传、GPU分片以及多容器共享等技术,能够更好的提高客户对资源的利用率。在硬件层面上,也是百度智能云投入的重点,陆续推出了自研的AI芯片、AI架构服务器,即X-MAN,以及云上高性能的网络组网方式,目的是能够不断提高AI全栈的负载计算效率。
下面会围绕异构计算卡、服务器和网络几个方面介绍下百度智能云的产品能力。
不同GPU的型号都有不同的定位,面向计算的GPU,比如AI推理、训练或者HPC的型号,通常会在双精度浮点FP64以及半精度FP 16上做一些特殊的加强。有些gpu则会支持更多的应用场景,例如A10,有更多的CUDA Core和RT Core,在渲染场景也有很好的性能,提供更强的单精度算力。
除了计算单元,显存也是一个很重要的参数。A100 和A30都是支持HBM的。对于一些访问密集型的计算,HBM显存会有更强的性能表现。此外一点是GPU的P2P能力,PCle这一代在双向带宽上可以做到64GB,而支持NVLink的计算卡,比如A100、V100,能够在 GPU P2P上有进一步的能力提升,像最新的NVLink 3.0,可以做到双向600GB的量级。

除了英伟达的卡,昆仑芯也来迎来了第二代。第二代的昆仑芯在性能上都有了全方位、大幅度的提升,比如在通用性以及各个规格的算力,工艺也从13纳米到了7纳米。除了性能的提升,也集成了ARM核,可以更好的适用于一些边缘计算场景。此外,也考虑到了分布式的典型AI应用场景,昆仑芯也可以支持K-Link这种高速P2P能力。如果客户在云上突然对虚拟化有一些诉求,昆仑芯可以在物理上支持虚拟化。在软件的适配性上,提供了更友好的开发环境,支持C和C++编程。
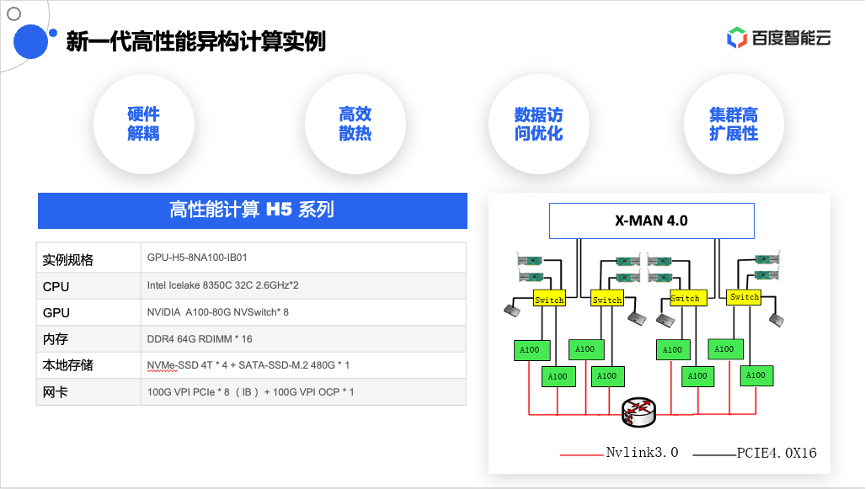
本次讲解的重点话题是云上的高性能计算集群,以往企业搭建一套高性能计算集群,需要投入极高的人力成本和数月的时间成本。而大部分客户使用高性能计算,追求的是极高的业务时效性。使用百度智能云可以分钟级获取到一套高性能的异构计算实例,也就是利用最新发布的高性能H5系列,来组建高性能集群,这套实体也是基于X-MAN架构来对外提供服务。
在计算效率上,数据的访问效率及通信效率都进行了硬件层面的升级与增强;在配置上,标配了业界最高规格的配置,比如英特尔铂金系列CPU,全闪存的本地盘,还有和GPU 1:1配比的InfiniBand网卡;I/O设备可以直连A 100 GPU,这样可以通过GDR、GDS加速GPU读取I/O设备的访问效率。
在集群分布式的AI训练中,往往会有一半的时间用于GPU节点之间做梯度交换,而在交换时则会造成计算资源的闲置或浪费,影响了整个模型的收敛效率。那RDMA的高性能网络,可以极大的降低节点之间的时延,而InfiniBand作为天然支持RDMA的通信协议,有极强的性能表现。InfiniBand对比传统TCP IP协议,对时延有极大的提升。
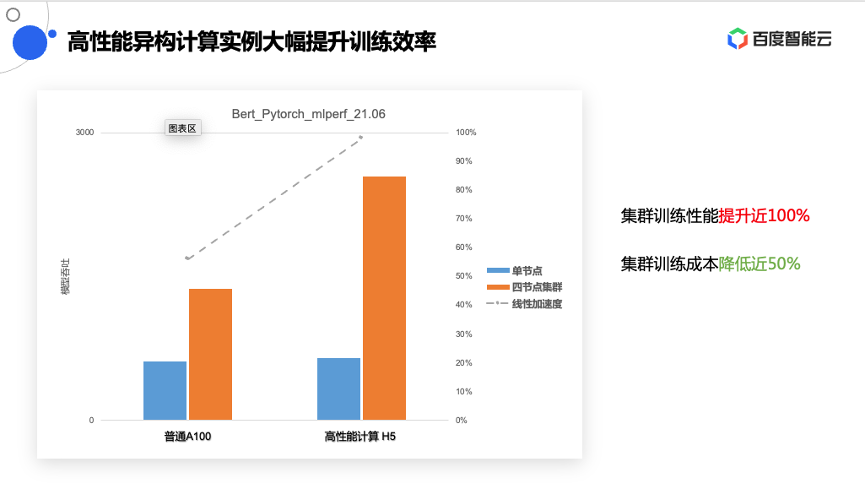
从实际模型的训练表现来看,以BERT的训练为例子,高性能计算 H5对比云上普通的A100,在单节点上差距并不明显,但在整个集群训练中,即便是4节点的小规模计算集群,高性能计算H5也可以带来近2倍的吞吐性能。更高的吞吐意味着模型收敛时间可以进一步降低,一个小时的训练任务可以缩短到接近半个小时,成本可以节约近50%。
那么如何更有效率的发挥硬件的性能?百度在去年推出了百度百舸·AI异构计算平台,除了高性能H5这些计算实例外,也推出了AI容器、AI存储,进一步能提高GPU工作效率和作业效率,像AI存储可以提供百万级IOPS和百万GB吞吐的能力,可以进一步的提高训练数据读取效率;AI容器则提供多种调度以及GPU增强能力,比如AI作业调度、集群管理能力,并且提供GPU容器虚拟共享。

发表评论
登录后可评论,请前往 登录 或 注册