超大规模AI异构计算集群的设计和优化
作者:技术蓝猫2022.03.25 17:33浏览量:1514简介:超大规模AI异构计算集群的设计和优化
百度智能云资深研发工程师:孙鹏
最近,业界有一个很大的趋势是训练规模越来越大的模型。从GPT-3开始,模型已经被推到了千亿参数量的维度。从2020年到现在,各个厂商也在不断推出更大参数量的模型,比如OpenAI的GPT-3、Google的Switch Transformer,百度去年也先后推出了多个大模型,像ERNIE 3.0 Titan,它是全球最大的中文单体模型。
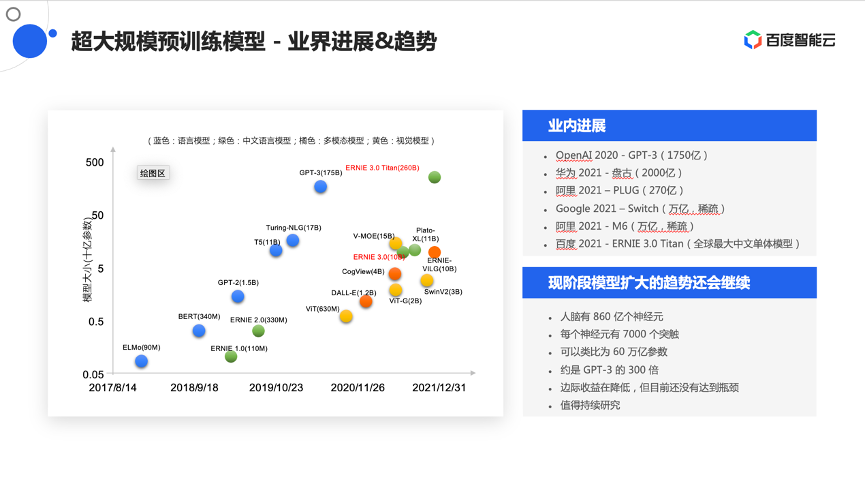
现阶段大模型还会成为一个逐渐演进趋势,比如可以类比人脑,通常认为人脑中有861亿个神经元,每个神经元大概有7000多个突触,近似的做一个类比或代换,大概有60万亿的参数规模,约是GPT-3模型参数量的300多倍。现在的模型规模离人脑的通用智能还有很大差距,这会是一个值得持续投入和研究的领域。
那大模型究竟是个什么样子?该怎么用它呢?文心大模型提供了一个线上试用的地址:https://wenxin.baidu.com/wenxin/ernie ,感兴趣的同学可以打开试一试。
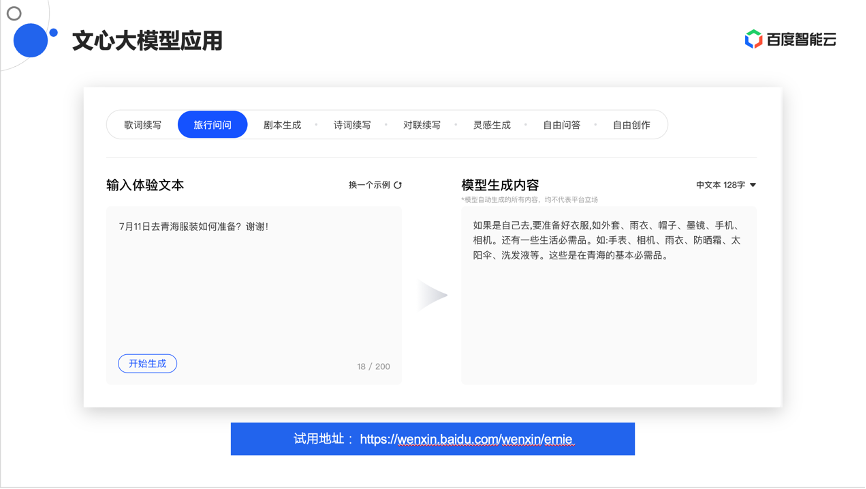
文心大模型可以在NLP领域支持多个任务,包括歌词续写、旅行问问、剧本生成、对联续写等。举个简单例子,输入文本“7月11日准备去青海,该准备怎么样的服装”,文心大模型会根据训练过的模型数据自动生成一段对话:“如果是自己去,要准备好衣服、雨衣、帽子、墨镜、手机、相机,还有一些生活必需品,如手表、相机、雨衣、防晒霜、太阳伞、洗发液等。这些是在青海的基本必需品。”,结果看起来比较符合真实场景,也比较符合人类智能,这就是用大模型的实际感受。
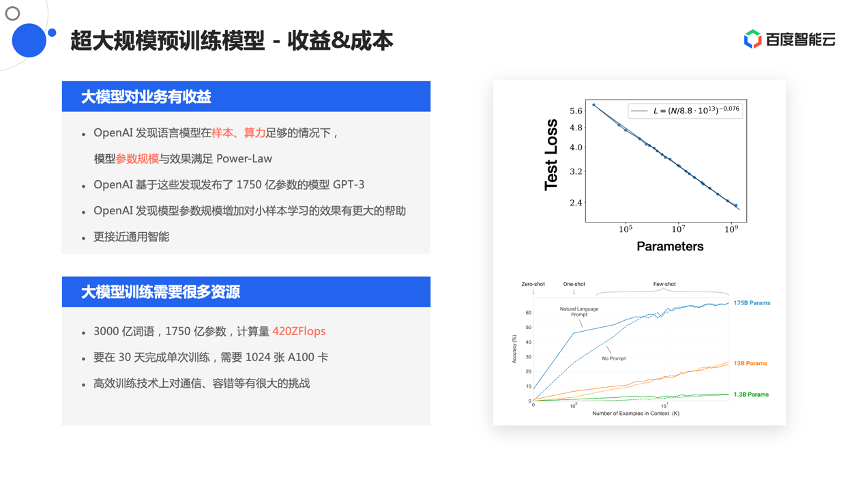
同时,大模型不仅业务效果好,而且对业务还会产生很多的收益,比如随着模型规模越来越大,业务训练过程中的损失会越来越低,而且呈Power-law的趋势。并随着参数规模的倍数增长,Test Loss会线性下降,这也带来了一个启发:可以用大模型的方式提升整体业务的训练效果,或整体业务在线上的效果。
除此之外,研究人员还发现大模型可以通过小样本在其他领域取得很好的效果,不需要像原来一样,对每个业务场景都重新训练一遍,而是先拿一个大参数的预训练模型,结合特定领域的小样本做finetune,可以很快完成业务的迭代。而从一定程度上也反映,它其实是一种更接近通用智能的方式。
虽然大模型有很多好处,但大模型训练会很难,那究竟多难呢?比如有3000亿条词语,需要1750亿的参数,这样的模型计算量大概是420ZFlops,其中1 ZFlops是1024 EFlops,1 EFlops又是1024 PFlops,这是一个非常大的数量级。也有论文分析,对于这么大的参数、这么多的样本,用1024张A100卡,也需要月级别才能完成训练,这对整个训练和技术架构的挑战都是非常大的。
百度智能云现在做的就是如何在大规模参数情况下完成高效稳定的持续训练。模型训练需要这么多的参数,也需要很多的计算资源,因此需要搭建一个集群来支撑整个训练。
有集群建设经验的同学可能知道,搭建一个集群并非易事,这个过程会有很多不同的选择,比如单机该如何选,训练卡是什么样,训练卡内部的互联方式是什么样,多机之间又应该如何架设网络保证它们之间能高效通信,网络规模又需要是什么样的,这些都是在集群建设中很关键的问题。
要解答这些问题,必须深入整个理解大模型训练的过程和模式。所以接下来会结合现在业界比较主流的几种大模型训练方式,对它进行展开和剖析,看看完整的训练一个大模型需要什么样的计算、通信和过程。
先来看下业界比较主流的混合并行的模式,混合并行是指什么?先来做一个简单的数学计算题,在当前的大模型下,假设以1000亿参数为例,每个参数需要占4个字节,是FP 32的数据类型,因此仅对于这个参数来说,就需要400G左右的存储空间。对比市面上最大的计算卡,一张卡可能只有80G,像NVIDIA A100,在400G到80G之间存在一个很大的gap,尤其是包含了其他的一些梯度等中间变量之外,gap会变得越来越明显,所以无法简单粗暴的像以前一样把一个模型塞到一张卡里,然后通过纵向扩展数据卡来提升训练效率,而是一定要把模型做切分。
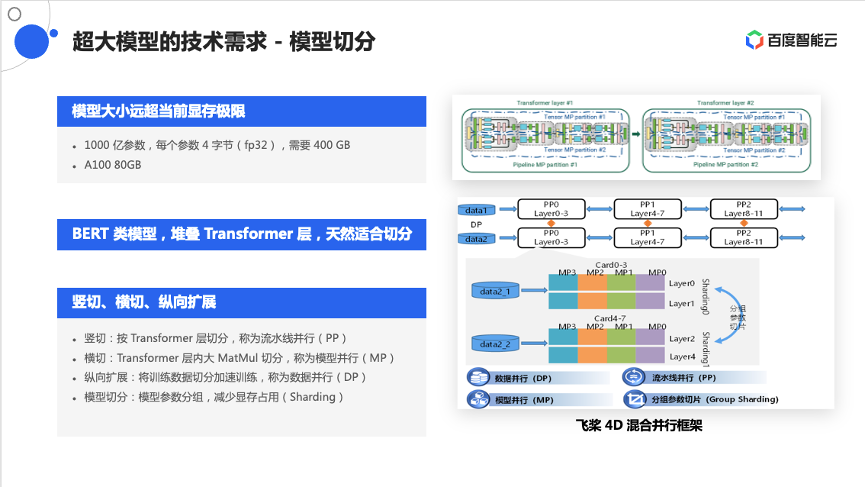
目前,大模型通常都是BERT类模型,BERT类模型的特点是不断的堆叠Transformer层,这种堆叠天然的带来一些切分的策略和方式。业界通常有几种切分策略,如BERT模型中的两个Transformer层,这两个Transformer层之间会有前后的依赖关系,即在第一层计算完之后,把计算结果传送到第二层再开始计算,这就带来了一种切分的可能性,就是按层切分,把这种每层切分的方式叫做流水线并行,因为层与层之间可以认为是流水线的过程,先把第一层计算完,然后再流水的计算第二层。
除此之外,再观察每一层内部,在大模型的环境下,MatMul参数会特别大,导致其中的矩阵张量都会很大,在一张卡上计算会比较慢,那如何加速这个过程呢?可以把模型中的张量一分为二,一部分卡负责其中的一部分计算,它们之间的额外代价需要进行一些通信操作,这种切分由于是把一个张量一分为二,所以这种切分策略通常称为张量切分或模型并行。
有了这样的切分方式之后,模型基本可以做一个完整的训练。由于样本比较多,这时训练效率会比较低,可以通过传统的数据并行方式,不断的堆叠这些层做数据训练的加速,这就是纵向扩展方式,也是大家比较熟悉的数据并行方式。
因为显存占用还是比较紧张的,还有一些减少显存占用的策略和方式,大家比较熟悉的是Sharding方式。这些混合策略整合起来,会形成混合并行的策略,像百度飞桨提出的4D混合并行策略就是将这几种运行策略做了组合。这个是第一种大模型训练方式,即混合并行的模式。
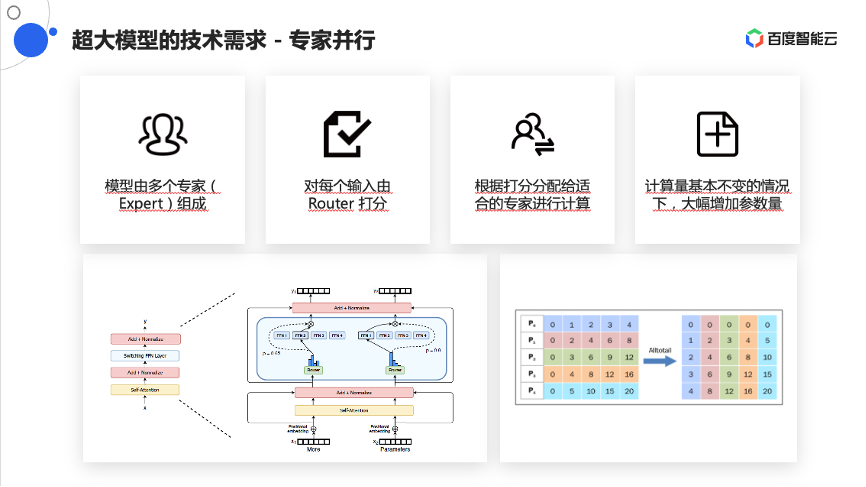
业界还有另外一种训练方法,称为混合专家模式,或专家并行模式。专家并行模式是原来一个模型由一张卡的一部分做计算,但由于模型参数很大,所以需要把它打散到不同的卡上。现在对一些层面压缩模型的大小,让每一个卡或每一个专家只负责处理其中的一部分参数,然后只需要横向扩展不同的专家个数,就可以达到参数上的成倍或者线性的扩展。好处是可以在计算量基本不变的情况下,大幅增加模型的参数量,从而在更低廉的规模集群上完成训练,但这个训练同样也会带来一些通信能力上的要求。举个例子,原来每一个专家可能分别会有自己的一些数据,但是现在要把这些数据分发给不同的专家,所以会做一个给所有人发送数据的操作,即是All2All的操作。这个操作对整个集群的网络压力或网络要求非常高,这就是常见的专家并行模式。
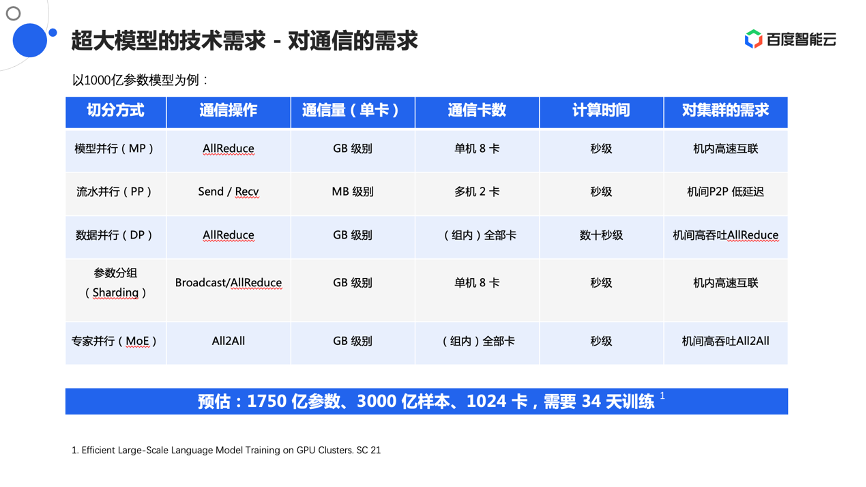
在百度内部我们对整个训练的模式做了更细微的观察,以及更量化的计算。如果以1000亿参数的模型为例,对于不同的切分模式、切分策略,在通信的卡数、通信量上以及在通信过程中做计算时间都会有不同的差异,这就能整体推导出对集群需求会不一样。比如流水线并行,一般会把不同流水线的层放到不同机器上,机器之间需要互相传递最后一层的激活以及反向梯度,这通常是一个标准的Send/Recv操作,而这个数据量大概在MB级别。这种并行模式对集群的要求是机间的P2P带宽延迟要非常低,从而尽量减少对整个模型训练的阻塞。
大家比较常见的数据并行模式,同样也会把它分成不同的组,然后组内全部卡都要做数据并行的AllReduce操作。虽然看起来数据通信量很大,但是留给它的计算时间相对的充裕一些,不过整体上来看,仍然要求很高的机间高吞吐AllReduce操作。
最后一个是专家并行模式或者混合专家模式,它要做全卡之间的All2All操作,每张卡在往外发数据的同时,每张卡还要做收数据,这对整个集群要求非常高,尤其是对网络上的吞吐和整体网络的交换能力,这个也导出了要求机间高吞吐All2All的需求。
结合论文来看,还有一个隐式的需求,比如在英伟达在《Efficient Large-Scale Language Model Training on GPU Clusters》论文中预估过:1750亿参数的模型,在3000亿样本的规模下,即使是1024卡,也需要训练34天。维护过集群或做过分布式学习的同学可能都会知道,这么多卡在这么长时间之内不出现故障基本是不可能的,那如何保证在有故障发生的情况下,模型能持续稳定的训练,也是亟需解决的问题。
总之,为了训练一个完整的大模型,要建设一个机内高速通信、机间有低延迟高吞吐能力,同时支持大规模算力的集群,还要保证它能持续稳定的月级别训练。

百度智能云推出的百度百舸·AI异构计算平台,就是基于这样的AI工程能力构建的解决方案。
百度百舸·AI异构计算平台在底层使用了超级AI计算机X-MAN,也基于InfiniBand做了一个大规模网络的建设,同时还配合上自己的高性能存储,解决了数据I/O的问题。在这之上,还给AI容器做了一些优化,比如有高效的AI作业调度、AI加速引擎,再配合上PaddlePaddle框架、TensorFlow框架、PyTorch框架,可以很方便的给开发者提供高性能、高效率且稳定的大规模模型训练的平台和场景。
首先,从单机层面看,单机用的是X-MAN 4.0超高性能计算机。这款计算机上搭载了8块 NVIDIA A100 80GB GPU,共提供640G显存,因为需要卡与卡之间的高性能通信,所以启用了NVSwitch,保证机内带宽能做到134GB每秒。同时,为了能保证机间能做高性能的互联,最终选择了8×200G的网卡,接下来会用IB网络做互联。这台机器的效果怎样呢?在最近发布的MLPerf 1.1单机训练A100 80G规格中,做到了全球TOP 2。
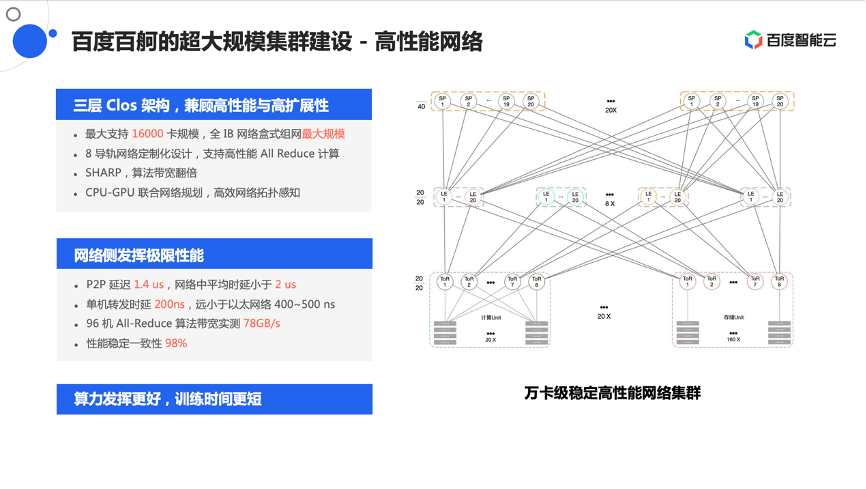
再来看下集群,集群上关注的是规模如何以及集群互联方式是什么样的。这里选用了一个面向大模型优化过的三层Clos架构,分别是Tor层、Leaf层、Spine层,它最大能支持到16000卡的超大规模集群,这个规模是现阶段全IB网络盒式组网的最大规模。
上面提到在计算过程中会频繁做AllReduce操作,甚至会做All2All操作。结合这些计算模式,尤其是针对AllReduce需求,做了一个8导轨网络的定制优化,即在同号卡尽量减少跨网络的跳步数,从而增加网络的稳定性,以及减少对整体网络的冲击。此外还充分使能了IB网络中的Sharp能力,整体支撑集群的稳定和持续训练。
在网络架构上,结合CPU、 GPU做了联合网络规划,从而高效的提供网络拓扑感知能力。那这个集群的效果如何?在建完之后做实测,发现集群中的P2P延迟能做到1.4us左右,网络中平均时延小于2us。单机转发延时小于200ns,远低于以太网络的400~500ns。在96机All-Reduce算法带宽实测为78GB每秒。同时,为了保证作业能稳定的训练,还特意测试了性能稳定性,性能稳定一致性能做到98%的水平,也就是接近一个一直在稳定通信的状态。有了这样的集群就可以让算力发挥的更好,从而让训练时间变得更短。

即使集群搭建好了,但上面的所有软件或模型也不可能一直安全的运行下去。除了硬件之外,还要在软件层面做一些软硬结合的联合优化。百度有8年多的万卡规模EFlops算力最佳实践的能力和积累,然后把这些最佳实践统统用到了自研的平台上,下面介绍几个比较有特色的:
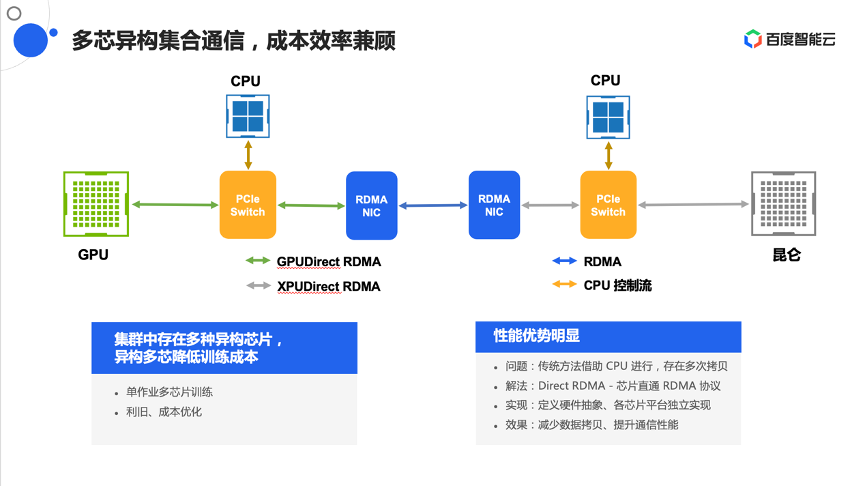
首先是自研的异构集合通信库ECCL。由于内部有很多不同代的GPU,还有昆仑芯等不同的异构芯片,如何把所有的芯片都高效使能起来,是要解决的一个关键问题。同时,在大规模上还需要解决一些拓扑探测、拓扑感知的问题,所以也把它放在通信库中。
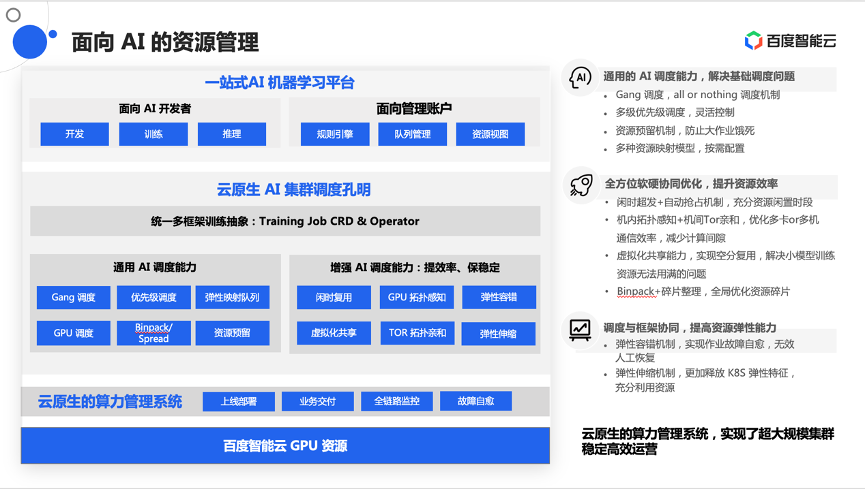
在此有这么多资源,还需要做一个比较好或比较科学的调度和管理,包括AI作业调度、硬件感知,及在训练过程中发现的故障节点和慢节点的感知,放到了集群资源管理层中。
百度自研的PaddlePaddle框架,提供了从框架到集群再到通信联合优化的可能性。

下面会为分享一些具体的case。先从通信来看,自研的异构集合通信库ECCL是为了解决现在集群中同时存在多类芯片,但集群中的容错能力有限,而且有一些慢节点业务感知不到,慢慢的拖慢了训练效率。为了解决这些问题,设计了一款自研高性能集合通信库,它首先是面向超大规模设计的,专门为这些弹性能力做了一些考虑。此外,还提供了一些拓扑探测、通信算法的高性能实现,加上刚才提到的在训练过程中很敏感的故障感知,提供了部分的自愈能力,这些都在大集群中做过验证。除此之外,还具备异构多芯的特点,能支持GPU和CPU之间、GPU和昆仑之间的高性能通信。总之,它就是为了加速卡与卡之间 AllReduce等级流动性操作而设计。
异构芯片通信通过联合GPU、昆仑团队,把传统需要通过CPU中转、CPU过滤转发进行通信的方式,通过 Direct RDMA的方式直接进行实现,这样可以有效减少数据拷贝的次数,提升通信性能。
IB网络中也有很多有意思的能力,比如做AllReduce操作时,为了保证网络吞吐尽可能发挥,会在算法层做一些AllReduce实现。AllReduce本身会进行两次操作,比如同一块数据要做两份,但会给集群带来的是数据要在整个网络和集群中进行两次。 IB有一个很有意思的特点叫Sharp,即把整个计算卸载到交换机中,对于用户来说,只需要把数据传给交换机,交换机就可以把AllReduce计算完的结果再反馈给我,整个过程能使数据通信的带宽降低、减半,也能使算法翻倍。同时,由于减少跳步之间的次数,可以让通信延迟更加稳定,这也是在大集群中跟英伟达联合使能的一个工作。
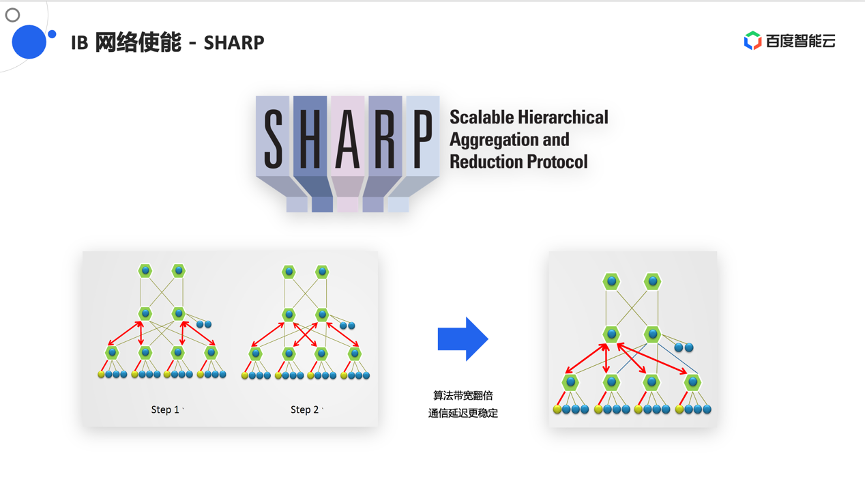
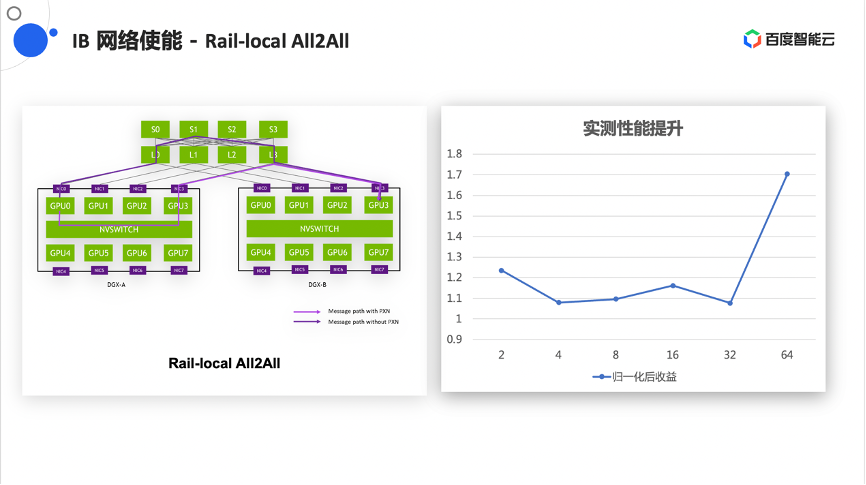
在大集群训练中会需要做All2All操作,这对网络中的需求或对整个网络的冲击都非常大,因为所有的节点都在同时的收发数据,在NCCL 2.12版本中也使能了一个新的功能,就是做Rail-local的All2All,即可以利用本机高性能的NVSwitch的一些通道,减少对网络的冲击。尤其是在8导轨设计下,能很好的减少网络中的流量。在使能英伟达的联合工作之后,本地也做了一些性能测试,在64机的情况下有70%的性能提升。
在集群资源的管理层面也做了很多工作,包括面向AI训练作业的特点,提供了一些Gang调度、优先级资源管理的能力。还结合硬件的特点,尤其是结合通信中提供的拓扑能力、组网能力,做了一些相关的拓扑感知,以及TOR亲和、TOR反亲和之类的调度策略,从而更好的支撑做训练。联合框架进行了一些弹性扩缩容,包括故障容错、慢节点巡检等,都是在集群调度层面去实现的。
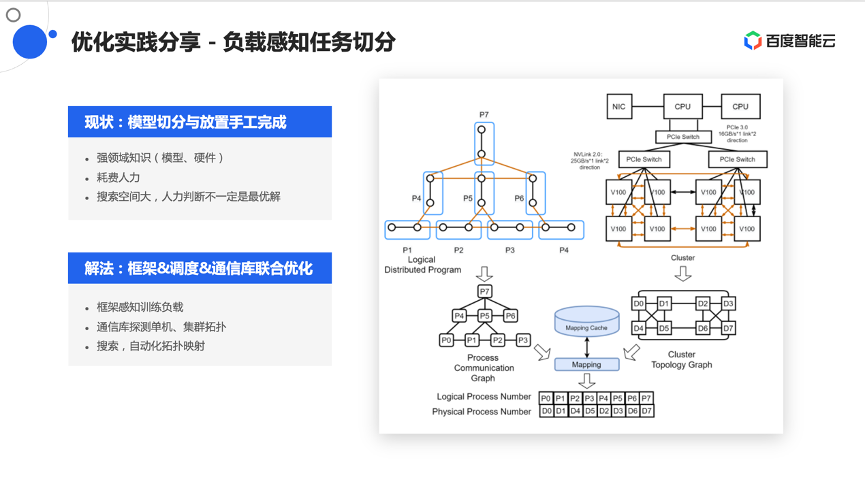
接下来分享下端到端自适应训练框架,众所周知,在训练过程中经常会发生故障,发生故障之后有几种做法,一种是做容错的替换,还有一种可以做弹性的扩缩容。无论是替换还是扩缩容,由于参与计算的节点所在位置发生了变化,它们之间的通信模式也许不是最优,也许可以通过作业重新排布、调度,在更好的放置来提升整体训练作业的效率。
这个过程中联合PaddlePaddle框架,整体提供了端到端自适应训练框架的能力。具体来说,当发生节点替换时,无论是因为容错还是节点扩缩容,都会重新做一个预跑,在小节点上去看这个模型需要什么样的计算方式和通信方式,然后结合集群拓扑探测出来的集群性能,再结合计算需求和通信需求,整体做了一个重新的映射。这是一个系统性、全生命周期的优化,在端到端上实测有2.1倍的性能提升。
映射和拓扑是两部分信息,一部分是框架告诉模型该怎么训练,或模型有哪些切分方式,切分之后计算模式是什么样的,它们之间的通信模式什么样。另一部分是结合自己在通信库中做的拓扑探测和拓扑感知,会探知出一个集群中的单节点和集群之间的计算、通信模式和能力,形成集群拓扑通信图。
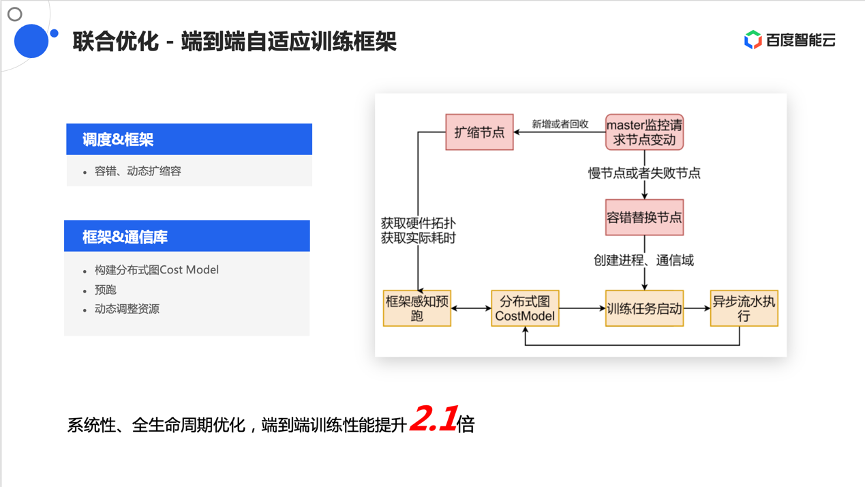
这两个图之间会结合一些图算法,做最优映射,再将映射结果交由框架,再借助调度器的策略调度能力,做最终的硬件拓扑调度以及作业的重放置。通过这种方式,实现了一个框架调度通信库的联合优化,从而端到端的提升整体的训练效率。
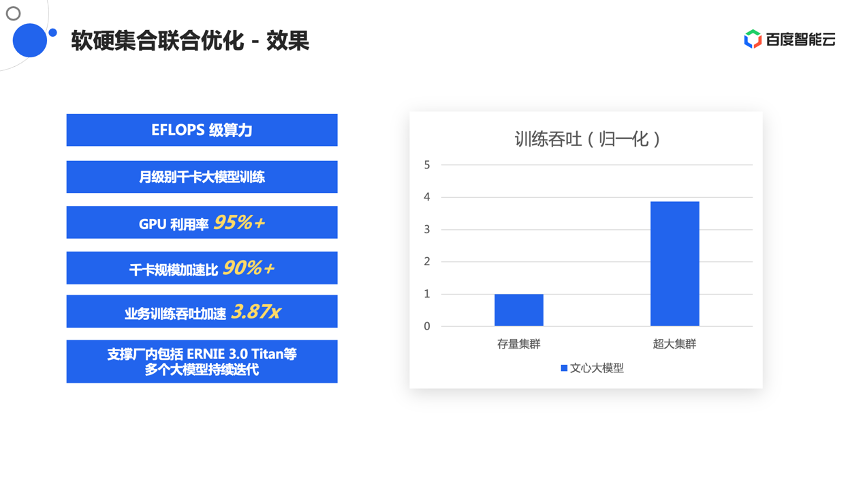
最终的效果建立了一个完整的EFlops级算力的集群,真正的实现了月级别千卡大模型的训练。在训练过程中,整个GPU的利用率一直维持在95%以上,很好的发挥了硬件能力,千卡规模的加速倍也做到了90%以上,整个业务训练的吞吐结合业务实测大概有3.87倍的提升,这个集群也真实的支撑了像ERNIE 3.0 Titan等多个大模型的持续迭代。
相关文章推荐
发表评论
关于作者

- 被阅读数
- 被赞数
- 被收藏数
登录后可评论,请前往 登录 或 注册