AI+药物研发:人工智能赋能新药研发
2022.04.11 15:00浏览量:916简介:AI+药物研发:人工智能赋能新药研发

宋乐 百图生科首席AI科学家
曾任美国佐治亚理工学院计算机学院终身教授、机器学习中心副主任、阿联酋MBZUAI机器学习系主任
本次将由百图生科首席AI科学家宋乐博士为大家分享人工智能赋能新药研发👏👏👏
首先,生物制药行业面临着两个挑战:
- 第一,新药研发周期很长且非常复杂;
- 第二,药物研发过程成本昂贵。在1950年的时候,十亿美元可以研发几十个药,到了2020年之后,十亿美元只能研发一个药(如下图),所以就需要大量的投入。
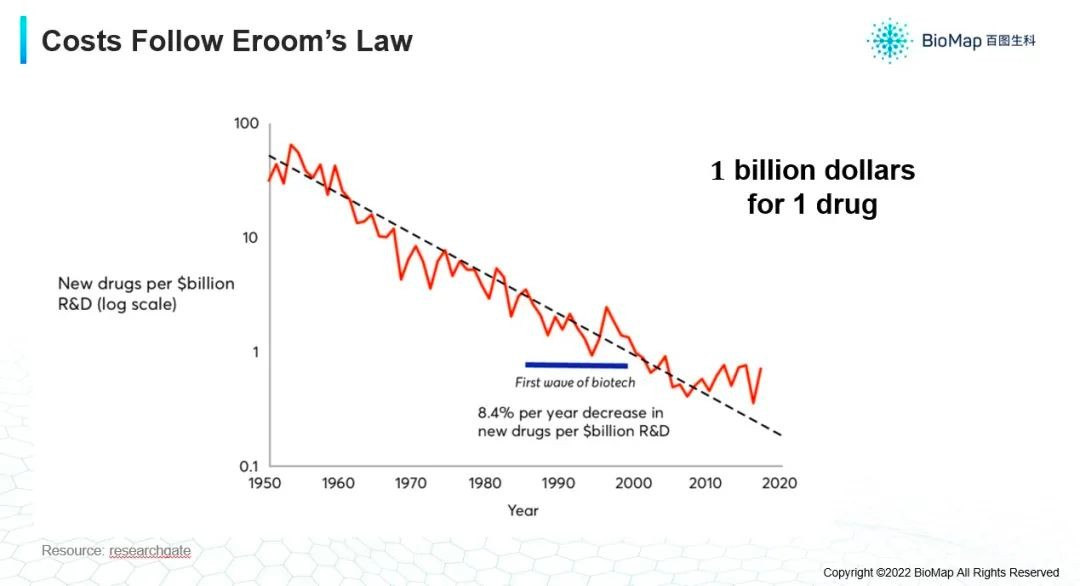
随着对药物审批过程的要求越来越严格,对药物副作用的要求越来越高,使得新药的研发变得越来越慢。如果我们能把研发时间减半,成本减半,再加上巨大的市场需求,这个领域是具有广阔前景的,所以最近很多投资或者AI方面的研究,都在朝着这个方面发展。
之所以会如此有挑战,是因为背后复杂数据,或者复杂的生物机理造成的。如果我们能够对复杂的数据与机理进行更好的分析研究,也许我们就可以把时间与成本减半。
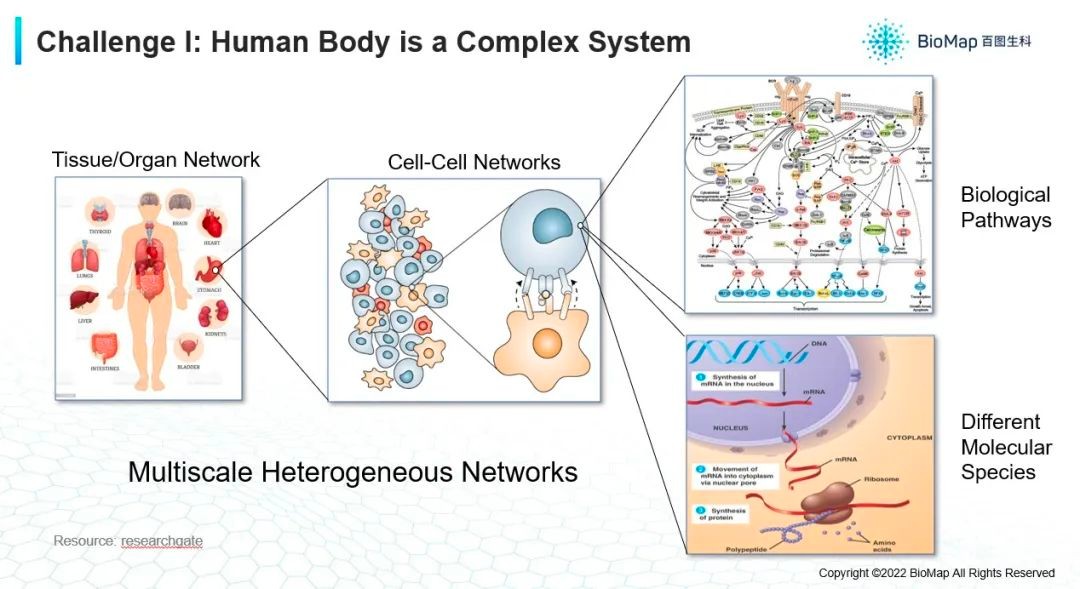
那为什么这么复杂。首先人体是非常复杂且多尺度的网络,有各种各样不同类型的器官(上图),不同的器官有它自己的疾病,但是器官绝对不是一个独立的个体,它是一个网络,一个系统。如果你看单个器官,里面有各种各样类型的细胞,它们之间互相交互,互相传递信息协同,才能完成一个器官的功能。不同的细胞之间有信号串扰,有各种各样的细胞因子,它们之间会影响彼此,每个细胞有不同的功能和形态才能产生它的方式,所以组织层面是非常复杂的细胞网络。
如果单看一个细胞,里面也是有很复杂的网络构成,细胞里面经常提供的是蛋白质,可能在细胞膜上,也可能在细胞里面,这些蛋白质不是以独立个体的形式在工作,而是通过互相作用的方式来产生功能。比如:在细胞膜表面蛋白,在接受外界的刺激后,会把信号传递到细胞里面,通过一个非常复杂的网络来实现某种机理,比如说,分泌更多的某种物质,或者是产生更多的能量,甚至回过去调控基因的表达,让某种蛋白变的更多。
我们要理解并治疗某个疾病,就要多尺度多角度的考虑,既要看组织层面,又要看分子层面,并找到疾病的靶点,才能有针对性的进行治疗。
现阶段很难对人体的各个维度的数据同时做一个精准的测量,因为需要同时对各个尺度采集数据。在整个个体层面,有各种各样很大的数据,且数据量增长速度比摩尔定律还要快。
所以可以想象,这么大量且复杂的多尺度的数据,要对它进行分析,并从中间抽取非常微妙的信号来理解疾病,寻找疾病的靶点,目前已经超越了传统的生物学家或者是医学家的手工分析工具的能力,所以他们会需要基于AI的方法,基于大数据分析的方法,能够把各种各样的数据进行某种整合、分析,从中间抽取一些信息。自动化该过程,才有可能跟上数据的复杂程度和数据的量,然后从中间找到一些有用的信号。
通过分析数据和多样的模型,可以对各种各样的东西做预测,比如:可以预测这个蛋白是不是疾病的靶点,扰动这个细胞,是否会产生某种现象?这些都可以通过模型预测,但预测完后,还需要做试验,比如说细胞的实验,去验证模型的预测是不是正确。
这也是这个领域的一个挑战,传统的生物实验室是一个非常开环的环境。首先实验人员对细胞进行某个扰动,再去测量这个细胞状态的变化,收集各种各样的数据。在这个过程之后,会有几个分析人员,拿到实验室做个简单的分析,交给实验室主任或者教授来判断并决定下一个实验。这个过程虽然是一个闭环的过程,但这个闭环的速度很慢,可能是几周时间甚至更长时间。
我们可以把生物实验的环境和推荐系统做一个对比,很多互联网公司很多情况下得益于推荐系统非常精准的推荐及推荐系统高效的迭代。如果把这个推荐系统对用户展示的前端页面看成是个实验环节,推荐系统的前端可以展示推荐算法和模型推荐的产品,在展示之后,可能这个APP有几亿人在用,如果推荐算法推荐得好,就能看到推荐产品的人,在很短的时间内点击购买推荐的产品。如此,就知道这个推荐算法好坏与否,如果推荐的东西没有被点击没有被购买的话,可能是推荐算法不太好。所以,无论用户是否点击了推荐产品,都会是一种隐含的的反馈,这些数据都会存在这个APP或对应的数据中台里面,可能隔夜或者隔周要迭代推荐算法模型,当这个模型迭代以后,会很快更新上线,然后会做一个更新的推荐。如果能把实验的环节和数据分析以及决策的过程,更加好的闭环自动化,也许会有更高效的方式去验证并发现一些新的靶点或者新的药物。
如果能够建立一个平台,使AI和实验环境如推荐系统高效跑起来,实验的数据可以自动落到数据中台,包括生物实验的实验基数据,及部分图像数据或其他数据,都能落到中台的话,就会有一组AI模型对各种类型的数据进行分析,以及对这些数据进行整合,产生新的预测, 进而推进实验(下图)。
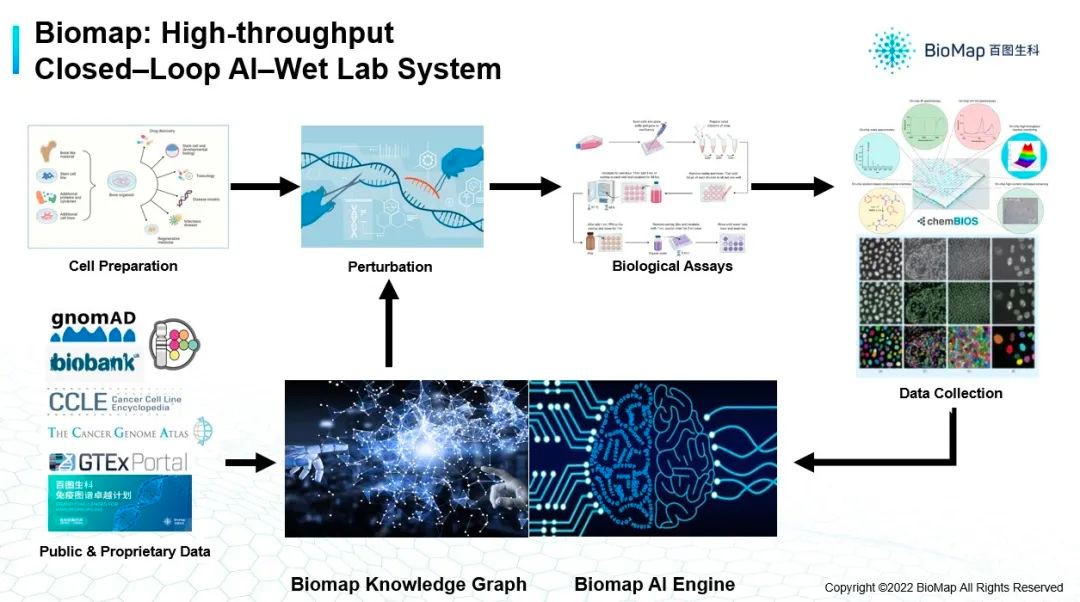
除此之外,我们不仅有自己的湿实验平台及实验平台和AI模型闭环的系统,还会对很多前人已经研究的成果进行一个集成,因为过去几十年的生物信息学和计算生物学研究过程,已经产生了非常多的公开数据,包括如蛋白质相互作用的数据,及基因表达数据,我们都会整合到知识库里。
我们的卓越计划中,也会和部分国内的大医院合作,去收集针对某个疾病设计的一些队列数据。
这个大模型涉及到三个问题:
- 第一,如何发现一个药物靶点?
第二,如何针对某一个已经发现的药物靶点,做一个对应的药物优化?
第三,如果要做实验,在实验平台里面产生数据如何分析,包括图像数据的分析。
基于以上,今天我主要从靶点发现、药物优化、验证三个方向阐述。
首先,靶点发现(下图)。
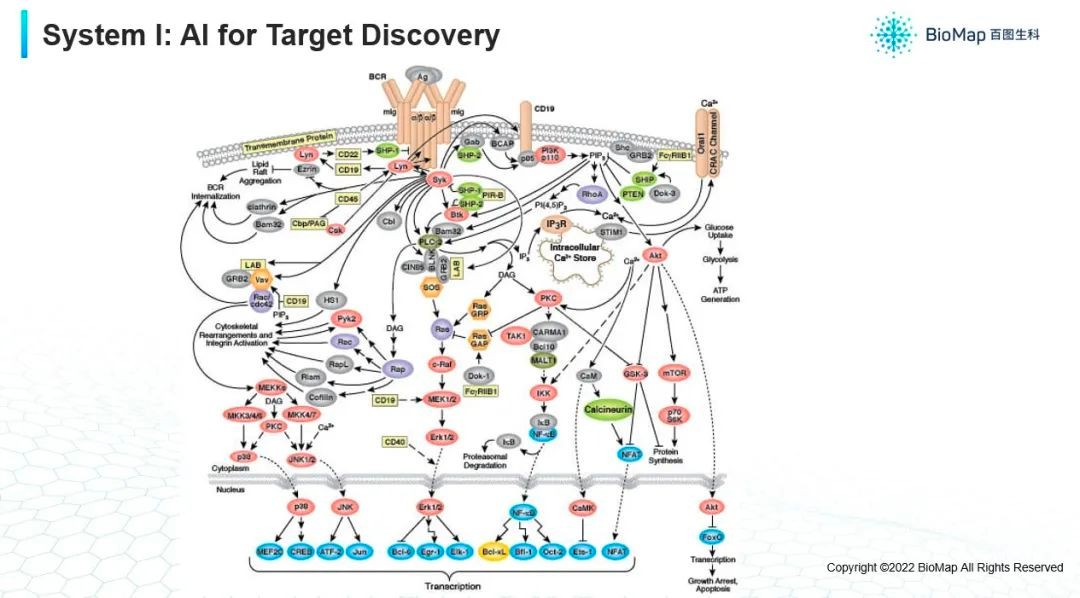
其实刚才我也提到,理解一个疾病发现一个靶点,实际上我们要分析复杂的多尺度的系统。通常情况下,描述复杂系统最好的方式就是复杂网络,在细胞层面的复杂网络每个节点就是一个蛋白质,它们是连接成一个非常复杂的网络,这个蛋白质被激活可能去激活其他的蛋白质,然后其他几个一起形成一个复合体以完成某种功能,这个图比互联网的人与人之间的交互图更加复杂,它叫做超图,它的每条边并不是只涉及两种蛋白质,有可能是几个蛋白质一起形成新的相互作用,才能产生后面的功能,因此是一个复超图。如果要分析某个节点是不是一个区分癌症组织和正常组织的蛋白质或者生物标志物。以及假设激活或抑制一个蛋白质会带来怎样的下游效应,这些都是和靶点相关的预测问题。
可以想象,他的输入是一个复杂的的超图,它有超图上的各种各样的分类问题或者是预测,甚至是回归问题。甚至预测组合效应如果我同时按下两个按钮,它会产生什么样的影响?
超图是一种类型,对于每一种类型的数据,包括蛋白质,RNA还有基因序列,可以做实际数量的测量,比如:蛋白质在这个细胞里面有多少,基因表达了多少,这个序列的三维组织结构是怎样的。这些信息可以映射回这个网络里面每个节点上的。所以,除了超图连接上的复杂之外,每个图的节点也蕴含着非常复杂的信息,可以想象很多做社交网络分析的一些方法,被扩展或者修改甚至进行一些新的创建,才能分析这种复杂的这种超图结构。
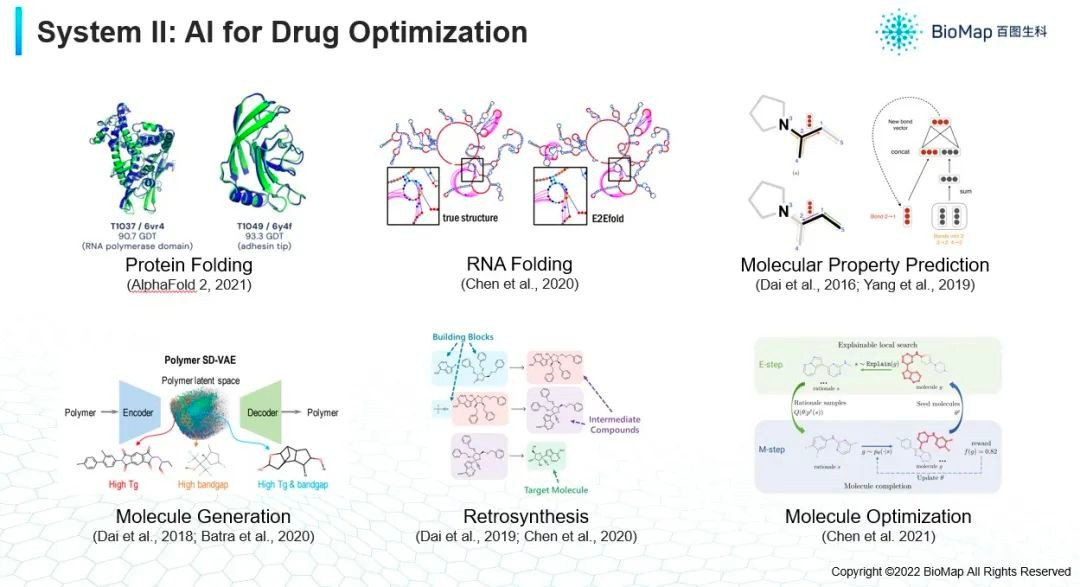
其次,假如你已经发现了一个靶点(上图),发现其中某个蛋白质是关键节点并希望能激活,抑制它,就需要设计一个药物来做这件事。靶点在细胞内,你需要一个小分子进入到细胞里面去,如果这个靶点是在膜蛋白或者在细胞膜表面,你要用另外一种蛋白的方式去激活或者抑制它。很多情况下蛋白质工作与否,实际上是和它的三维结构很大关系。蛋白质一开始的时候是一条序列,细胞里面涉及的分子不管是DNA RNA还是蛋白质甚至小分子它都有对应的三维结构。火爆的AF2就是根据蛋白质序列预测蛋白质的三维结构。假如我们对三维结构有很好了解之后,我们就可以对它的功能有更加准确的理解。因为蛋白质和蛋白质之间的相互作用,其功能是因为两个蛋白质有一种像钥匙和锁的一个关系,它们只有能够对上且对得很好的情况下,它的功能才会被完全发挥出来。
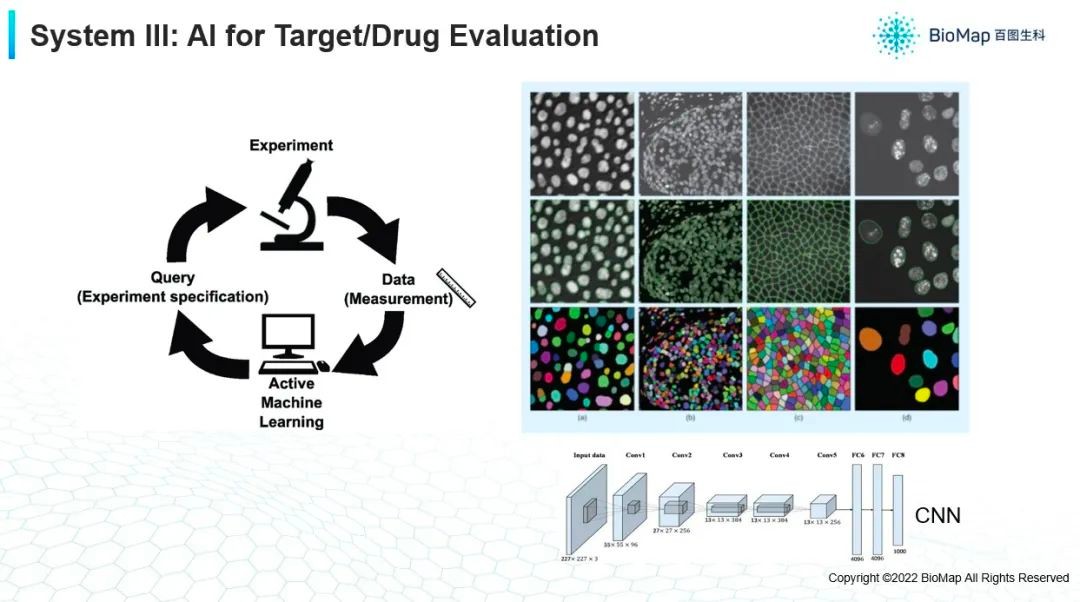
最后,我想讲一下(上图),这方面涉及到的一些问题和挑战。我们的实验平台,会产生大量的图像数据。它们不单单是单个细胞图像数据,有可能混合几种不同的细胞,而且这个细胞它可能不单单是一个黑白的图像,也有可能是一个有6种颜色的图像,是一个叫高内涵的图像。在这种情况下要对它做各种各样的,比如说细胞的检测,它的分割及形态的描述,然后进行各种各样的更加细致的分析。所以很多细胞视觉研发思路甚至最先进的研发思路都在做这个。除此之外,实验的平台是和AI模型有个闭环,所以如何把AI的模型的预测结果来指导实验的下一步,也有很多AI或者机器学习的算法可以去探索,包括主动学习,贝叶斯优化或者是在线学习各种各样的方法。可以想象,都会在AI模型和实验闭环中产生非常大的作用,比如减少实验的次数。每次实验产生的信息足够多,就能够帮助更快地发现一些有效的药物,发现一个合理的靶点。
在处理这些实验的数据时,有的情况下会叫人来打标。它需要有生物背景本科或者博士生医学背景的这些人员才可以。如果能够使用尽量少的打标数据或者有选择性的打标,很快能够得到一个比较精确的模型。
那如何让AI模型和人一起产生协同作用,能够把任务做得更好,就可以尝试把模型迭代更新与打标人员放在一起,建立系统,让模型提出一些候选对象,然后让人员对这个候选对象或者不同水平的人员,对不同的打标需求做匹配。
讲了这么多,结束前我想回到复杂系统。每个复杂网络节点的结构的数据分析,及各种各样的AI问题,需要各种类型的AI人才去合作,去理解这个疾病,才能把这个靶点和这个药物找到。

发表评论
登录后可评论,请前往 登录 或 注册