云原生时代的搜索服务算力管理
2022.04.29 10:38浏览量:963简介:云原生时代的搜索服务算力管理
导读:本文主要介绍百度搜索架构团队在服务算力管理方向的工程实践和相关经验,涉及服务与容器算力的“时间”“空间”话题。
一、搜索服务算力管理综述
1.1 搜索算力管理的发展历程
算力管理的核心目标,是实现算力需求与算力资源的最优匹配。搜索服务算力管理的发展经历了以下3个阶段:

1)物理机部署阶段
2014年以前,搜索服务模块都是直接部署在物理机上。这时物理机的CPU、内存、SSD等大小相对统一,个别空闲的机器会手工选择一些模块进行混部;夜间用户流量低峰时候,会有BVC这样离线计算框架,支持离在线任务混部,实现资源充分利用。
2)半自动混部阶段
2014年~2018年间,搜索业务自研的PaaS实现了服务的半自动化的混部。半自动化体现于:混部策略由人工设计,执行过程为命令式,容量管理由人工维护。这个阶段,业务有项目上线,需要询问容量专员,某些模块的算力资源是否还有空闲,是否可以支持该项目消耗。对于大型项目,我们自研了全链路压测技术,支持精确容量压测,确保不出现系统级瓶颈。
3)云原生混部阶段
2018年之后,搜索业务将服务托管至公司云平台上,利用云平台对服务进行自动伸缩、自动混部。业务上线前,不再需要询问容量专员,直接在云平台提交扩容申请即可。这期间,我们把更重要的流量匹配到计算得更快的容器上,实现速度与成本兼顾。
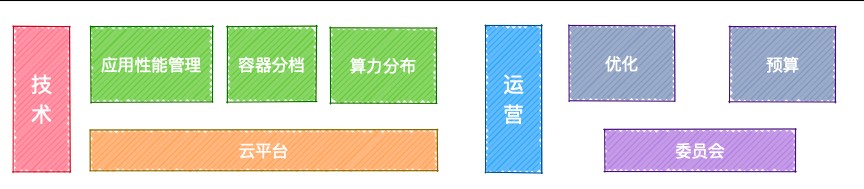
1.2 搜索算力治理体系
搜索服务算力质量治理体系,分为两大部分:技术架构和运营体系。
1)技术架构
充分依托弹性容器实例、智能监控、Service Mesh等公司云平台提供的技术产品,实现quota的智能管理,达到算力需求与资源更好的匹配。
2)运营体系
成立委员会制度,通过委员会驱动成本和速度相关的优化、运作业务项目预算审批流程,在全局维度实现开源节流。
二、搜索服务算力管理的业务特色
2.1 面向全时段优化
在用户产品服务中,用户流量是潮汐波动的,夜间用户流量少了,利用率下降出现资源闲置,这时需要用云的思想重新考虑这个问题。
1)潮汐伸缩
云原生应用12要素中提到“通过进程模式进行扩展”,意思是我们云上的服务不应该是单点,而是由很多副本实例组成。低峰期并非利用率下降,而是需要的实例数减少了。所以,通过在夜间对实例缩容、白天高峰到来前扩容的潮汐方式,可以实现夜间账单的下降。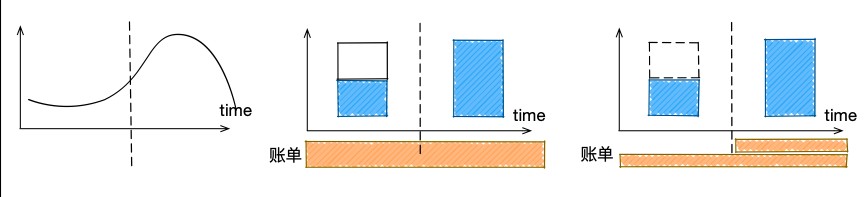
2)窗口迁移
云平台的本质之一是市场化:夜间供给大于需求时,容器单价下降,例如网约车价格。搜索业务基于cache技术进行内容失效预测,可提前在夜间算力更廉价时启动计算任务,用户在次日高峰期可获得相对较新的结果。这是通过计算任务时间窗口迁移,实现整体资源账单的优化。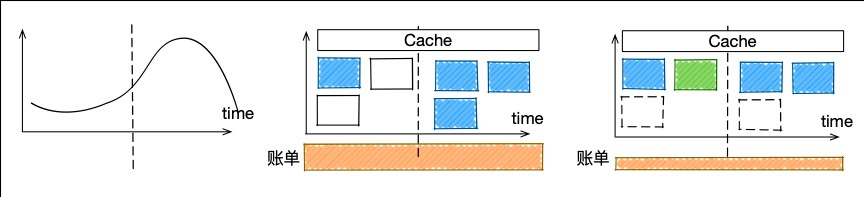
2.2 同时段深挖算力空间
在相同的时间点,通过对整个搜索服务集群的计算任务分类,也存在可以挖掘优化的空间。具体任务类型包括:近线任务、异步任务、同步任务。
1)近线任务
在线计算需要控制复杂度以保障较低的响应延迟,我们可以把复杂计算后的“好结果”写入近线存储或者cache中,当用户在线查询相关请求时候,就可以得到更好的结果反馈。这个best effect方式,并不需要容器有特别高的稳定性,可以采用更廉价的可抢占式容器,来提供近线算力资源。
2)异步任务
应用cache可以加速服务响应、降低cache后端资源成本。完整的cache时效性可以分为三个级别:失效时立即更新;失效前在夜间提前更新;失效时立即发起更新,但不把更新结果同步用户,异步更新给cache。在第三种场景下,需要保证计算的效果,又不需立即返回,则可选用稳定性稍好、处理速度稍慢的容器。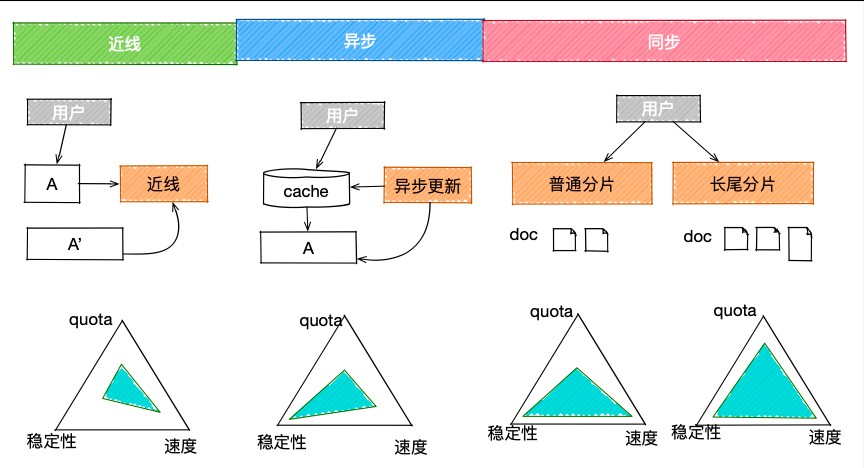
3)同步任务
同步计算任务,需要立即计算结果并将结果返回给用户。例如搜索业务的索引服务,大部分是用分片方式提供服务的。但在大规模分布式场景下,分片多少会存在计算长尾,长尾分片可能索引了更复杂的文档,或是文档数量比平均值稍高。对于长尾分片,可以购买稳定性更好、速度更快、quota更大的容器;对于普通分片,计算复杂度相对较低,可购买quota相对较少的容器。实现容器的差异化采购。
三、搜索服务算力管理的关键技术
3.1 应用性能管理
1)性能曲线
容器规格的设置需要考虑很多因素。在搜索服务中,计算任务存在大量内存访问,减少实例数可以降低内存复制成本,同时单容器流量增加,带来内存访问压力增大,对性能影响是非线性的,传统模式下需要通过大量线下测试来观察。在云原生系统中,依托云原生监控机制,将模块的流量、响应时间、资源使用量关系充分关联,通过大规模样本聚合分析,可以得到更具统计意义的性能曲线。

2)vpa/hpa
性能曲线可以得到服务的基本性能模式,根据服务的任务类型(近线、异步、同步等)运行不同的quota管理策略,预测未来一段时间服务的理想资源quota,最后产出伸缩事件,触发PaaS进行调整。

3)流量缩容
性能优化项目上线后,会通过缩容释放资源。传统的方法,因线上稳定性要求,缩容需分批多次进行,效率低,且缩容到优化边界时偏于保守,优化的成果不能充分释放。在云上使用新方法,即基于Service Mesh的能力,将缩容改为切流,创建一个更小的调度集合,通过mesh切换和调度,大幅度缩短观察周期和修复耗时,可以更充分地把优化成果释放出来。
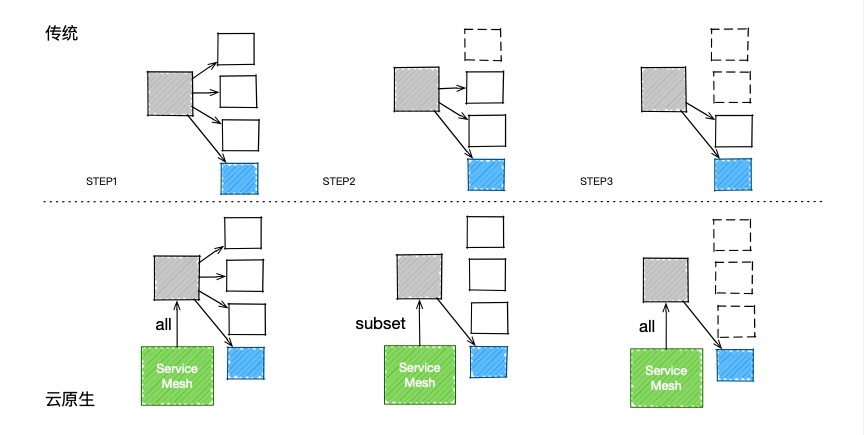
3.2 容器分档
1)静态分档
我们考虑这样一个场景,如下trace图,某个服务并行访问A、B两个下游,A的响应时间更长一些,所以提升A的性能可以缩短上层服务时间。但如果B中更快的容器(绿色)比A更多,则系统整体性能就不是最优的。这是通过增加A的快速容器让A算得更快,可以缩短整体响应时间。
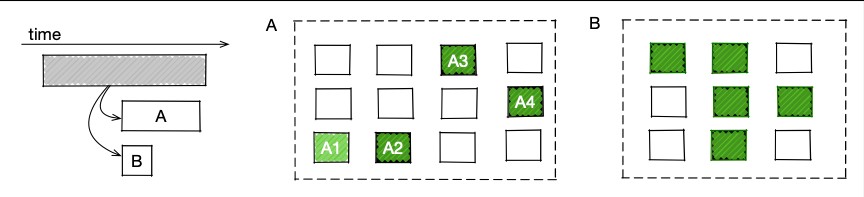
2)动态分档
容器运行相同计算任务的速度,受宿主机硬件性能和硬件状态影响。根据宿主机的硬件性能对容器运行计算任务的速度进行划分,我们定义为静态分档;根据容器宿主机的硬件状态对容器运行计算任务的速度进行划分,我们定义为动态分档。如下图所示,部署在相同快速硬件型号上的A1~A4容器,A1容器因宿主机资源较空闲,计算速度更快。
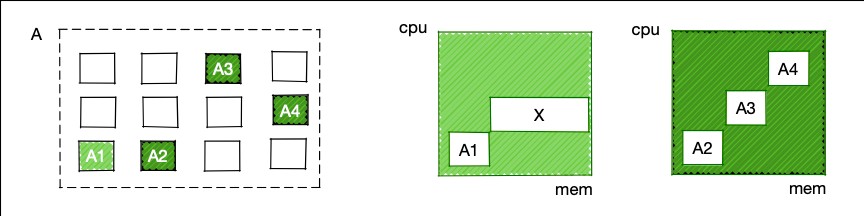
3.3 算力分布
1)精细流量调度
完成分档后,可通过更精细的流量调度,高效使用不同分档的容器。我们将服务分为高速单元和低速单元,高速单元部署在快速容器上,低速单元部署在低速容器上。处理请求时,首先进行流量类型识别,高优流量路由到高速服务单元上,再预估请求的计算复杂度,把更复杂的计算发送到更快容器上,进一步提升请求的计算速度。
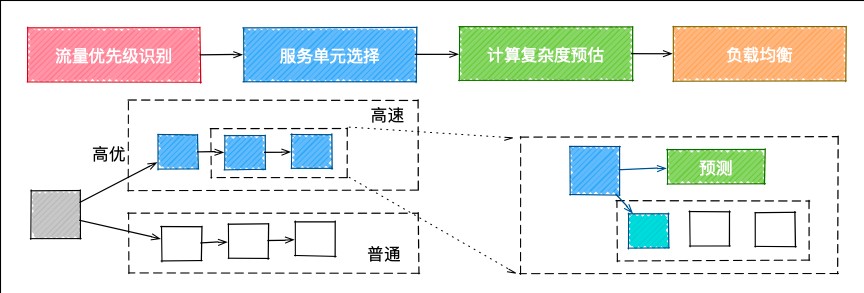
2)智能cache预充
通过cache技术,可以在时间上实现任务计算窗口迁移,从而更好地使用容器。日间高峰期,将请求收集到请求数据中心;在夜间低峰期,预测cache失效的请求发送到请求队列,经过请求代理重新计算更新cache,降低高峰期的流量。
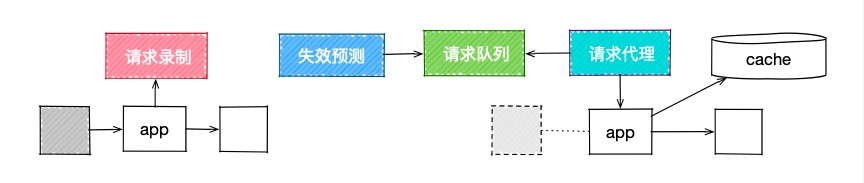
四、总结
以上,回顾了搜索服务算力管理的发展历程,概览了运营+技术的治理体系,重点介绍了技术架构侧的近期业务特色工作,覆盖时间和空间两个方面。
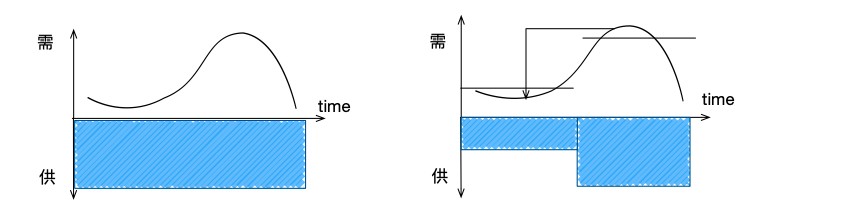
时间方面,算力需求潮汐变化,传统的方法供给按最大值购买。而基于云原生技术,在低峰期可减少大量无效购买,增加适当购买廉价容器转移高峰计算量。
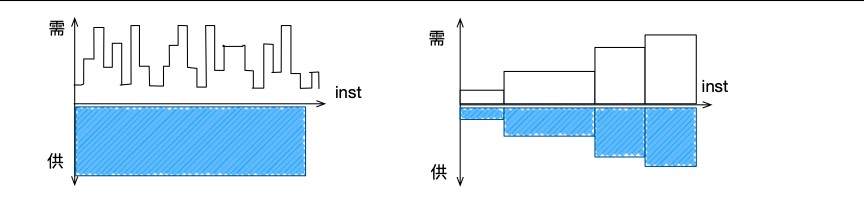
空间方面,未经梳理的梳理需求看似杂乱无章,传统的方法供给同样是按最大值购买;基于云原生技术,区分高低优先级的任务,用不同速度的容器来提供服务,可以达到更优的资源配置。
立足云原生时代,搜索服务算力管理会进一步应用更灵活、更丰富的控制手段,保持对算力需求和资源更优配置的不断追求。

发表评论
登录后可评论,请前往 登录 或 注册