为什么说下一代存算分离是大数据建设的必然趋势?
作者:技术大发2022.04.29 10:47浏览量:1234简介:为什么说下一代存算分离是大数据建设的必然趋势?
根据Starburst联合创始人贾斯汀·伯格曼的经验,想要让企业数据架构经得起时间的考验,关键之一就是拥抱存算分离。
著名开源数据库TiDB创始人黄东旭在《近十年数据库流行趋势纵览!存储计算分离、ACID 全面回归……》一文中,也将存算分离放在近年数据库流行趋势的第一位。
Facebook根据自己的业务需求,研发了一套存算分离的架构来支撑上亿用户产生的大数据。各大企业尤其是互联网行业也都开始采取存算分离作为数据库的解决方案,理论和实践都在向我们阐述存算分离的正确性,因此我们想研究两个问题:
为什么存算分离会成为历史的必然选择?
为什么向存算分离的下一代演进是大势所趋?
01 为什么存算分离会成为历史的必然选择?
想要了解企业数据架构向存算分离演进的必然性,首先要了解企业每一次数据架构变迁的背景和理由。
回顾历史,我们会发现,数据架构变迁往往是因为当时技术暴露种种缺点,与企业新的发展需求不匹配。
这些变迁,最早可以追溯到上世纪90年代——
20世纪90年代,一些企业开始部署开源数据库以支持 Web 应用程序,因为免费,所以在当时大受欢迎;
进入21世纪初期,开始面临“数据多,很难在一台物理机器上分析数据”的难题,企业开始采用大规模并行处理 (MPP) 驱动的新型数据库系统。
发展到2010 年前后,因为新兴业务的不断产生,而MPP数据库缺乏现代分析和数据科学所需的灵活性,企业再次转向另一种新技术:Hadoop,即采用节点本地存储的设计,由此形成计算和存储耦合(即存算一体)的架构。
同样地,来到今天,随着5G、IoT等技术不断发展,数据量激增,存储空间和计算能力与数据增长不匹配,存算耦合的缺点也逐渐暴露:
1. 资源利用率低
从节点本身承接的业务来看,日志留存类的服务,数据很少被调用分析,因此CPU利用率较低,造成计算资源浪费,而且当计算或存储达到瓶颈,服务器的可靠性也会大大降低。从集群整体来看,由于存算一体烟囱式建设,资源完全独立不能共享,导致多个Hadoop集群无法随不同时段业务需求的波动而均衡负载(平均资源利用率在25%以下)。
2. 成本高
当存算按某一比例强制绑定在一起,就意味着无法弹性扩容,同时为保证可靠性,采用三副本模式,造成大集群下高昂的存储成本。
3. 运维困难
随着业务复杂度的增加和新业务上线的速度加快,对服务器资源配比的要求也会随之增加,如果服务器款型繁杂,维护难度就会增大,同时导致机房空间占用多、能耗大。
基于上面的背景分析,存算分离进入大家的视野。
可以说,存算分离针对存算一体的弊端进行优化,为企业控制成本和提升数据运行的效率提供了新的思路,具体来说:
1. 提升资源利用率,节约成本
实现计算和存储弹性扩展、按需分配,降低了系统部署和扩展成本,同时将CPU和磁盘充分调度起来,解决了资源利用不均衡的问题。
2. 简化运维,提升可靠性
使用外置共享存储方便备份恢复,提高SSD的使用寿命,从而提高数据库解决方案整体的可靠性,同时解决运维能力不足造成的硬件冗余。
随着企业数字化建设的深入和业务诉求的升级,如果仅仅满足于存算分离1.0时代,还远远不够。
02 为什么向存算分离的下一代演进是大势所趋?
如前文所说,存算分离1.0时代的解决方案聚焦成本,解决海量数据激增下企业如何重新定义大数据建设架构的问题,但仍未解决数据链路长、数据孤岛、数据搬迁难等问题。
为了应对大数据时代下融合+实时分析数据的需求,企业IT架构向下一代存算分离演进势在必行。
当传输协议和带宽能力已不再是IO瓶颈,下一代大数据存储应该向湖仓一体、一湖多云演进,更多以数据为中心,聚焦数据用得好的问题,以数据驱动融合分析、统一存储,进一步驱动数据价值实时变现。
那么,以数据为中心的下一代存算分离,与1.0时代有什么不同?
首先通过实现计算和存储资源的单独扩容,然后将原本分散的数据实现集中存储,打造统一的数据湖(Data lakehouse)。
同时,实现一湖多云对接。新一代数据库,尤其是分布式数据库,普遍采用云计算部署方式。下一代存算分离可以将数据存储保留在本地,将机器学习等计算资源部署在公有云。这样既能保证数据的安全性,又能实现计算的敏捷。
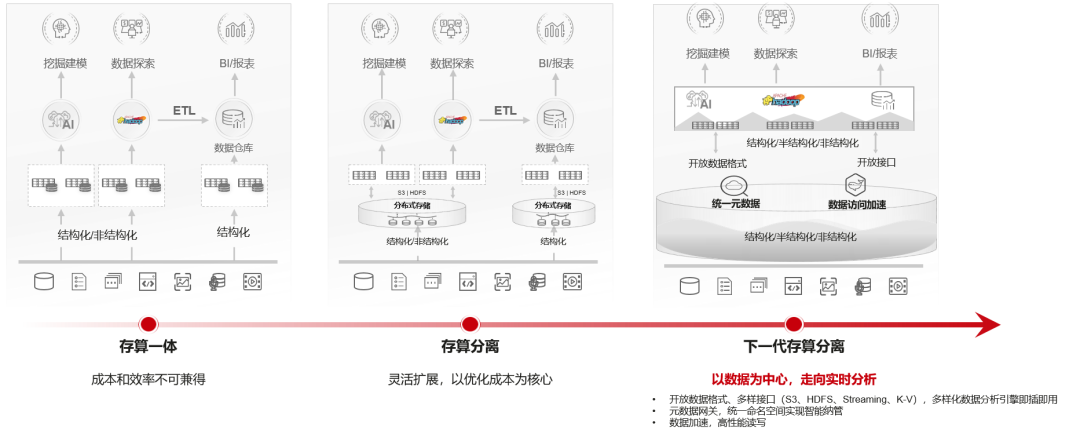
换句话说,下一代存算分离方案通过性能优化、元数据统一管理,实现以数据为中心的高效跨云协同、跨云管理。
以华为的OceanStor Pacific为例,作为国内大数据下一代存算分离的解决方案先行者之一,在存储层实现了原生HDFS语义接口的存算分离方案,打破了传统大数据平台计算存储的部署架构。同时率先在存储上支持湖仓融合的新兴数据格式,在下一代存算分离架构下,基于一份数据支持接数据湖、数据仓库同时访问。提供以业务为中心的高弹性大数据计算,以数据为中心的高性能海量存储,用户无感知的原生HDFS和S3兼容能力。
据了解,OceanStor Pacific不仅算力密度在业界领先30%,而且做到一站式交付、一键式部署,可以有效匹配企业大数据快速迭代发展。
更重要的是,对不同的行业和企业来说,下一代存算分离方案可以真正把技术落到实处,发挥作用。
对金融企业来说,这可以提升数据共享便捷度,减少数据重复存储和搬迁,缩短数据加工链路,大大提高了数据分析的效率。
对政务平台来说,可以从推动政务管理大数据向城市运行大数据演进,让平台在办理业务时可以在不同应用间共享数据,弹性调度不同资源,满足不同时间段的需求。
对运营商来说,使用下一代存算分离解决方案可以降本增效,提高资源利用率,降低运营成本,实现全国算力网络统一布局。
根据凤凰科技的报道,中国联通基于华为 OceanStor Pacific 海量存储的大数据平台于2020年7月正式上线。承载互联网分析、loT、日志等系统15PB的数据量,实现联通各省公司2/3/4/5GxDR等数据的接入分析,日导入数据量超过70TB,取得了实质性的突破。
其实,时代和技术,始终在进步。
企业也一直向前发展,需求在不断更新。
但通过以上种种分析和举例,我们至少可以说——
为了扩大数据分析架构的规模、提高数据分析的灵活性和敏捷性,存算分离是目前降低数据分析成本的第一步,向下一代存算分离演进,则是更重要的一步。
相关文章推荐
发表评论
关于作者

- 被阅读数
- 被赞数
- 被收藏数
登录后可评论,请前往 登录 或 注册