Spark离线开发框架设计与实现
2022.05.16 16:06浏览量:814简介:Spark离线开发框架设计与实现
导读:本文介绍了开发框架的整体设计,随后对各模块进行了拆解,重点介绍了如何快速实现应用程序的开发,并从设计思路、实现方式、功能介绍及创建方式等角度对通用的数据回溯应用进行了全面介绍,实现了一次环境准备,多数据回溯任务的启动方案。总之,框架对开发效率、回溯任务的效率与维护成本及代码管理便捷性都会有显著的效果。
一、背景
随着 Spark 以及其社区的不断发展,Spark本身技术也在不断成熟,Spark在技术架构和性能上的优势越来越明显,目前大多数公司在大数据处理中都倾向使用Spark。Spark支持多种语言的开发,如Scala、Java、Sql、Python等。
Spark SQL使用标准的数据连接,与Hive兼容,易与其它语言API整合,表达清晰、简单易上手、学习成本低,是开发者开发简单数据处理的首选语言,但对于复杂的数据处理、数据分析的开发,使用SQL开发显得力不从心,维护成本也非常高,使用高级语言处理会更高效。
在日常的数据仓库开发工作中,我们除了开发工作外,也涉及大量的数据回溯任务。对于创新型业务来说,口径变化频繁、业务迅速迭代,数据仓库的回溯非常常见,通过回溯几个月甚至一年是非常普遍的,但传统的回溯任务方式效率极低,而且需要人力密切关注各任务状态。
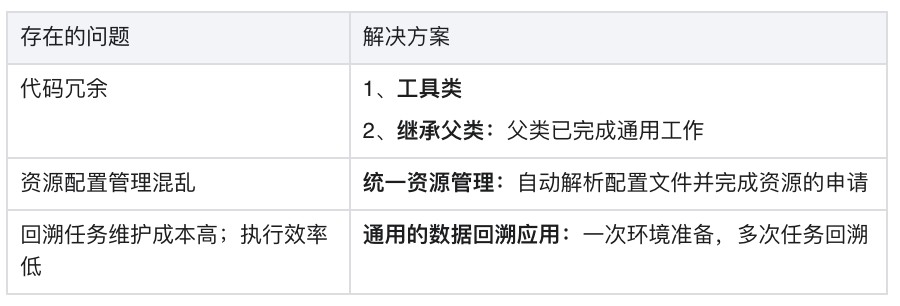
针对目前现状,我们开发了一套Spark离线开发框架,如下表所示,我们例举了目前存在的问题及解决方案。框架的实现不仅让开发变得简单高效,而且对于数据的回溯工作在不需要任何开发的情况下,快速高效地完成大量的回溯工作。
二、框架设计
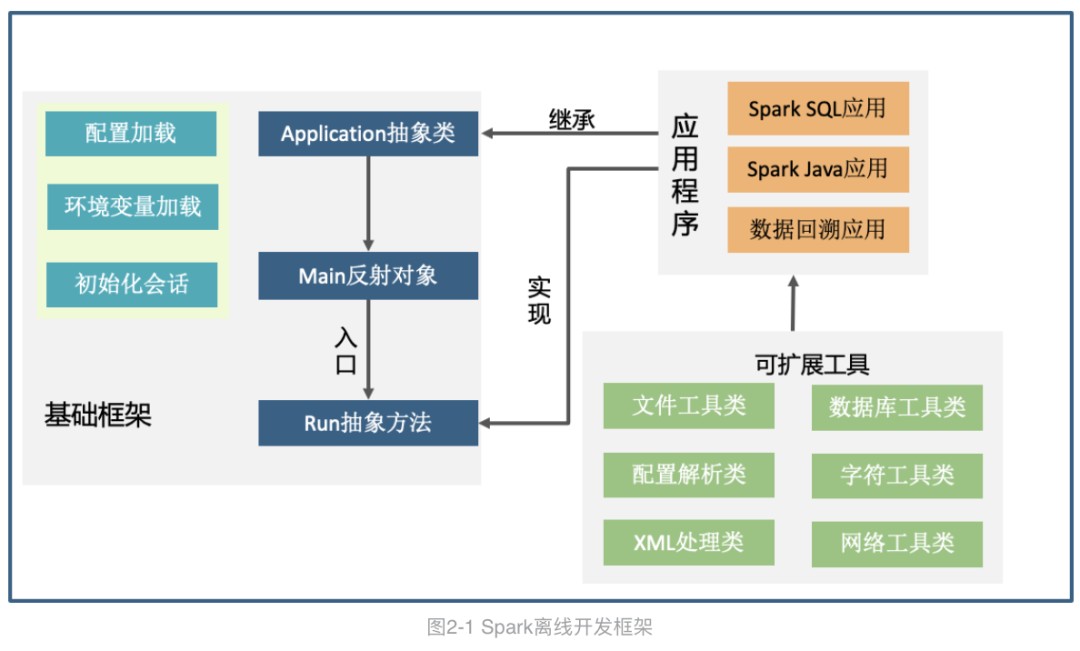
框架旨在封装重复的工作,让开发变得简单。框架如图2-1所示,主要分为三个部分,基础框架、可扩展工具及应用程序,开发者只需关注应用程序即可简单快速实现代码开发。
2.1 基础框架
基础框架中,我们对于所有类型的应用实现代码与配置分离机制,资源配置统一以XML文件形式保存并由框架解析处理。框架会根据开发者配置的任务使用资源大小,完成了SparkSession、SparkContext、SparkConf的创建,同时加载了常用环境变量,开发了通用的UDF函数(如常用的url参数解析等)。其中Application为所有应用的父类,处理流程如图所示,开发者只需编写关注绿色部分即可。
图片
目前,离线框架所支持的常用环境变量如下表所示。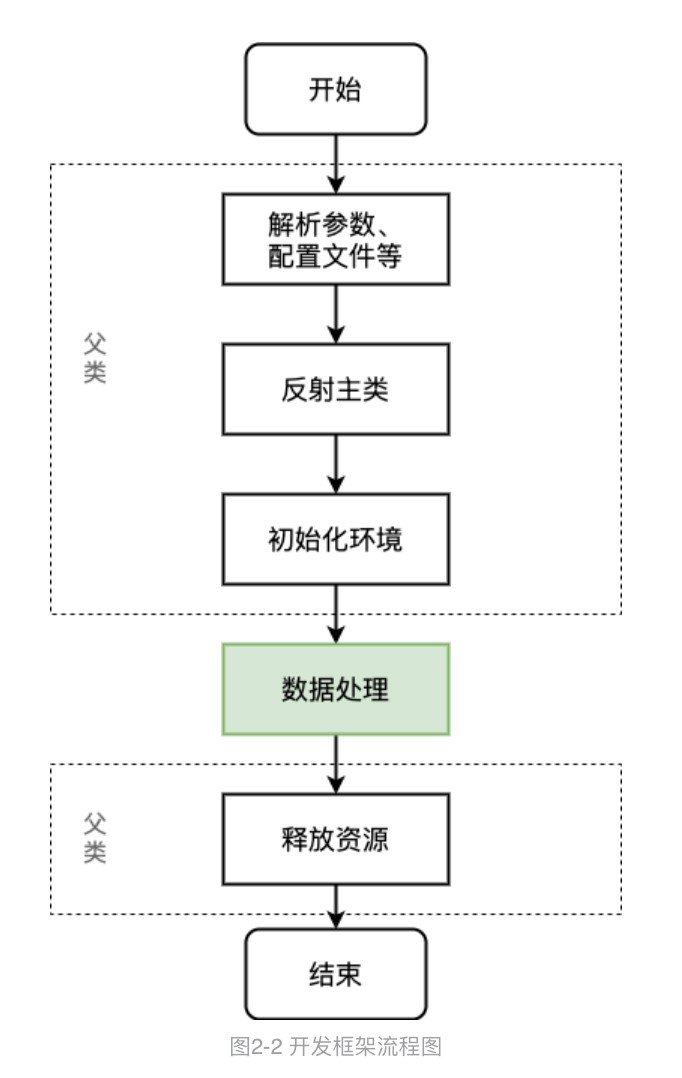
2.2 可扩展工具
可扩展工具中包含了大量的工具类,服务于应用程序及基础框架,常用有,配置文件解析类,如解析任务资源参数等;数据库工具类,用于读写数据库;日期工具类,用于日期加减、转换、识别并解析环境变量等。服务于应用程序的通用工具模块可统称为可扩展工具,这里不再赘述。
2.3 应用程序
2.3.1 SQL应用
对于SQL应用,只需要创建SQL代码及资源配置即可,应用类为唯一类(已实现),有且只有一个,供所有SQL应用使用,开发者无需关心。如下配置所示,class为所有应用的唯一类名,开发者要关心的是path中的sql代码及conf中该sql所使用的资源大小。
<?xml version=”1.0” encoding=”UTF-8”?>
com.way.app.instance.SqlExecutor
sql文件路径
1G
2
1G
20
/project>
2.3.2 Java应用
对于复杂的数据处理,SQL代码不能满足需求时,我们也支持Java程序的编写,与SQL不同的是,开发者需要创建新的应用类,继承Application父类并实现run方法即可,run方法中开发者只需要关注数据的处理逻辑,对于通用的SparkSession、SparkContext等创建及关闭无需关注,框架还帮助开发者封装了代码的输入、输出逻辑,对于输入类型,框架支持HDFS文件输入、SQL输入等多种输入类型,开发者只需调用相关处理函数即可。
如下为一个简单的Java数据处理应用,从配置文件可以看出,仍需配置资源大小,但与SQL不同的是,开发者需要定制化编写对应的Java类(class参数),以及应用的输入(input参数)和输出参数(output参数),此应用中输入为SQL代码,输出为HDFS文件。从Test类实现可以看出,开发者只需三步走:获取输入数据、逻辑处理、结果输出,即可完成代码编写。
<?xml version="1.0" encoding="UTF-8"?>
<project name="ecommerce_dwd_hanwuji_click_incr_day_domain">
<class>com.way.app.instance.ecommerce.Test</class>
<input>
<type>table</type>
<sql>select
clk_url,
clk_num
from test_table
where event_day='{DATE}'
and click_pv > 0
and is_ubs_spam=0
</sql>
</input>
<output>
<type>afs_kp</type>
<path>test/event_day={DATE}</path>
</output>
<conf>
<spark.executor.memory>2G</spark.executor.memory>
<spark.executor.cores>2</spark.executor.cores>
<spark.driver.memory>2G</spark.driver.memory>
<spark.executor.instances>10</spark.executor.instances>
</conf>
</project>
package com.way.app.instance.ecommerce;
import com.way.app.Application;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.sql.Row;
import java.util.Map;
import org.apache.spark.api.java.function.FilterFunction;
import org.apache.spark.sql.Dataset;
public class Test extends Application {
@Override
public void run() {
// 输入
Map<String, String> input = (Map<String, String>) property.get("input");
Dataset<Row> ds = sparkSession.sql(getInput(input)).toDF("url", "num");
// 逻辑处理(简单的筛选出url带有部分站点的日志)
JavaRDD<String> outRdd = ds.filter((FilterFunction<Row>) row -> {
String url = row.getAs("url").toString();
return url.contains(".jd.com")
|| url.contains(".suning.com")
|| url.contains("pin.suning.com")
|| url.contains(".taobao.com")
|| url.contains("detail.tmall.hk")
|| url.contains(".amazon.cn")
|| url.contains(".kongfz.com")
|| url.contains(".gome.com.cn")
|| url.contains(".kaola.com")
|| url.contains(".dangdang.com")
|| url.contains("aisite.wejianzhan.com")
|| url.contains("w.weipaitang.com");
})
.toJavaRDD()
.map(row -> row.mkString("\001"));
// 输出
Map<String, String> output = (Map<String, String>) property.get("output");
outRdd.saveAsTextFile(getOutPut(output));
}
}
2.3.3 数据回溯应用
数据回溯应用是为解决快速回溯、释放人力而研发的,使用非常便捷,开发者无需重构任务代码,与SQL应用相同,回溯应用类为唯一类(已实现),有且只有一个,供所有回溯任务使用,且支持多种回溯方案。
2.3.3.1 方案设计
在日常回溯过程中发现,一次回溯任务存在严重的时间浪费,无论以何种方式提交任务,都需要经历以下执行环境申请及准备的过程:
在client提交application,首先client向RS申请启动ApplicationMaster
RS先随机找到一台NodeManager启动ApplicationMaster
ApplicationMaster向RS申请启动Executor的资源
RS返回一批资源给ApplicationMaster
ApplicationMaster连接Executor
各个Executor反向注册给ApplicationMaster
ApplicationMaster发送task、监控task执行,回收结果
这个过程占用的时间我们统称为执行环境准备,我们提交任务后,经历如下三个过程:
- 执行环境准备
- 开始执行代码
- 释放资源
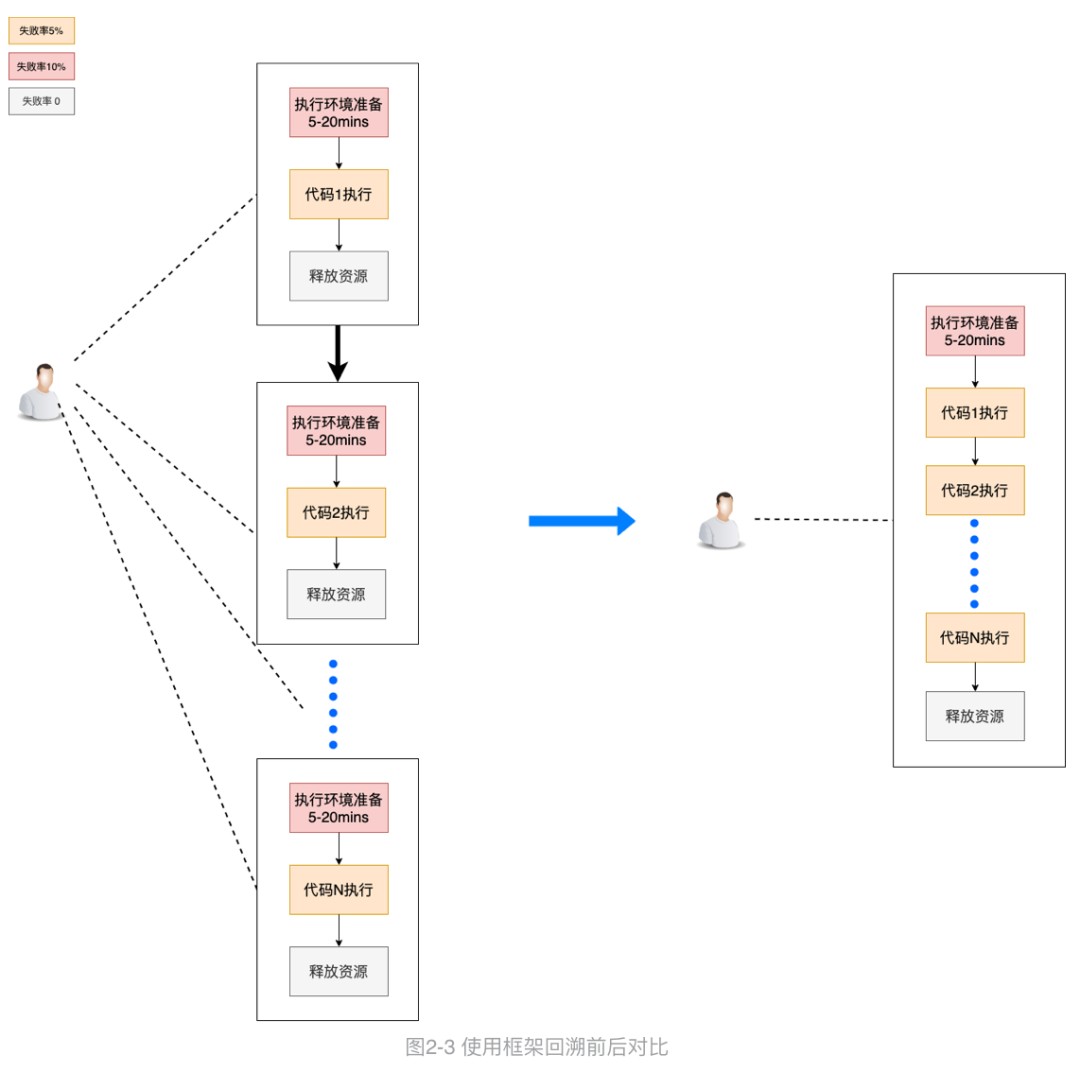
执行环境准备通常会有5-20分钟的等待时间,以队列当时的资源情况上下波动,失败率为10%左右,失败原因由于队列、网络、资源不足等造成的不可抗力因素;代码执行过程通常失败率在5%左右,通常由于节点不稳定、网络等因素导致。离线开发框架回溯应用从节省时间和人力两个方面考虑,设计方案图2-3所示。
从回溯时间方面来看:将所有回溯子任务的第一、第三步的时间压缩为一次,即环境准备及释放各一次,执行多次回溯代码。若开发者回溯任务为30个子任务,则节省的时间为5-20分钟乘29,可见,回溯子任务越多,回溯提效越明显。
从人工介入方面来看,第一,开发者无需额外开发、添加回溯配置即可。第二,离线框架回溯应用启动的任务数量远远小于传统回溯方案,以图2-3为例,该回溯任务为串行回溯方式,使用框架后只需关注一个任务的执行状态,而传统方式则需人工维护N个任务的执行状态。
最后,我们在使用离线开发框架回溯一个一年的串行任务中,代码的执行只需要5分钟左右,我们发现,不使用离线开发框架回溯的任务在最理想的情况下(即最短时间分配到资源、所有子任务均无失败情况、一次可以串行启动365天),需要的时间为2.5天,但使用离线开发框架回溯的任务,在最坏的情况下(即最长时间分配到资源,任务失败情况出现10%),只需要6个小时就可完成,提效90%以上,且基本无需人力关注。
2.3.3.2 功能介绍
断点续回
使用Spark计算,我们在享受其计算带来的飞快速度时,难免会遭遇其中的不稳定性,节点宕机、网络连接失败、资源问题带来的任务失败屡见不鲜,回溯任务动辄几个月、甚至一年,任务量巨大,失败后可以继续从断点处回溯显得尤为重要。在离线框架设计中,记录了任务回溯过程中已成功的部分,任务失败重启后会进行断点续回。
回溯顺序
在回溯任务中,通常我们会根据业务需要确定回溯顺序,如对于有新老用户的增量数据,由于当前的日期数据依赖历史数据,所以我们通常会从历史到现在开始回溯。但没有这种需要时,一般来说,先回溯现在可以快速满足业务方对现在数据指标的了解,我们通常会从现在到历史回溯。在离线框架设计中,开发者可根据业务需要选择回溯顺序。
并行回溯
通常,回溯任务优先级低于例行任务,在资源有限的情况下,回溯过程中不能一次性全部开启,以免占用大量资源影响例行任务,所以离线框架默认为串行回溯。当然在资源充分的时间段,我们可以选择适当的并行回溯。离线开发框架支持一定的并发度,开发者在回溯任务时游刃有余。
2.3.3.3 创建一个回溯任务
回溯应用的使用非常方便,开发者无需新开发代码,使用例行的代码,配置回溯方案即可,如下代码所示,
class参数为回溯应用的唯一类,必填参数,所有回溯任务无需变化。
type参数为回溯应用类型,默认为sql,若应用类型为java,则type值应为java类名。
path参数为回溯代码路径,必填参数,无默认值,通常与例行任务代码相同,无需修改。
limitdate参数为回溯的截止日期,必填参数,无默认值。
startdate参数为回溯开始日期,必填参数,无默认值,若任务进入断点续回或开启并行回溯时,则该参数无效。
order参数为回溯顺序,默认为倒序。当值为1时为正序,为值为-1时为倒序。
distance参数为回溯步长,框架默认为串行回溯,但也支持并行回溯,该参数主要用于支持并行回溯,当该参数存在且值不为-1时,回溯开始日期取值为基准日期。如启动两个并行任务,任务的执行范围为基准日期至基准日期加步长或limitdate,若基准日期加步长后日期大于limitdate,则是取limitdate,否则反之。
file参数为回溯日志文件,必填参数,无默认值,用于记录已回溯成功的日期,当失败再次重启任务时,startdate会以日志文件中日期的下一个日期为准。
conf参数与其他应用相同,为本次回溯任务的资源占用配置。
<?xml version="1.0" encoding="UTF-8"?>
<project name="ecommerce_ads_others_order_retain_incr_day">
<class>com.way.app.instance.ecommerce.Huisu</class>
<type>sql</type>
<path>/sql/ecommerce/ecommerce_ads_others_order_retain_incr_day.sql</path>
<limitdate>20220404</limitdate>
<startdate>20210101</startdate>
<order>1</order>
<distance>-1</distance>
<file>/user/ecommerce_ads_others_order_retain_incr_day/process</file>
<conf>
<spark.executor.memory>1G</spark.executor.memory>
<spark.executor.cores>2</spark.executor.cores>
<spark.executor.instances>30</spark.executor.instances>
<spark.yarn.maxAppAttempts>1</spark.yarn.maxAppAttempts>
</conf>
</project>
三、使用方式
3.1 使用介绍
使用离线框架方式开发时,开发者只需重点关注数据逻辑处理部分,开发完成打包后,提交执行,对于每一个应用主类相同,如前文所述为Application父类,不随应用变化,唯一变化的是父类需要接收的参数,该参数为应用的配置文件的相对路径。
3.2 使用对比
使用离线框架前后对比图如下所示。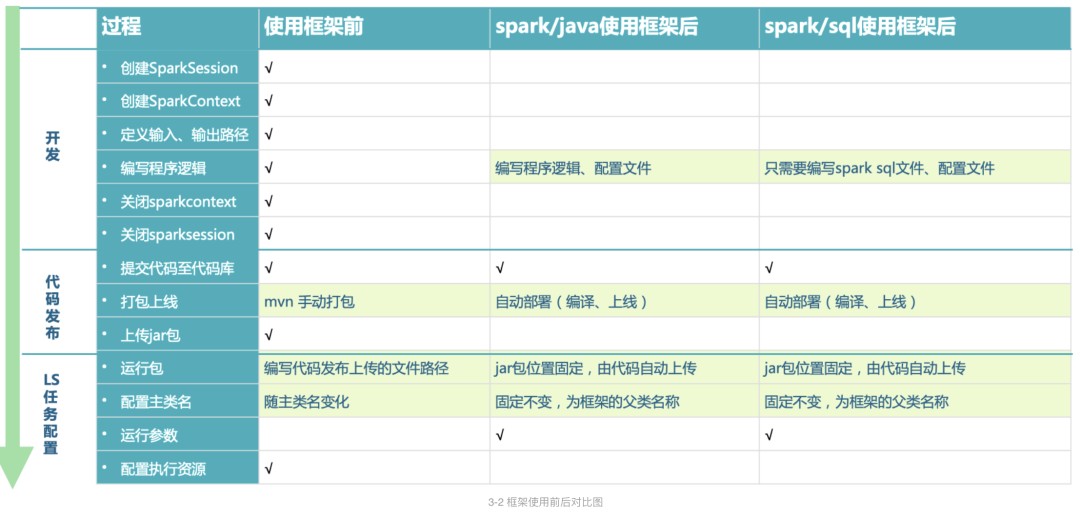
四、展望
目前,离线开发框架仅支持SQL、Java语言代码的开发,但Spark支持的语言远不止这两种,我们需要继续对框架升级支持多语言开发等,让开发者更方便、快速地进行大数据开发。

发表评论
登录后可评论,请前往 登录 或 注册