产业级信息抽取技术开源,为什么Prompt更有效?
2022.05.17 15:48浏览量:1798简介:产业级信息抽取技术开源,为什么Prompt更有效?
PaddleNLP v2.3带来两大重磅能力:
- 通用信息抽取统一建模技术UIE开源!
- 文心大模型ERNIE轻量级模型及一系列产业范例实践开源!
通用信息抽取
在金融、政务、法律、医疗等众多行业中,大量文档信息需要进行数字化及结构化处理,而人工处理方式往往费时费力,且容易产生错误。信息抽取技术能很好地解决这个问题。信息抽取(Information Extraction,IE)指的是从自然语言文本中抽取指定类型的实体、关系、事件等事实信息,并形成结构化数据输出的文本处理技术。
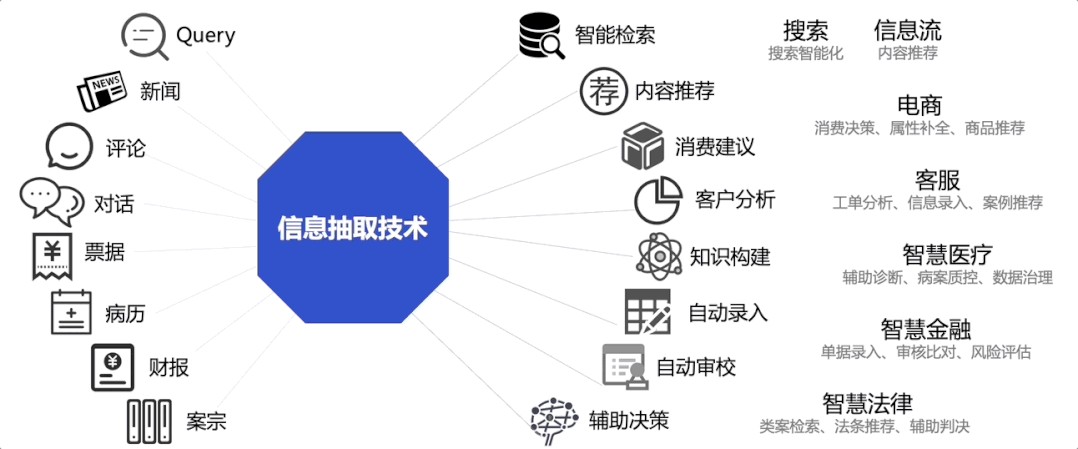
⬆️图1 信息抽取应用场景示例
随着企业智能化转型的加速,信息抽取技术被广泛应用于各行各业的文本处理中。举个例子,在政务场景下,市政工作人员需要处理各类市民电话投诉事件,很难从长篇累牍的投诉内容中一眼就找到需要的信息,而信息抽取技术则可以快速提取出投诉报告中的被投诉方、事件发生时间、地点、投诉事件等信息,使得工作人员能够快速掌握投诉要点,大幅提升处理效率。
信息抽取是NLP技术落地中必不可少的环节,然而当前市面上的信息抽取工具大多基于传统算法构建,偏向学术研究,对实际使用并不友好。产业级信息抽取面临着多种挑战:
领域多样:领域之间知识迁移难度高,如通用领域知识很难迁移到垂类领域,垂类领域之间的知识很难相互迁移;
任务多样:针对实体、关系、事件等不同的信息抽取任务,需要开发不同的模型,开发成本和机器资源消耗都很大;
数据获取&标注成本高:部分领域数据稀缺,难以获取,且领域专业性使得数据标注门槛高。
针对以上难题,中科院软件所和百度共同提出了一个大一统诸多任务的通用信息抽取技术UIE(Universal Information Extraction),在实体、关系、事件和情感等4个信息抽取任务、13个数据集的全监督、低资源和少样本设置下,UIE均取得了SOTA性能,这项成果发表在ACL 2022[1]。
飞桨PaddleNLP结合文心大模型中的知识增强NLP大模型ERNIE 3.0,发挥了UIE在中文任务上的强大潜力,开源了首个面向通用信息抽取的产业级技术方案,不需要标注数据(或仅需少量标注数据),即可快速完成各类信息抽取任务:
多任务统一建模
传统技术方案下,针对不同的抽取任务,需要构建多个IE模型。各个模型单独训练,数据和知识不共享。一个公司可能需要管理众多IE模型。而在UIE方案下,单个模型解决所有信息抽取需求,包括但不限于实体、关系、事件、评价维度、观点词、情感倾向等信息抽取,降低开发成本和机器成本。
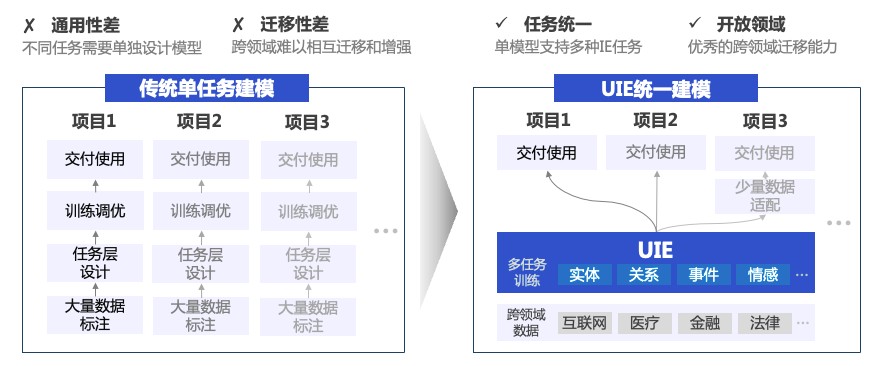
图2 传统方案 vs UIE统一建模方案
UIE是一个大一统诸多任务的开放域信息抽取技术方案,直接上图:
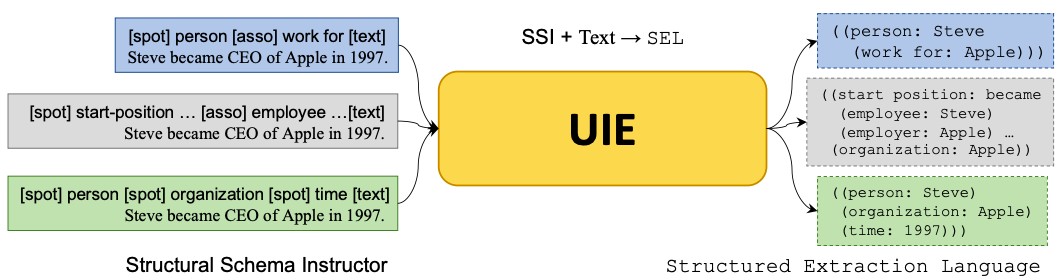
图3 UIE示意图
通过构建结构化模式提示器(SSI,Structural Schema Instructor),UIE能够对不同的信息抽取目标进行统一编码,从而实现多任务的统一建模。
简单来说,UIE借鉴近年来火热的Prompt概念,将希望抽取的Schema信息转换成“线索词”(Schema-based Prompt)作为模型输入的前缀,使得模型理论上能够适应不同领域和任务的Schema信息,并按需抽取出线索词指向的结果,从而实现开放域环境下的通用信息抽取。例如上图中,假如我们希望从一段文本中抽取出“人名”的实体和“工作于”的关系,便可以构造[spot] person[asso] work for的前缀,连接要抽取的目标文本[text] ,作为整体输入到UIE中。
零样本抽取和少样本快速迁移能力
UIE开创了基于Prompt的信息抽取多任务统一建模方式,通过大规模多任务预训练学习的通用抽取能力,可以实现不限定行业领域和抽取目标,零样本快速冷启动。例如在金融领域客户收入证明信息抽取(下图左)中,无需训练数据,即可全部抽取正确。针对复杂抽取需求,标注少量数据微调即完成任务适配,大大降低标注门槛和成本。例如医疗报告结构化(下图中)和报销单信息抽取(下图右)中,仅标注了几条样本,F1值就取得大幅提升,真是太实用了!

图4 实体抽取零样本和小样本效果展示
除实体抽取任务外,在金融、医疗、互联网三大自建测试集的关系、事件抽取任务上进行实验,标注少样本也可带来显著的效果提升,尤其在金融、医疗等专业垂类领域上效果突出,例如,在金融领域的事件抽取任务上,仅仅标注5条样本,F1值提升了25个点!也就是说,即使模型在某些case或某些场景下表现欠佳,人工标几个样本,丢给模型后就会有大幅的效果提升。
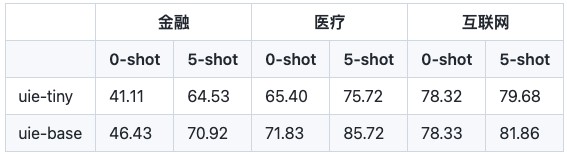
说明:0-shot表示无训练数据直接预测,5-shot表示基于5条标注数据进行模型微调。uie-tiny和uie-base分别表示6层和12层的UIE模型。
UIE强大的小样本学习能力是行业大规模落地的关键,目前已通过了大量的业务验证:
金融领域
某银行使用UIE实现了智能营销场景下的标签抽取和内容推荐系统,在线上推荐业务中,AUC提升14%。医疗领域
UIE实现对电子病历、医疗书籍进行症状、疾病、检验指标等关键信息抽取,助力百度智慧医疗业务迅速杀入国内第一梯队。法律领域
抽取裁判文书中的犯罪事件主体、事件经过、罪名等信息,建立刑事大数据分析系统,仅用60条数据进行模型微调,F1达到94.36%。政务领域
识别市民投诉电话中的投诉对象、地点等关键信息,快速聚合相似事件、智能分发,有效提升了事件处理率,目前,UIE已上线到多个城市的政务系统中。电商零售领域
某大型家电零售企业借助UIE实现了评论观点抽取、情感倾向预测,搭建了完整的服务智能化评分系统,准确率和召回率均达到90%+。服务评分的智能化,使得该企业客服运营人力减少40%,负面问题处理率从60%飙升至100%,售后的差评率整体降低70%。
便捷易用
这么酷炫的技术能力,如何快速应用到业务中呢?
通过调用paddlenlp.Taskflow API即可实现零样本(zero-shot)抽取多种类型的信息。话不多说,直接上代码,上效果!
# 实体抽取
from pprint import pprint
from paddlenlp import Taskflow
schema = ['时间', '选手', '赛事名称'] # Define the schema for entity extraction
ie = Taskflow('information_extraction', schema=schema)
pprint(ie("2月8日上午北京冬奥会自由式滑雪女子大跳台决赛中中国选手谷爱凌以188.25分获得金牌!")) # Better print results using pprint
>>>
[{'时间': [{'end': 6, 'probability': 0.9857378532924486, 'start': 0, 'text': '2月8日上午'}],
'赛事名称': [{'end': 23,'probability': 0.8503089953268272,'start': 6,'text': '北京冬奥会自由式滑雪女子大跳台决赛'}],
'选手': [{'end': 31,'probability': 0.8981548639781138,'start': 28,'text': '谷爱凌'}]}]
仅用三行代码就实现了精准实体抽取!
再来试试更困难的事件抽取任务,看看效果如何?
# 事件抽取
schema = {'地震触发词': ['地震强度', '时间', '震中位置', '震源深度']} # Define the schema for event extraction
ie.set_schema(schema) # Reset schema
ie('中国地震台网正式测定:5月16日06时08分在云南临沧市凤庆县(北纬24.34度,东经99.98度)发生3.5级地震,震源深度10千米。')
>>>
[{'地震触发词':
[{'end': 58,'probability': 0.9987181623528585,'start': 56,'text': '地震',
'relations':
{'地震强度': [{'end': 56,'probability': 0.9962985320905915,'start': 52,'text': '3.5级'}],
'时间': [{'end': 22,'probability': 0.9882578028575182,'start': 11,'text': '5月16日06时08分'}],
'震中位置': [{'end': 50,'probability': 0.8551417444021787,'start': 23,'text': '云南临沧市凤庆县(北纬24.34度,东经99.98度)'}],
'震源深度': [{'end': 67,'probability': 0.999158304648045,'start': 63,'text': '10千米'}]}
}]
}]
同样易用而精准!
对于复杂目标,可以标注少量数据(Few-shot)进行模型训练,以进一步提升效果。PaddleNLP打通了从数据标注-训练-部署全流程,方便大家进行定制化训练。是不是迫不及待想试用一下?
戳阅读原文链接即可体验
⭐ 欢迎STAR收藏 ⭐
https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/uie
文心大模型ERNIE轻量级模型开源
PaddleNLP开源的信息抽取能力背后,除了大一统信息抽取技术UIE外,还得益于文心产业级知识增强大模型——文心ERNIE 3.0的底座支撑。我们知道,知识对于信息抽取任务至关重要。而文心ERNIE3.0不仅参数量大,还吸纳了千万级别实体的知识图谱,可以说是中文NLP方面最有“知识量”的SOTA底座。
文心ERNIE 3.0在机器阅读理解、文本分类、语义相似度计算等60多项任务中取得最好效果,并在30余项小样本和零样本任务上刷新基准。通过百度首创的在线蒸馏技术,通过“一师多徒”、“多代传承”的方式实现了效果显著的模型压缩方案。
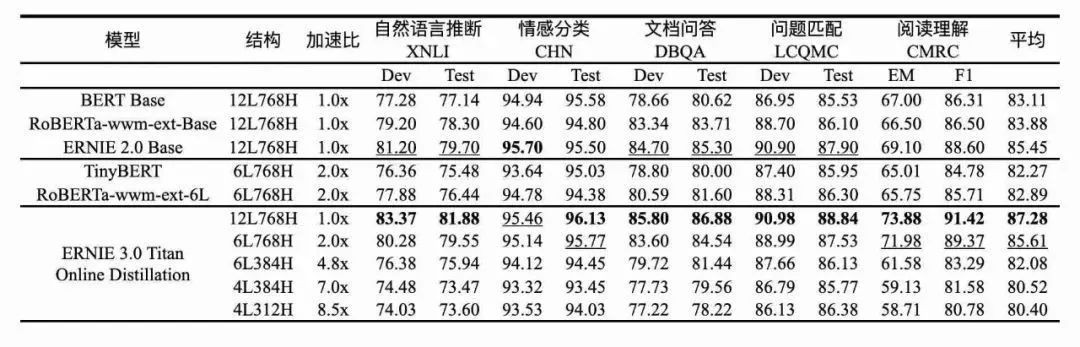
近日,这个6层中文SOTA预训练模型也开源了!此外,PaddleNLP v2.3还提供了该模型完整的推理部署工具链,包含PaddleSlim裁剪量化压缩方案、Paddle Inference CPU、GPU高性能推理部署和Paddle Serving服务化部署能力,可以做到精度无损的情况下实现8.8倍的加速提升,一站式满足多场景的产业部署需求。
为了推动NLP技术快速大规模落地到产业界,PaddleNLP还针对产业高频场景,打通了数据准备-模型训练-模型调优-推理部署端到端全流程,推出一系列基于文心大模型的产业范例:如语音工单信息抽取、说明书问答、产品评论情感分析、语义检索系统等。
ERNIE 3.0轻量级模型链接:
https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/ernie-3.0
看到这里的小伙伴一定发现了,PaddleNLP其实是一个集前沿预训练模型、开箱即用工具集和产业系统方案于一身的NLP万能法宝。自开源以来,PaddleNLP不断获得科研和产业界朋友的认可和喜爱,频频现身GitHub和Papers With Code榜单。

发表评论
登录后可评论,请前往 登录 或 注册