【技术白皮书】第一章:OCR智能文字识别新发展——深度学习的文本信息抽取
作者:合合技术团队2022.08.08 11:01浏览量:652简介:OCR智能文字识别新发展——深度学习的文本信息抽取

本文篇幅较长,建议配合目录食用分次阅读。
1.1技术背景——什么是基于深度学习的文本信息抽取
信息抽取 (Information Extraction) 是把原始数据中包含的信息进行结构化处理,变成表格一样的组织形式。输入信息抽取系统的是原始数据,输出的是固定格式的信息点,即从原始数据当中抽取有用的信息。信息抽取的主要任务是将各种各样的信息点从原始数据中抽取出来。然后以统一的形式集成在一起,方便后序的检索和比较。由于能从自然语言中抽取出信息框架和用户感兴趣的事实信息,无论是在信息检索、问答系统还是在情感分析、文本挖掘中,信息抽取都有广泛应用。随着深度学习在自然语言处理领域的很多方向取得了巨大成功,循环神经网络(RNN)和卷积神经网络(CNN)也被用于信息抽取研究领域,基于深度学习的信息抽取技术也应运而生。
信息抽取的三大任务:
- 实体抽取(Named Entity Recognition,NER)
- 关系抽取 (Relation extraction,RE)
- 事件抽取 (Event extraction, EE)
- 信息抽取技术的评价指标主要是:
针对特定领域的抽取结果,一般通过计算对应的准确率(Precision)、召回率(Recall)和F1值来评价。对应的计算为:
- 准确率(precision):是提取出的信息中正确预测的信息的数量与全部提取出的信息数量的比。
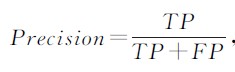 ragmentbodyhtml.jpg">
ragmentbodyhtml.jpg">
- 召回率(recall): 是提取出来的正确预测的信息与测试数据集所有信息的比。
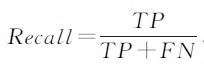
- F1值是准确率和召回率的调和平均值
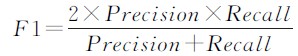
其中,数据有2种类型:测试集数据和预测结果数据,对一批测试数据进行预测,一般可以将抽取的结果分成4种:
(1)TP (true positive),原本是正类,预测结果为正类(正确预测为正类)。
(2)FP(false positive),原本是负类,预测结果为正类(错误预测为正类)。
(3)TN (true negative),原本是负类,预测结果为负类(正确预测为负类)。
(4)FN (false negative),原本是正类,预测结果为负类(错误预测为负类)。
1.1.1基于深度学习的实体抽取
实体抽取即命名实体识别(Named Entity Recognition,简称NER),是指识别文本中具有特定意义的实体,主要包括人名、位置、组织、专有名词等。
通常包括两部分:
(1)实体边界识别;(2) 确定实体类别(人名、地名、机构名或其他)
NER是信息检索、问答、机器翻译等各种下游应用的重要预处理步骤。
早期的NER系统在设计特定领域的特性和规则时,在耗费大量人工的情况下,取得了良好地性能。近年来,通过非线性处理实现连续实值向量表示和语义合成的深度学习已被应用于NER系统,产生了最先进的性能。
随着深度学习技术的发展,CNN、RNN、LSTM-CRF、GRU等方法被应用到NER领域。19年BERT出现之后,BERT-BiLSTM-CRF的模型成为NER领域最合适的模型。
中文NER已发展十几年时间,但由于汉字的一些特性,中文NER仍要比英文NER复杂的多。
中文命名实体识别的难点主要存在于:
1.中文文本没有类似英文文本中空格之类的显式标示词的边界标示符,命名实体识别的第一步就是确定词的边界,即分词。
2.中文分词和命名实体识别互相影响。
3.除了英语中定义的实体,外国人名译名和地名译名是存在于汉语中的两类特殊实体类型。
4.现代中文文本,尤其是网络中文文本,常出现中英文交替使用,这时汉语命名实体识别的任务还包括识别其中的英文命名实体。
5.不同的命名实体具有不同的内部特征,不可能用一个统一的模型来刻画所有的实体内部特征。
1.1.2基于深度学习的关系抽取
关系抽取是信息抽取的一个重要子任务。关系抽取就是通过对原始数据建模,从原始数据中自动抽取实体对之间的语义关系,提取出有效的语义关系。
关系抽取将文本中的无结构化的信息转化为结构化的信息存储在知识库中,为之后的智能检索和语义分析提供了一定的支持和帮助。研究人员利用关系抽取技术,从无结构化的自然语言文本中抽取出格式统一的实体关系,便于海量数据的处理;将分析出的多个实体之间的语义关系和实体进行关联,促进了知识库的自动构建;对用户查询意图进行理解和分析,提高了搜索引擎的检索效率等。综上所述,关系抽取技术不仅具有理论意义,还具有十分广阔的应用前景
基于深度学习的关系抽取分为有监督的方法和远程监督的方法,其中有监督的方法又可以分为流水线(pipeline)和联合学习(joint learning)的方法。在众多方法中表现较好的方法有:PCNN+MLL、LSTM以及基于PCNN的注意力机制的方法等。
相比于模式匹配和传统机器学习的方法,深度学习方法优势明显。基于深度学习的方法可以在神经网络模型中自动学习特征,将低层特征进行组合,形成更加抽象的高层特征,用来寻找数据的分布式特征表示。传统方法提取的特征和精心设计的内核都使用了预先存在的 NLP 系统,会导致下游各种模块的错误累积。而深度学习的方法能够避免人工特征选择等步骤,减少并改善特征抽取过程中的误差积累问题。
中文文本的关系抽取起步较晚,而且中文与英文等语言相差较大。中文语料库的建立需要经过中文分词、词性标注和句法分析等预处理,并且在处理的过程中会存在很多错误,这就导致中文实体关系抽取的效果也略差于英文关系抽取。
因此,中文领域的实体关系抽取研究具有较大的挑战性,主要存在3个特殊性:
1.中文的单元词汇边界模糊,缺少英文文本中 空格这样明确的分隔符,也没有明显的词形变换特征,因此容易造成许多边界歧义,从而加大了关系抽取的难度。
2.中文触发词抽取难度较大,且数目过多。中文自然语言处理底层技术研究还不够成熟,导致错误的级联。如在长句子的句法分析上,ACE 语料中大量出现词语个数大于30的长句子,句法分析效果较差。此外,中文触发词数目过多,导致关系抽取召回率较低。通过对语料的分析发现,由于中文词汇表达的多义性,对同一类事件,中文触发词的个数要远大于英文。
3.中文存在多义性、句式复杂表达灵活、多省略等特点。不同领域中的同一个词语表示的意思并不一样,或者同一种语义可能存在多种表达形式。此外,由于互联网的快速发展,网络文本中的文字描述更加个性化,许多词语具有不同意义,中文命名实体在不同语境下被赋予了不同的意义(如高富帅、黑天鹅等),使得关系类型的识别更为困难。
1.1.3基于深度学习的事件抽取
在信息抽取IE ( Information Extraction) 中,事件作为一种特定的信息形式,是指在某一时间、某一地点发生的某件事的具体发生,涉及一个或多个参与者,通常可以描述为状态的变化,一般是句子级的。事件抽取任务旨在将此类事件信息从非结构化纯文本中提取为结构化形式,主要描述现实世界中发生的事件的“谁(who)、何时(when)、何地(where)、什么(what)、为什么(why)”和“如何(how)”。 在应用方面,该任务便于人们检索事件信息和分析人们的行为,引发信息检索、推荐、、智能问答、知识图谱构造和其他应用程序。
根据ACE2005评估会议描述,组成事件的各元素包括: 触发词(event trigger)、事件类型(event type)、论元(event argument)及论元角色(argument role)。事件抽取任务可分解为4 个子任务: 触发词识别、事件类型分类、论元识别和角色分类任务。其中,触发词识别和事件类型分类可合并成事件识别任务。论元识别和角色分类可合并成论元角色分类任务。事件识别判断句子中的每个单词归属的事件类型,是一个基于单词的多分类任务。角色分类任务则是一个基于词对的多分类任务,判断句子中任意一对触发词和实体之间的角色关系。
近年来表现较好的基于深度学习的事件抽取方法主要有:DMCNN(Event Extraction via Dynamic Multi-Pooling Convolutional Neural Networks)、JRNN(Joint Event Extraction via Recurrent Neural Networks)、PLMEE(Pre-trained Language Model based Event Extractor)等
相比于模式匹配和传统机器学习的方法,深度学习方法优势明显:
1.减少对外部 NLP 工具的依赖 , 甚至不依赖 NLP 工具 , 建立成端对端的系统
2.使用词向量作为输入,蕴含更为丰富的语义特征
3.能自动提取句子特征,避免了人工特征选择和设计的繁琐工作
4.学习更多抽象的数学特征,并使数据具有更好的特征表达,从而实现文本事件的有效抽取
信息抽取技术已有多年的研究发展并取得了丰硕的成果,但如今还是有不少的挑战需要攻克,合合信息认为以下几点会是信息抽取技术发展的重要方向:
端到端的模型,基于深度学习的端到端自主学习模型是一个值得研究和探索的方向
One-shot甚至zero-shot的学习模型,在符合训练标准的数据样本极少的情况下仍能训练出高效的模型
迁移学习的能力,使用当前现有的模型去完成新的文本理解任务或是学习完全没见过的数据样本,有效地将知识从一个领域转移到另一个领域。
参考文献:
Jing Li, Aixin Sun, Jianglei Han, and Chenliang Li,“A Survey on Deep Learning for Named Entity Recognition” IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING, 2020
Animashree Anandkumar,“Deep Active Learning for Named Entity Recognition” in Proceedings of the 2nd Workshop on Representation Learning for NLP, pages 252–256,
Arya Roy “Recent Trends in Named Entity Recognition (NER)” arXiv:2101.11420v1 [cs.CL] 25 Jan 2021
李冬梅,张扬,李东远,林丹琼 .实体关系抽取方法研究综述[J]. 计算机研究与发展,2020,57(7)
Yanyao Shen,Hyokun Yun ,Zachary C. Lipton ,Yakov Kronrod and Shantanu Kumar,“A Survey of Deep Learning Methods for Relation Extraction” arXiv:1705.03645v1 [cs.CL] 10 May 2017
Qian Li, Jianxin Li, Jiawei Sheng, Shiyao Cui, Jia Wu,Yiming Hei, Hao Peng,Shu Guo, Lihong Wang, Amin Beheshti, and Philip S ,“A Compact Survey on Event Extraction: Approaches and Applications” IEEE TRANSACTIONS ON NEURAL NETWORKS AND LEARNING SYSTEMS, VOL. 14, NO. 9, NOVEMBER 2021
————————————————
版权声明:本文为CSDN博主「合合技术团队」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/INTSIG/article/details/125297673
相关文章推荐
发表评论
关于作者

- 被阅读数
- 被赞数
- 被收藏数
登录后可评论,请前往 登录 或 注册