Apache Calcite 框架原理入门和生产应用
2022.08.08 15:00浏览量:2397简介:Calcite 是一个用于优化异构数据源的查询处理的基础框架。
1. 简介
Calcite 是什么?如果用一句话形容 Calcite,Calcite 是一个用于优化异构数据源的查询处理的基础框架。
最近十几年来,出现了很多专门的数据处理引擎。例如列式存储 (HBase)、流处理引擎 (Flink)、文档搜索引擎 (Elasticsearch) 等等。这些引擎在各自针对的领域都有独特的优势,在现有复杂的业务场景下,我们很难只采用当中的某一个而舍弃其他的数据引擎。当引擎发展到一定成熟阶段,为了减少用户的学习成本,大多引擎都会考虑引入 SQL 支持,但如何避免重复造轮子又成了一个大问题。基于这个背景,Calcite 横空出世,它提供了标准的 SQL 语言、多种查询优化和连接各种数据源的能力,将数据存储以及数据管理的能力留给引擎自身实现。同时 Calcite 有着良好的可插拔的架构设计,我们可以只使用其中一部分功能构建自己的 SQL 引擎,而无需将整个引擎依托在 Calcite 上。因此 Calcite 成为了现在许多大数据框架 SQL 引擎的最佳方案。我们计算引擎组也基于 Calcite 实现了一个自用的 SQL 校验层,当用户提交 Flink SQL 作业时需要先进过一层语义校验,通过后再利用校验得到的元数据构建模板任务提交给 Flink 引擎执行。
2. 核心架构
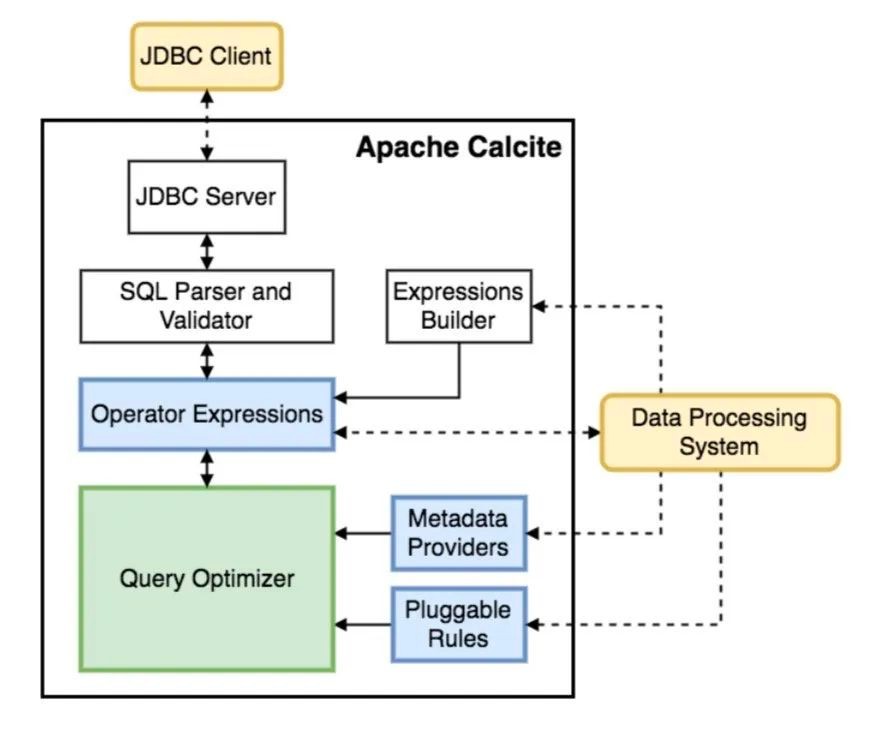
中间的方框总结了 Calcite 的核心结构,首先 Calcite 通过 SQL Parser 和 Validator 将一个 SQL 查询解析得到一个抽象语法树 (AST, Abstract Syntax Tree),由于 Calcite 不包含存储层,因此它提供了另一种定义 table schema 和 view 的机制—— Catalog 作为元数据的存储空间(另外 Calcite 提供了 Adaptor 机制连接外部的存储引擎获取元数据,这部分内容不在本文范围内)。之后,Calcite 通过优化器生成对应的关系表达式树,根据特定的规则进行优化。优化器是 Calcite 最为重要的一部分逻辑,它包含了三个组件:Rule、MetadataProvider(Catalog)、Planner engine,这些组件在文章后续都会有具体的讲解。
通过架构图我们可以看出,Calcite 最大的特点(优势)是它将 SQL 的处理、校验和优化等逻辑单独剥离出来,省略了一些关键组件,例如,数据存储,处理数据的算法以及用于存储元数据的存储库。其次 Calcite 做得最出色的地方则是它的可插拔机制,每个大数据框架都可以选择 Calcite 的整体或部分模块建立自己的 SQL 处理引擎,如 Hive 自己实现了 SQL 解析,只使用了 Calcite 的优化功能,Storm 以及 Flink 则是完全基于 Calcite 建立了 SQL 引擎,具体如下表所示:
2.1 四个阶段
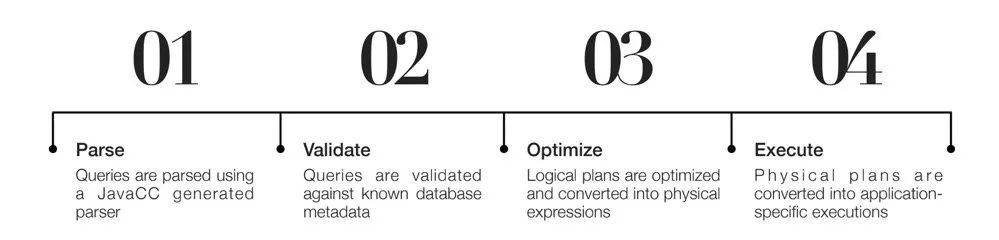
Calcite 框架的运行主要分四个阶段
- Parse:使用 JavaCC 生成的解析器进行词法、语法分析,得到 AST;
- Validate:结合元数据进行校验;
- Optimize:将 AST 转化为逻辑执行计划(tree of relational expression),并根据特定的规则(heuristic 或 cost-baesd)进行优化;
- Execute:将逻辑执行计划 转化成引擎特有的执行逻辑,比如 Flink 的 DataStream。
考虑到第 4 步是一个和引擎耦合的流程,下面的内容我们主要聚焦于前三个阶段。
2.2 四大组件
围绕着这个运行流程,Apache Calcite 最核心的框架可以拆分为四个组件
- SQL Parser:将符合语法规则的 SQL 转化成 AST(Sql text → SqlNode),Calcite 提供了默认的 parser,但也可以基于 JavaCC 生成自定义的 parser;
- Catalog:定义记录了 SQL 的 metadata 和 namespace,方便后续的访问和校验;
- SQL Validator:结合 Catalog 提供的元数据校验 AST,具体的实现都在 SqlValidatorImpl 中;
- Query Optimizer:这块概念较多,首先需要将 AST 转化成逻辑执行计划(即 SqlNode → RelNode),其次使用 Rules 优化逻辑执行计划。
3. SQL parser
上文提到,SQL Parser 的作用是将 SQL 文本切割成一个个 token 并生成 AST,每个 token 在 Calcite 中由 SqlNode 表示(即代表 AST 的一个个结点),SqlNode 也可以通过 unparse 方法重新生成 SQL 文本。为了方便说明,我们引入一个 SQL 文本,通过观察它在 Calcite 中的变化来摸清 Calcite 的原理,后续的校验、优化我们也会根据具体场景引入不同的 SQL 文本进行分析。
INSERT INTO sink_table SELECT s.id, name, age FROM source_table s JOIN dim_table d ON s.id=d.id WHERE s.id>1;
3.1 SqlNode
SqlNode 是 AST 所有结点的抽象,它可能具体代表某个运算符、常量或标识符等等,以 SqlNode 基类衍生出许多实现类如下:
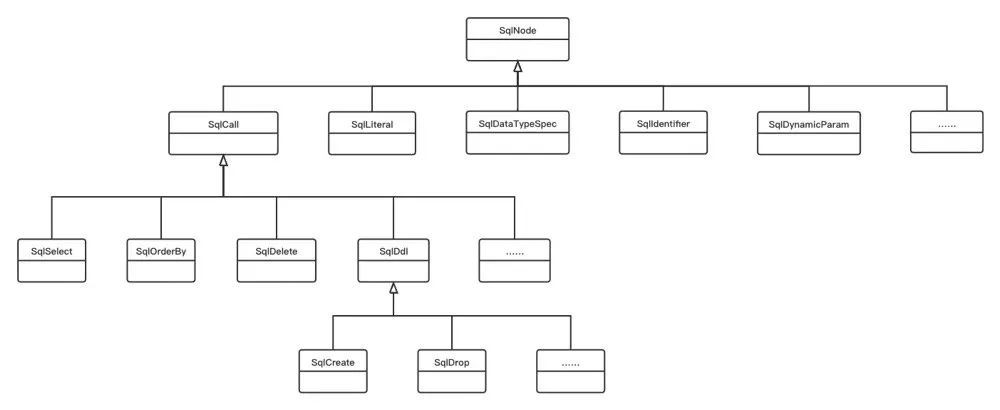
INSERT 被 Parser 解析后会转化成一个 SqlInsert,而 SELECT 则转化成 SqlSelect,以上述的 SQL 文本为例,解析后会得到如下结构:
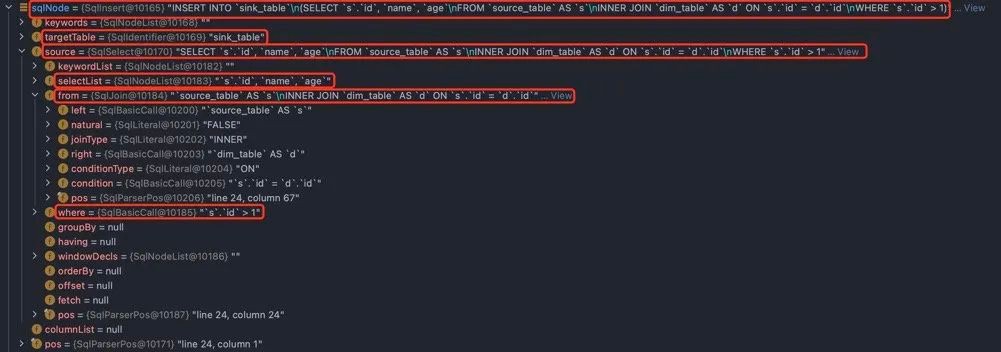
下面根据该图讲解 SqlNode 中一些较常见的核心结构。
3.1.1 SqlInsert
首先这是个动作为 INSERT 的 DDL 语句,因此整个 AST root 是一个 SqlInsert,SqlInsert 中有个有许多成员变量分别记录了这个 INSERT 语句的不同组成部分:
- targetTable:记录要插入的表,即 sink_table,在 AST 中表示为 SqlIdentifier
- source:标识了数据源,该 INSERT 语句的数据源是一个 SELECT 子句,在 AST 中表示为 SqlSelect;
- columnList:要插入的列,由于该 Insert 语句未显式指定所以是 null,会在校验阶段动态计算得到。
3.1.2 SqlSelect
SqlSelect 是该 INSERT 语句的数据源部分被 Parser 解析生成的部分,它的核心结构如下:
- selectList:指 SELECT 关键字后紧跟的查询的列,是一个 SqlNodeList,在该例中由于显式指定了列且无任何函数调用,因此 SqlNodeList 中是三个 SqlIdentifier;
- from:指 SELECT 语句的数据源,该例中的数据源是表 source_table 和 dim_table 的连接,因此这里是一个 SqlJoin;
- where:指 WHERE 子句,是一个关于条件判断的函数调用,SqlBasicCall,它的操作符是一个二元运算符 >,被解析为 SqlBinaryOperator,两个操作数分别是 s.id(SqlIdentifier) 和 1(SqlNumberLiteral)。
3.1.3 SqlJoin
SqlJoin 是该 SqlSelect 语句的 JOIN 部分被 Parser 解析生成的部分:
- left:代表 JOIN 的左表,由于我们用了别名,因此这里是一个 SqlBasicCall,它的操作符是 AS,被解析为 SqlAsOperator,两个操作数分别是 source_table(SqlIdentifier) 和 s(SqlIdentifier);
- joinType:代表连接的类型,所有支持解析的 JOIN 类型都定义在 org.apache.calcite.sql.JoinType 中,joinType 被解析为 SqlLiteral,它的值即是 JoinType.INNER;
- right:代表 JOIN 的右表,由于我们用了别名,因此这里是一个 SqlBasicCall,它的操作符是 AS,被解析为 SqlAsOperator,两个操作数分别是 dim_table(SqlIdentifier) 和 d(SqlIdentifier);
- conditionType:代表 ON 关键字,是一个 SqlLiteral;
- condition:与 3.1.2 的 where 相似,是一个关于条件判断的函数调用,SqlBasicCall,它的操作符是一个二元运算符 =,被解析为 SqlBinaryOperator,两个操作数分别是 s.id(SqlIdentifier) 和 d.id(SqlNumberLiteral)。
3.1.4 SqlIdentifier
SqlIdentifier 翻译为标识符,标识 SQL 语句中所有的表名、字段名、视图名(* 也会识别为一个 SqlIdentifier),基本所有与 SQL 相关的解析校验,最后解析都到 SqlIdentifier 这一层结束,因此也可以认为 SqlIdentifier 是 SqlNode 中最基本的结构单元。SqlIdentifier 有一个字符串列表 names 存储实际的值,用列表示因为考虑到全限定名,如 s.id,在 names 会占用两个元素格子,names[0] 存 s,names[1] 存 id。
3.1.5 SqlBasicCall
SqlBasicCall 包含所有的函数调用或运算,如 AS、CAST 等关键字和一些运算符,它有两个核心成员变量:operator 和 operands,分别记录这次函数调用/运算的操作符和操作数,operator 通过 SqlKind 标识其类型。
3.2 JavaCC
Calcite 没有自己造词法、语法分析的轮子,而是采用了主流框架 JavaCC,并结合了 Freemarker 模板引擎来生成 LL(k)parser,JavaCC(Java Compiler Compiler)是一个用Java语言写的一个Java语法分析生成器,它所产生的文件都是纯Java代码文件。用户只要按照 JavaCC 的语法规范编写 JavaCC 的源文件,然后使用 JavaCC 插件进行 codegen,就能够生成基于Java语言的某种特定语言的分析器。
Freemarker 是一个模板渲染引擎,通过它建立内置模板,结合自定义的拓展语法可以快速生成我们想要的语法描述文件。
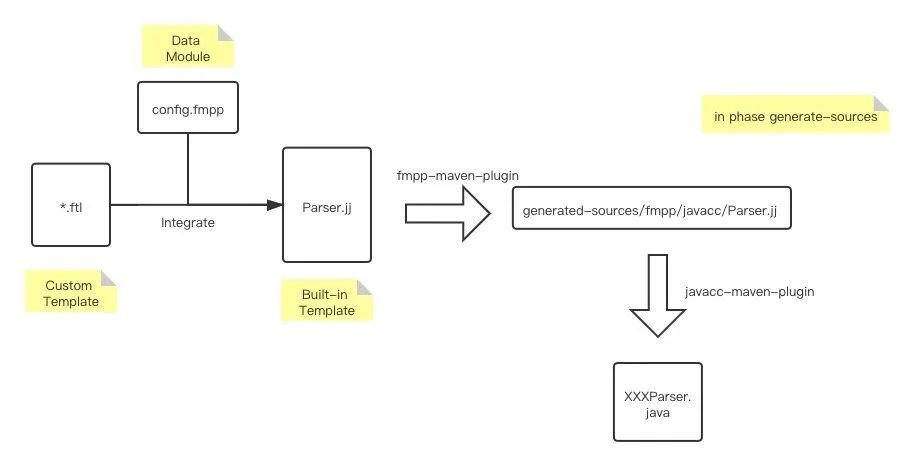
在 Calcite 中,Parser.jj 是 Calcite 内置的模板文件,.ftl 为自定义拓展模板,config.fmpp 用于声明数据模型,首先 Calcite 通过 fmpp-maven-plugin 插件生成最终的 Parser.jj 文件,再利用 javacc-maven-plugin 插件生成对应的 Java 实现代码,具体的流程图如下:
4. Catalog
Catalog 保存着整个 SQL 的元数据和命名空间,元数据的校验都需要通过 Catalog 组件进行,Catalog 中最关键的几个结构如下: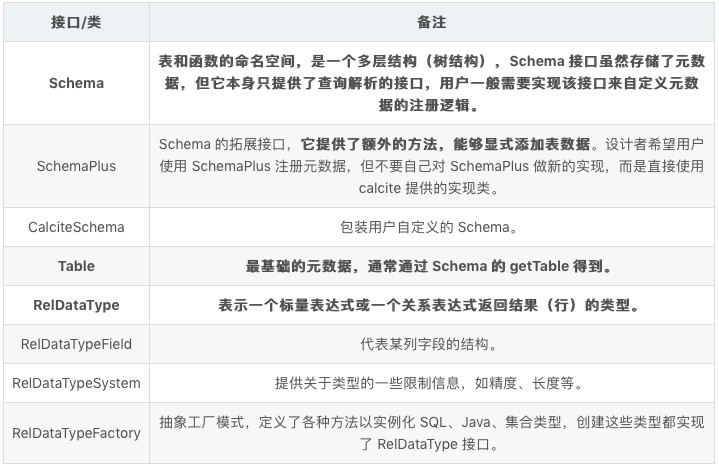
这些结构大致可以分为三类:
- 元数据管理模式和命名空间;
- 表元数据信息;
- 类型系统。
Calcite 的 Catalog 结构复杂,但我们可以从这个角度来理解 Catalog,它是 Calcite 在不同粒度上对元数据所做的不同级别的抽象。首先最细粒度的是 RelDataTypeField,代表某个字段的名字和类型信息,多个 RelDataTypeField 组成了一个 RelDataType,表示某行或某个标量表达式的结果的类型信息。再之后是一个完整表的元数据信息,即 Table。最后我们需要把这些元数据组织存储起来进行管理,于是就有了 Schema。
- SQL validator
Calcite 提供的 validator 流程极为复杂,但概括下来主要做了这么一件事,对每个 SqlNode 结合元数据校验是否正确,包括:
- 验证表名是否存在;
- select 的列在对应表中是否存在,且该匹配到的列名是否唯一,比如 join 多表,两个表有相同名字的字段,如果此时 select 的列不指定表名就会报错;
- 如果是 insert,需要插入列和数据源进行校验,如列数、类型、权限等;
- ……
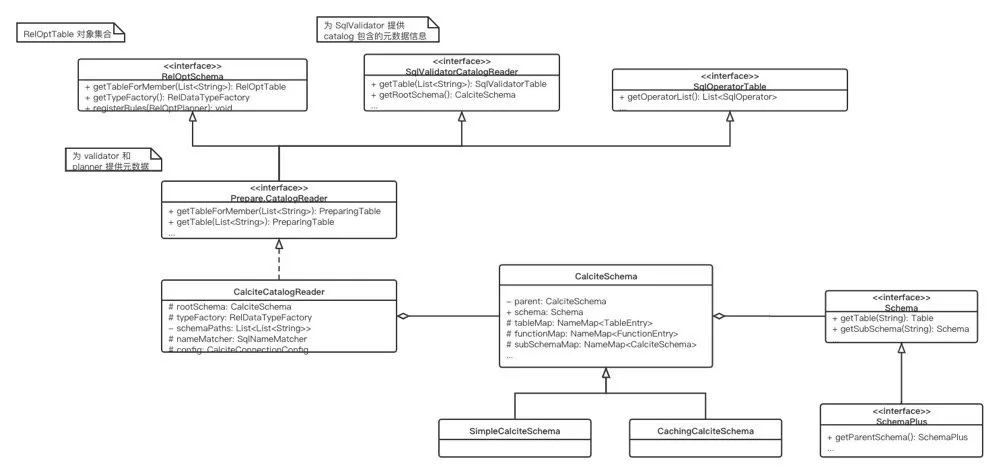
Calcite 提供的 validator 和前面提到的 Catalog 关系紧密,Calcite 定义了一个 CatalogReader 用于在校验过程中访问元数据 (Table schema),并对元数据做了运行时的一些封装,最核心的两部分是 SqlValidatorNamespace 和 SqlValidatorScope。
- SqlValidatorNamespace:描述了 SQL 查询返回的关系,一个 SQL 查询可以拆分为多个部分,查询的列组合,表名等等,当中每个部分都有一个对应的 SqlValidatorNamespace。
- SqlValidatorScope:可以认为是校验流程中每个 SqlNode 的工作上下文,当校验表达式时,通过 SqlValidatorScope 的 resolve 方法进行解析,如果成功的话会返回对应的 SqlValidatorNamespace 描述结果类型。
在此基础上,Calcite 提供了 SqlValidator 接口,该接口提供了所有与校验相关的核心逻辑,并提供了内置的默认实现类 SqlValidatorImpl 定义如下:
public class SqlValidatorImpl implements SqlValidatorWithHints {
// ...
final SqlValidatorCatalogReader catalogReader;
/**
* Maps {@link SqlNode query node} objects to the {@link SqlValidatorScope}
* scope created from them.
*/
protected final Map<SqlNode, SqlValidatorScope> scopes =
new IdentityHashMap<>();
/**
* Maps a {@link SqlSelect} node to the scope used by its WHERE and HAVING
* clauses.
*/
private final Map<SqlSelect, SqlValidatorScope> whereScopes =
new IdentityHashMap<>();
/**
* Maps a {@link SqlSelect} node to the scope used by its GROUP BY clause.
*/
private final Map<SqlSelect, SqlValidatorScope> groupByScopes =
new IdentityHashMap<>();
/**
* Maps a {@link SqlSelect} node to the scope used by its SELECT and HAVING
* clauses.
*/
private final Map<SqlSelect, SqlValidatorScope> selectScopes =
new IdentityHashMap<>();
/**
* Maps a {@link SqlSelect} node to the scope used by its ORDER BY clause.
*/
private final Map<SqlSelect, SqlValidatorScope> orderScopes =
new IdentityHashMap<>();
/**
* Maps a {@link SqlSelect} node that is the argument to a CURSOR
* constructor to the scope of the result of that select node
*/
private final Map<SqlSelect, SqlValidatorScope> cursorScopes =
new IdentityHashMap<>();
/**
* The name-resolution scope of a LATERAL TABLE clause.
*/
private TableScope tableScope = null;
/**
* Maps a {@link SqlNode node} to the
* {@link SqlValidatorNamespace namespace} which describes what columns they
* contain.
*/
protected final Map<SqlNode, SqlValidatorNamespace> namespaces =
new IdentityHashMap<>();
// ...
}
可以看到 SqlValidatorImpl 当中有许多 scopes 映射 (SqlNode -> SqlValidatorScope) 和 namespaces (SqlNode -> SqlValidatorNamespace),校验其实就是在一个个 SqlValidatorScope 中校验 SqlValidatorNamespace 的过程,另外 SqlValidatorImpl 有一个成员 catalogReader,也就是上面说到的 SqlValidatorCatalogReader,为 SqlValidatorImpl 提供了访问元数据的入口。
6. Query optimizer
query optimizer 是最为庞杂的一个组件,涉及到的概念多,首先,query optimizer 需要将 SqlNode 转成 RelNode(SqlToRelConverter),并使用一系列关系代数的优化规则(RelOptRule)对其进行优化,最后将其转化成对应引擎可执行的物理计划。
6.1 SqlNode 到 RelNode
SQL 是基于关系代数的一种 DSL,而 RelNode 接口就是 Calcite 对关系代数的一个抽象表示,所有关系代数的代码结构都需要实现 RelNode 接口。
SqlNode 是从 sql 语法角度解析出来的一个个节点,而 RelNode 则是一个关系表达式的抽象结构,从关系代数这一角度去表示其逻辑结构,并用于之后的优化过程中决定如何执行查询。当 SqlNode 第一次被转化成 RelNode 时,由一系列逻辑节点(LogicalProject、LogicalJoin 等)组成,后续优化器会将这些逻辑节点转化成物理节点,根据不同的计算存储引擎有不同的实现,如 JdbcJoin、SparkJoin 等。下表是一个关于 SQL 、关系代数以及 Calcite 结构的映射关系:
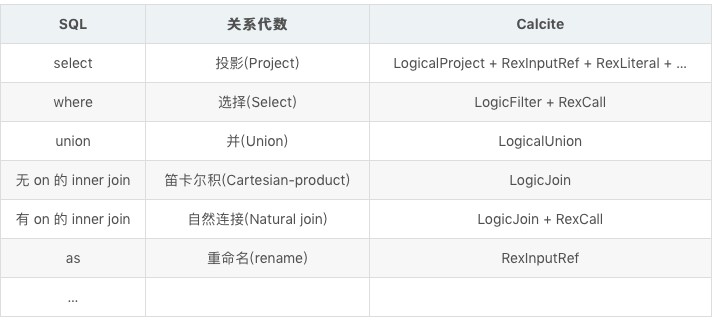
注:Calcite 列只列举了较常见的情况,而非和前面两列严格的映射标准。
一个简单的 SQL 例子经过 query optimizer 处理后得到的结果如下: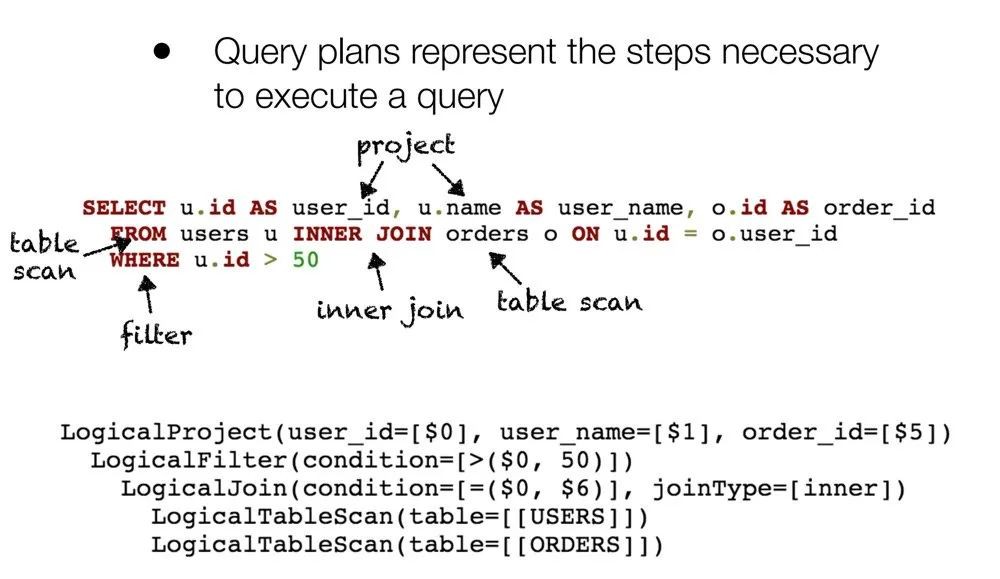
6.2 RelNode 优化

在将 SqlNode 转为 RelNode 后,我们就可以通过关系代数的一些规则对 RelNode 进行优化,这些“规则”在 Calcite 表现为 RelOptRule。
RelNode 有一些物理特征,这部分特征就由 RelTrait 来表示,其中最重要的一个是 Convention(Calling Convention),可以理解是一个特定数据引擎协议或数据源约定,同数据引擎的 RelNode 可以直接相互连接,而非同引擎的则需要通过 Converter 进行转换(通过 ConverterRule 匹配)。
比较常见的优化规则如:
- 剪除不用的 fields;
- 合并 projections;
- 将子查询转为 join;
- 对 joins 重排序;
- 下推 projections;
- 下推 filters;
- ……
7. 应用场景
基于 Calcite 良好的可插拔特性,目前有许多基于 Calcite 二次开发的 SQL 解析引擎,如 Flink,该节列举了一些可以基于 Calcite 拓展的工作和思路。
7.1 拓展 SQL 语法解析
基于 JavaCC 实现词法分析器(Lexer)和语法分析器(Parser),比如 Flink 在Calcite 原生的 Parser.jj 模板之上自定义拓展了 SqlCreateTable 和 SqlCreateView 两种 Parser,支持解析 CREATE TABLE ... 和 CREATE VIEW ... 的 DDL,同时需要拓展对应的 Java 类。。
7.2 拓展元数据校验的自定义数据结构
通过拓展 Schema 和 Table 等接口可以自定义注入元数据的时机以及格式,比如 Flink 通过命令式编程建立嵌套 VIEW 的数据依赖(假设 viewA 依赖 viewB 的数据,则需要先手动调用 API 解析 viewB),有的框架则批量读取,自己建立拓扑图来解决数据依赖问题。关于元数据格式 Flink 基于 Table 接口实现了 QueryOperationCatalogViewTable 来表示表、视图,并为其设计了统一的 TableSchema 收集 RelDataType 信息。
7.3 拓展类型解析
当碰着一些 Calcite 原生不支持的复杂类型,可以通过拓展 RelDataTypeFactory 等相关类型接口拓展类型解析。
7.4 拓展具体的规则优化
可以自定义一些特殊的 Rule,调用 HepProgramBuilder 的 addRuleInstance 方法注册到 planner 里,这就可以在 RelNode 的优化过程中匹配到我们的自定义 Rule,并在成功匹配的情况下进行优化。
这几种场景从流程复杂度的角度来看是 SQL 语法解析>元数据校验>类型解析>规则优化,但在实际拓展过程中,个人认为难度顺序反而是相反的,因为 SQL 语法解析和元数据校验的流程虽然很复杂,但封装完善,类型解析需要考虑的适配点较多是一个难点,而规则优化则需要深厚的 SQL 基础和一些理论知识,实际拓展过程反而his最为困难的。

发表评论
登录后可评论,请前往 登录 或 注册