元宇宙构建基石:三维重建技术
作者:智能物联网AIoT小助手2022.08.23 15:55浏览量:801简介:重点阐述元宇宙中“货”的自动生产,即物品的三维重建
如今“元宇宙”概念爆火,作为前沿数字科技发展的集成体之一,元宇宙正成为诸多产业寻求破局的全新风口。元宇宙是利用科技手段进行链接与创造,与现实世界映射和交互的虚拟世界,具备新型社会体系的数字生活空间;其本质上是对现实世界的虚拟化、数字化过程,而内容的生产则是这一过程中必不可少的环节。在元宇宙内容最主要的三个要素“人,货,场”的内容生产中,目前还是大量依赖于人工制作。新技术引发新变革,支撑元宇宙发展的底层技术正在逐步的走向完善和成熟,通过人工智能技术去创作内容(AIGC)也逐渐变成了行业趋势。因此,本篇文章将重点阐述元宇宙中“货”的自动生产,即物品的三维重建。
三维重建技术概述
在元宇宙空间中,数字化身对应的是一个个三维模型,数字化的过程即是三维重建过程。“人”和“场”由于不同个体之间的差异性较小,因此很多建模工作都依赖于人工通过专业软件去建立标准模型,再通过设置和调整参数去获取不同的个体。而对于“货”而言,由于物品形状复杂、纹理多变,且极具个性化的属性,往往导致通过建模软件制作出的模型需耗费大量的时间。例如下图通过人工制作的手办模型就比较费时费力,这极大拉高了人们参与元宇宙内容建设的门槛,但同时也给自动三维重建技术蕴藏了更多的应用潜力。

🔼基于人工制作的三维模型效果展示
物品的自动三维重建技术通常可以分为两大类,一类称之为“主动式”,另一类则为“被动式”,“主动式”和“被动式”指传感器接受信息的不同方式。一般而言,“主动式”三维重建需要先通过硬件投射出预设的信号,经由物体以后再被传感器捕捉;而“被动式” 三维重建指利用周围环境如自然光的反射,使用相机获取图像,然后通过特定算法计算得到物体的立体空间信息。常见的“主动式”三维重建方法有结构光、飞行时间(Time of Flight, ToF)、主动立体视觉技术等;而“被动式”三维重建方法包括被动视觉(双目视觉,多视角立体视觉)等。
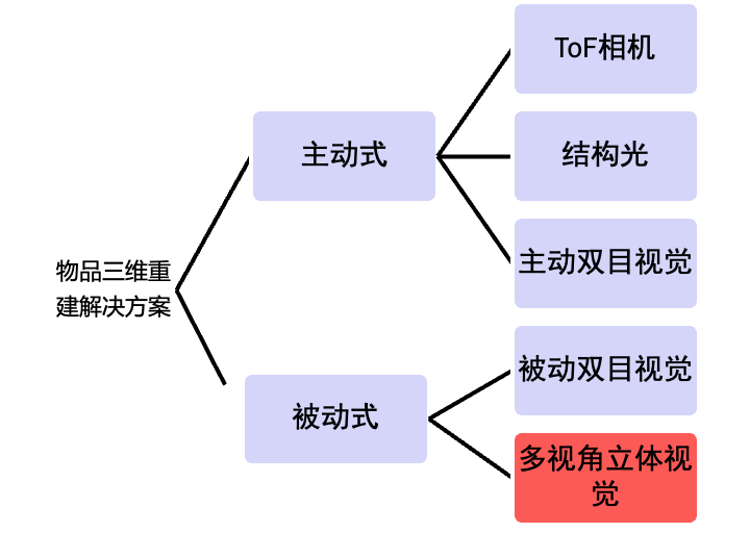
🔼常见的物品自动三维重建技术
结构光:该技术对硬件要求较高,需要精密且复杂的投影设备(projector)和成像设备(imager) 进行操作。首先,用户使用投影设备将预设的编码图像投射到物体表面,然后编码图像因受物体形状影响发生变化,进而通过这些变化估算出物体的深度信息,实现模型重建。其中预设的编码图像包括随机散斑(激光或红外光)、条纹编码和二维结构编码等,如下图条形编码结构光系统示例。结构光技术基于的原理是三角测量法,用户只需找到变形图像中的编码特征与投射编码的对应位置关系,即可以计算出物体的深度信息。
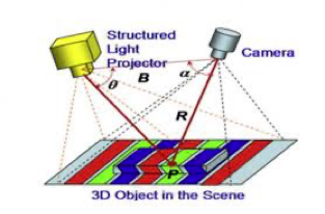
🔼条形编码结构光系统示例
飞行时间:该技术的测距方式是主动式测距,利用如激光等光源发射至目标物体,然后再通过接收返回的光波来获取物体的深度信息。即在光速及声速一定的前提下,通过测量发射信号与接收信号的飞行时间间隔来获得距离的方法。
被动立体视觉:该技术不需要额外的装置,只需要利用相机直接对物体成像即可。根据参与重建的相机视角个数,可以分为双目(两个相机视角)和多目(>2个相机视角)两种情形。该技术同样基于三角测量法原理,通过连接不同相机光心与同一个物理点的对应像素位置来获取三维重建信息;而对应像素点的寻找则通过图像特征的匹配来实现的。

🔼三角法示例:连接相机光心与对应的像素位置生成一条直线,
不同相机的直线在空间中的交点即对应了物理点的三维位置
主动立体视觉:该技术是在被动立体视觉的基础上,添加了与结构光方法类似的投射装置,但它投射出来的图像不需要有编码;更多的只是去改变物体表面的纹理性状,以增强被拍摄物体的图像特征,方便不同相机图像之间的特征匹配。
通常来说,主动式的重建方式精度会更高,但受制于投影设备,分辨率一般相对较低;而被动式的重建方式往往精度相对低一些,但分辨率较高(与图像分辨率相关)。这里的“精度”指物体重建的三维模型与物体真实三维结构间的误差,而“分辨率”则指三维重建方法建立物品模型的最小物理尺寸。从使用方式的难易程度及成本考虑,结构光、ToF等主动式三维重建方法使用的装置因普及度不高,往往需要额外购买,同时,在操作过程中还需要做定期的标定,提高了操作难度;而被动式三维重建方法则直接使用相机就能获取图像,通过手机自带的高分辨率相机就能实现物品的三维重建。因此市面上普及程度较高的智能手机就能轻松满足拍摄需求,能让更多用户参与到元宇宙的内容建设中。
百度VR物品三维重建
百度VR自研的三维重建算法能够实现物品全方位、多角度环绕拍摄,支持通过照片生成物品的3D模型。为有效降低用户拍摄物品的难度和成本,提高物品建模的效率;百度VR推出了能够全面覆盖和适配iOS和Android端的软硬件采集系统—“TL-50mini+百度VR·AI拍“。智能拍摄硬件“TL-50mini”打造了多窗口的精巧桌面摄影台,用户可以根据实际需要,实时调控灯箱亮度色温、拍摄角度、内置转盘的旋转速度等,帮助用户轻松制作出物品全角度照片和拟真的建模效果。

🔼采集系统:物体分别正放和侧放在转盘上完成两圈采集,
算法经过处理后生成最终的三维纹理模型
从算法的角度看,百度VR基于图像的物品三维重建算法需要解决两个核心问题:一个是相机空间位置的恢复问题,即相机是在空间中哪个位置对物体进行拍摄的;另一个则是如何确定同一个物理点在不同相机中的像素位置对应关系。基于要解决的这两个核心问题,一个标准的算法流程如下:
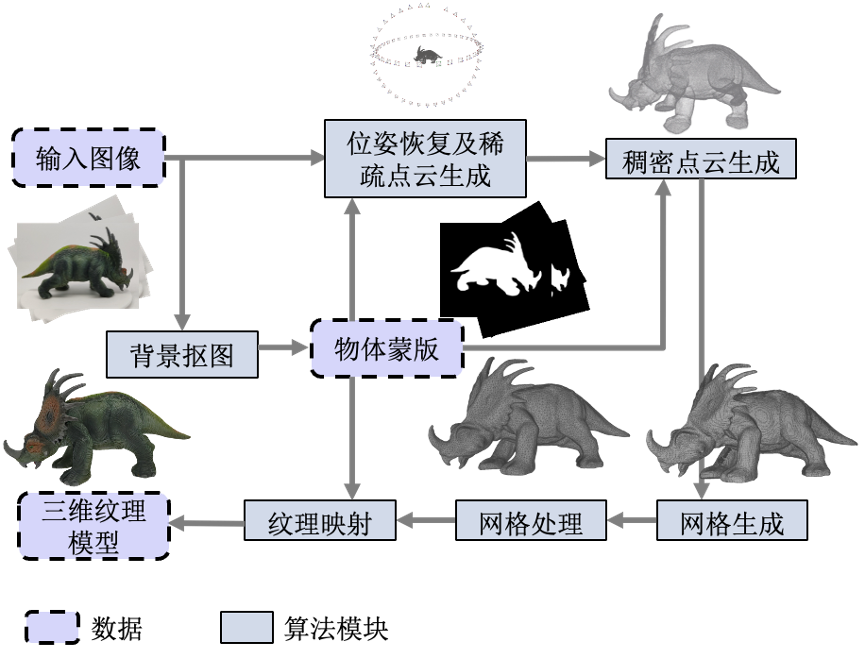
🔼基于图像的三维重建算法流程
首先,接收输入物体的图像后,算法会对图像进行预处理,主要是做背景抠除,只保留被拍摄的物体本身,之后所有的图像运算都将限制在物体的蒙版上进行。当然,这一步骤并非必须,但是却可以有效地减少后续运算时间,去除多余的重建噪声。接下来便是解决上文提出来的两个核心问题:(1)位姿恢复模块解决的是相机空间位置的问题,通常这步可以采用Structure from motion(SFM)技术来实现;稠密点云生成模块则解决的是如何确定物理点在不同相机的像素位置对应关系的问题,基于此, 通过三角测量法完成深度估计及融合。此外,位姿恢复模块还将产生一个副产品,即物体的一个稀疏点云表达,它将作为初值帮助稠密点云生成模块完成深度估计;并在获取物体的三维点云表达后,将其进行网格化,纹理生成等操作,最终得到一个对渲染引擎更为友好的三维表达方式。
通用抠图:百度VR自研的自动抠图系统,融合了目标检测及图像分割方法,能对输出蒙版进行边缘平滑锐化等图像后处理,能覆盖鞋类、玩具手办、文玩古器等多个垂类行业,平均IoU达到97%以上。
位姿恢复: 百度VR采用传统的SFM技术来进行位姿恢复,同时结合自有的数据采集方式,对其进行了改进。
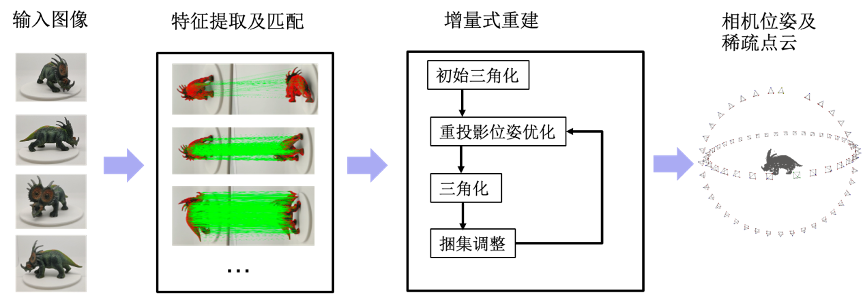
🔼传统的增量式SFM三维重建算法流程
简单来说,就是先构建图像特征,找到图像上一些有显著特征的点,通常是一些明暗变化或者有形状特征的位置;然后通过特征的匹配,在图像序列中找到一组又一组的特征点对应序列。通过这些特征的对应,在两幅图中利用三角测量法实现初始相对位姿的估计;在多幅图中则利用Perspective n Points(PnP)方法进行重投影位姿优化,实现多相机位姿的估计。最后,基于所有的特征匹配序列,完成全局的捆集调整(bundle adjustment),因此寻找图像之间的特征匹配关系就变得尤为重要。
与此同时,对于有序的输入数据,通常只需要计算当前图像与前后序列图像的匹配关系;而对于无序的输入数据,则往往需要穷尽各种匹配的可能。结合多圈的数据采集方式,我们提出来一种介于有序和无序之间的混合匹配模式,即在一圈以内,我们采用顺序的匹配方式;而在多圈之间采取穷尽的匹配方式。另外, 我们还将一圈数据中的头尾连接起来,形成闭环,争取在全局优化中起到回环(loop closure)的作用,提高全局优化精度。以单圈36张图,两圈的采集方式为例,我们新的数据匹配方式可以将匹配次数从2556次降到1728次,在保证精度的同时也极大的节省了运算时间。下图展示的就是一个我们利用新的匹配方式得到的图像节点特征匹配图,以及对应的位姿恢复结果。从这个图上即可看出我们数据的组织方式与采集方式完美地结合在了一起。

🔼图像特征匹配图:蓝色节点代表图像,虚线连接代表两张图像之间具有匹配关系,
而虚线上的数字则代表了该匹配关系的强弱程度。

🔼两圈采集下相机姿态的恢复结果
稠密点云生成:基于视角的稠密点云的生成一般有几类方法:一类是传统的多视几何方法,即通过找寻某种度量来判定像素之间的对应关系,完成深度估计,包括半全局匹配(Semi Global Matching, SGM)、PatchMatch等方法。另一类是基于深度学习的多视深度估计,即利用深度神经网络来回归出深度信息,代表的方法有MVSNet及其变种、PatchMatchNet等。通常基于深度学习的方法训练时,需要输入物体的真实三维结构,但三维结构需要通过精度很高的桌面扫描仪获得,导致金钱成本和时间成本都比较高,同时还面临着算法泛化性的风险。因此,从落地的角度看,我们目前在采用传统方法的基础上,也参照神经网络方法对传统方法进行了算法改造,大大地提高了物体重建的完整度。
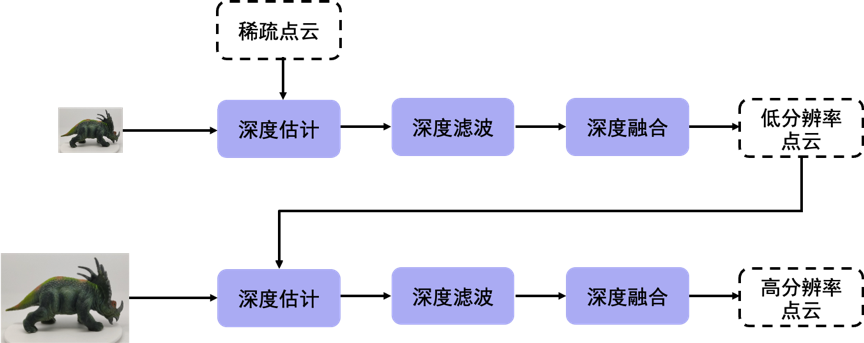
🔼稠密重建的cascade模式
稠密重建采用了从低分辨率到高分辨率的cascade模式,先在低分辨率图像上进行重建,再以低分辨率的重建点云作为初始值,进入下一轮更高分辨率的图像的迭代。低分辨率情况下,可以有更大的感受野,能够帮助区分验证像素对应关系,有利于重建的完整度;而高分辨率则能提高重建精度。将二者结合起来,可以在保证精度的同时,提高重建完整度。此外,基于综合运行时间和效果的考量,我们发现使用两轮迭代就可以较好地达到效果。下图是使用cascade模式前后算法结果的对比,可以看到点云完整度有了明显的提升。
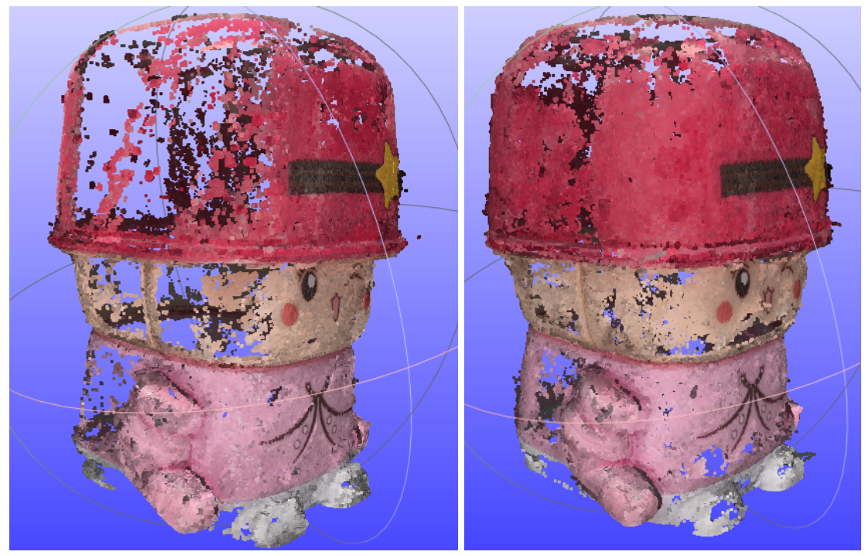
🔼优化方向
基于图像的被动重建方法虽然易于推广,但也有不可忽视的缺点,即过分依赖于物体本身的纹理特征;一旦物体颜色比较单一,算法就容易失效。针对这一问题,百度VR未来将考虑引入一些低成本的配件来解决;比如拍摄时,在物体周围放置一些标定纸,以此提高物体所处环境的纹理特征,改善相机位姿恢复的效果;或者进一步使用廉价的激光笔打出随机的散斑,将纯被动的重建转化成半主动的重建等。

🔼配件提高重建质量示意图:(左)放置标定纸改善相机位姿恢复,
(右)使用激光光斑改善物体表面纹理特性
另外,近两年神经渲染技术也横空出世,在三维重建领域取得了很可观的成绩。神经渲染技术是一种体渲染技术,空间中任意一个位置都可以表示为三维坐标及观察方向;而其属性可由颜色及不透明度(或是某种带符号的距离场,SDF)来定义,它们二者的关系是由一个神经网络来描述。沿着每条可视光线,根据对颜色及SDF的累积,可以计算出该视角下对应像素的颜色值;然后通过训练优化该光线累积得到的颜色值与实际图像颜色值的差异,最终得到真实的SDF,进而获取物体的三维结构。神经渲染技术是一种自监督的学习方法,虽然目前应用到物品的三维重建上,还存在训练时间过长、以及落地场景局限等问题,但其在物品、人体和空间重建等领域已展现出了巨大的技术潜力。因此,未来百度VR将持续关注该领域,并致力于将神经渲染技术更好地落地。
结语
元宇宙的爆发式发展必定会带来内容自动生产的大量机会,依托百度领先的AI和VR技术,百度VR也将继续在这一领域持续深耕,致力将原本复杂的建模操作变得更为简单直接,让用户快速生成高质量的三维模型。目前百度VR创作中心已对外开放公测,点击 https://vr.baidu.com/vrcc/ ,即可上传自己多视角的物品拍摄图像,自动生成3D模型,赶快来体验吧!
相关文章推荐
发表评论
关于作者

- 被阅读数
- 被赞数
- 被收藏数
登录后可评论,请前往 登录 或 注册