用PaddleNLP做一个中医“百科全书”
2023.02.09 10:24浏览量:2530简介:中医名词看不懂?用PaddleNLP做一个中医“百科全书”
1、方案介绍
项目简介
中医文献阅读理解是一个将自然语言处理技术应用于中医药领域的任务,其目标是使用能够读取、理解和回答中医药知识的模型普及和传播中医药知识。该任务需要建立一个大规模的中医药语料库,并使用自然语言处理技术对语料库进行处理,提取关键信息并建立模型。
模型的输入可以是一个中医药相关的问题,模型的输出则是问题的答案。例如,如果输入的问题是“什么是中医证候学?”,则模型的输出可能是“中医证候学是中医药的一个重要理论,它旨在通过观察患者的症状和体征,推断患者所患疾病的特点和发展趋势,为临床治疗提供理论指导。”
此外,基于该任务还可以开发更多关于中医药知识的小应用,如中医药问诊系统、中医药辨证论治辅助工具等,以帮助更多人了解和应用中医药知识。
项目链接
https://aistudio.baidu.com/aistudio/projectdetail/5166465
数据集介绍
本项目标注数据源来自四个中医药领域文本,包括《黄帝内经翻译版》《名医百科中医篇》《中成药用药卷》《慢性病养生保健科普知识》。共计5000篇文档,每篇文档人工标注产生 1~4对(问题, 答案),共标注13000对(文档、问题、答案)。
{
"id": 98,
"text": "黄帝道:什麽叫重实?岐伯说:所谓重实,如大热病人,邪气甚热,而脉象又盛满,内外俱实,便叫重实",
"annotations": [
{
"Q": "重实是指什么?",
"A": "所谓重实,如大热病人,邪气甚热,而脉象又盛满,内外俱实,便叫重实"
},
{
"Q": "重实之人的脉象是什么样?",
"A": "脉象又盛满"
}
],
"source": "黄帝内经翻译版"
}
技术点介绍
随着中医文献资源的不断增加, 如何高效地阅读和理解中医文献已经成为了一个重要课题。为了解决这个问题,我们需要利用一些自然语言处理、机器学习、可视化等相关技术。本项目的主要技术点包括:
- 构建中医 MRC 数据集,使用 PaddleNLP 搭建、训练并调优阅读理解模型;
- 采用多种内置模型进行实验,最终确定使用 Roberta 阅读理解模型;
- 动转静,完成静态图的推理,并用 Gradio 实现可交互的部署。
PaddleNLP
PaddleNLP 是飞桨自然语言处理模型库,具备易用的文本领域 API、丰富的预训练模型、多场景的应用示例和高性能分布式训练与部署能力,旨在提升开发者在文本领域的开发效率。
RoBERTa 阅读理解模型
阅读理解本质是一个答案抽取任务,PaddleNLP 对于各种预训练模型已经内置了对于下游任务-答案抽取的 Fine-tune 网络。以 PaddleNLP 中的 RoBERTa 模型为例,将模型 Fine-tune 完成答案抽取任务。
答案抽取任务的本质就是根据输入的问题和文章,预测答案在文章中的起始位置和结束位置。RoBERTa 模型主要是在 BERT 基础上做了几点调整:
训练时间更长,batch size 更大,训练数据更多;
移除了 next predict loss;
训练序列更长;
动态调整 Masking 机制。
基于 Gradio 实现 AI 算法可视化部署
如何将你的 AI 算法迅速分享给别人让对方体验,一直是一件麻烦事儿。Gradio 算法可视化部署可以自动生成页面,形成交互,改动几行代码就能完成项目,支持自定义多种输入输出,支持生成可外部访问的链接,从而实现分享。
最终效果呈现
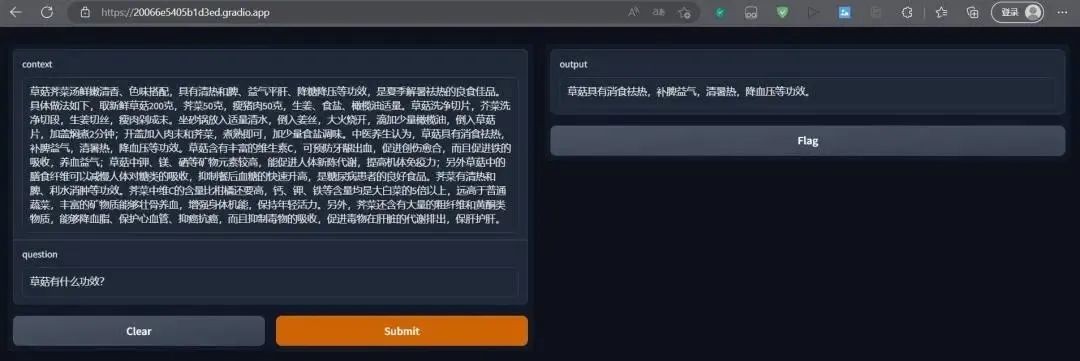
02 设计流程展示
环境配置
本项目基于 PaddlePaddle2.0.2与 PaddleNLP2.0.7版本。关于如何下载此版本可以点击飞桨官网,查看下载方式。更加推荐在 AI Studio 上一键运行哦。
项目链接
https://aistudio.baidu.com/aistudio/projectdetail/5166465
方案设计

阅读理解的方案如上图,query 表示问句,一般是用户的提问,passage 表示文章,query 的答案要从 passage 里面抽取出来。query 和 passage 经过数据预处理,生成其 id 形式的输入,然后经过 RoBERTa 模型,得到答案的位置,从而得到相应的 answer。
数据处理
具体的任务定义为:给定问题 q 和一个篇章 p,根据篇章内容,给出该问题的答案 a。数据集中的每个样本,是一个三元组。
本项目的数据集是 json 格式,包括:
lid: 段落 id
ltext: 段落文本
lannotations: 每个段落拥有一个 annotations,其中包含1~4对(问题、答案)
lQ:问题
lA:答案
将上述数据进行简单地数据清洗以及格式(sqaud 格式)转换操作。为了方便读取,具体格式如下:
{
'id': 'xx', 'title': 'xxx',
'context': 'xxxx',
'question': 'xxxxx',
'answers': ['xxxx'],
'answer_starts': [xxx]
}
模型训练与策略选择
设置 Fine-tune 优化策略
# 参数配置
# 训练过程中的最大学习率
learning_rate = 3e-5
# 训练轮次
epochs = 2
# 学习率预热比例
warmup_proportion = 0.1
# 权重衰减系数,类似模型正则项策略,避免模型过拟合
weight_decay = 0.01
num_training_steps = len(train_data_loader) * epochs
lr_scheduler = ppnlp.transformers.LinearDecayWithWarmup(learning_rate, num_training_steps, warmup_proportion)
# Generate parameter names needed to perform weight decay.
# All bias and LayerNorm parameters are excluded.
decay_params = [
p.name for n, p in model.named_parameters()
if not any(nd in n for nd in ["bias", "norm"])
]
optimizer = paddle.optimizer.AdamW(
learning_rate=lr_scheduler,
parameters=model.parameters(),
weight_decay=weight_decay,
apply_decay_param_fun=lambda x: x in decay_params)
设计损失函数
由于 BertForQuestionAnswering 模型将 BERT 模型的 sequence_output 拆成 start_logits 和 end_logits,所以阅读理解任务的 loss 也由 start_loss 和 end_loss 组成。答案起始位置和结束位置的预测可以分成两个分类任务,我们需要自己定义损失函数。
设计的损失函数如下:
class CrossEntropyLossForSQuAD(paddle.nn.Layer):
def init (self):
super(CrossEntropyLossForSQuAD, self). init ()
def forward(self, y, label):
start_logits, end_logits = y # both shape are [batch_size, seq_len]
start_position, end_position = label
start_position = paddle.unsqueeze(start_position, axis=-1) end_position = paddle.unsqueeze(end_position, axis=-1)
start_loss = paddle.nn.functional.softmax_with_cross_entropy(
logits=start_logits, label=start_position, soft_label=False) start_loss = paddle.mean(start_loss)
end_loss = paddle.nn.functional.softmax_with_cross_entropy( logits=end_logits, label=end_position, soft_label=False)
end_loss = paddle.mean(end_loss)
loss = (start_loss + end_loss) / 2 return loss
模型训练
模型训练的过程通常有以下步骤:
从 dataloader 中取出一个 batch data;
将 batch data 喂给 model,做前向计算;
将前向计算结果传给损失函数,计算 loss;
loss 反向回传,更新梯度。重复以上步骤。
每训练一个 epoch 时,程序通过 evaluate()调用 paddlenlp.metric.squad 中的 squad_evaluate()返回评价指标,compute_predictions() 评估当前模型训练的效果,用于生成可提交的答案。
03 预测部署
模型训练完成之后,我们实现模型的预测部署。虽然训练阶段使用的动态图模式有诸多优点,包括 Python 风格的编程体验(使用 RNN 等包含控制流的网络时尤为明显)、友好的 debug 交互机制等。但 Python 动态图模式无法更好地满足预测部署阶段的性能要求,同时也限制了部署环境。
高性能预测部署需要静态图模型导出和预测引擎两方面的支持。
动转静导出模型
基于静态图的预测部署要求将动态图的模型转换为静态图形式的模型(网络结构和参数权重)。飞桨静态图形式的模型(由变量和算子构成的网络结构)使用 Program 来存放,Program 的构造可以通过飞桨的静态图模式说明,静态图模式下网络构建执行的各 API 会将输入输出变量和使用的算子添加到 Program 中。
使用推理库预测
获得静态图模型之后,我们使用 Paddle Inference 进行预测部署。Paddle Inference 是飞桨的原生推理库,作用于服务器端和云端,提供高性能的推理能力。使用 Paddle Inference 开发 Python 预测程序仅需以下步骤: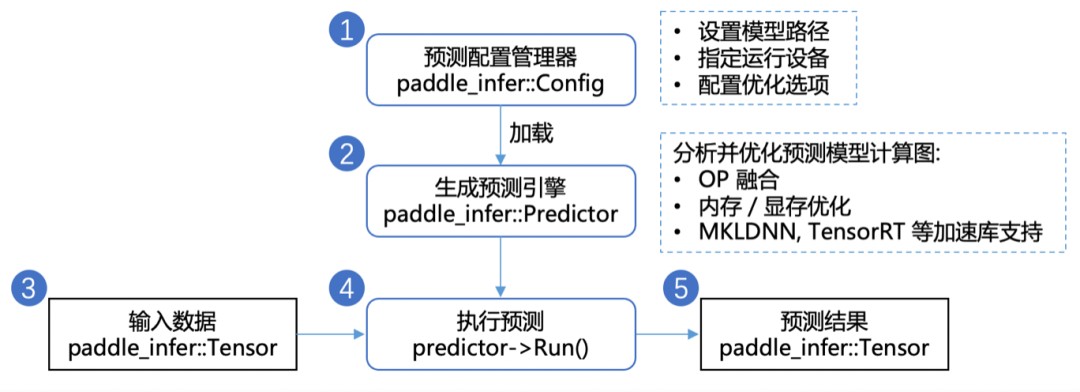
Gradio 进行交互项部署
Gradio 部署有以下步骤:
- 将模型拷贝到本地,并按照接口要求封装好方法;
import Gradio as gr
def question_answer(context, question):
pass # Implement your question-answering model here...
gr.Interface(fn=question_answer, inputs=["text", "text"], outputs=["textbox", "text"]).launch(share=True)
加载用户输入的 context 和 question,并利用模型返回 answer;
返回到 Gradio 部署的框内, 进行页面展示;
生成公开链接。
模型 Benchmark 地址
https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/ernie-3.0
使用方法参考
https://aistudio.baidu.com/aistudio/projectdetail/2017189

发表评论
登录后可评论,请前往 登录 或 注册