万亿级对象存储的元数据系统架构设计和实践
作者:百度智能云开发者中心2023.03.02 11:08浏览量:764简介:百度沧海 · 存储是百度智能云在 2021 年发布的一个技术品牌。
1. 对象存储 BOS 概述
百度沧海 · 存储是百度智能云在 2021 年发布的一个技术品牌。它汲取了多年支持百度搜索、百度网盘、百度 AI 的丰富经验,构建了存算协同、软硬融合、云边一体的技术平台,并且抽象出多套高度可复用的基础组件,如统一的基于纠删码的数据存储系统、统一的 NewSQL 元数据存储系统、业界优秀的开源共识算法 braft 等。
在完善的基础底座的支撑下,百度沧海 · 存储形成了一套完整的产品体系,如对象存储 BOS、块存储 CDS、文件存储 CFS、并行文件系统 PFS、数据湖存储加速 RapidFS 以及混合云存储 ABC Storage等。基于丰富的存储产品矩阵,在大数据、AI 高性能计算等各个应用场景形成了完备的解决方案。
百度沧海·存储丰富的产品体系和完备的解决方案都致力于实现一个目标:加速智能计算,释放数据价值。

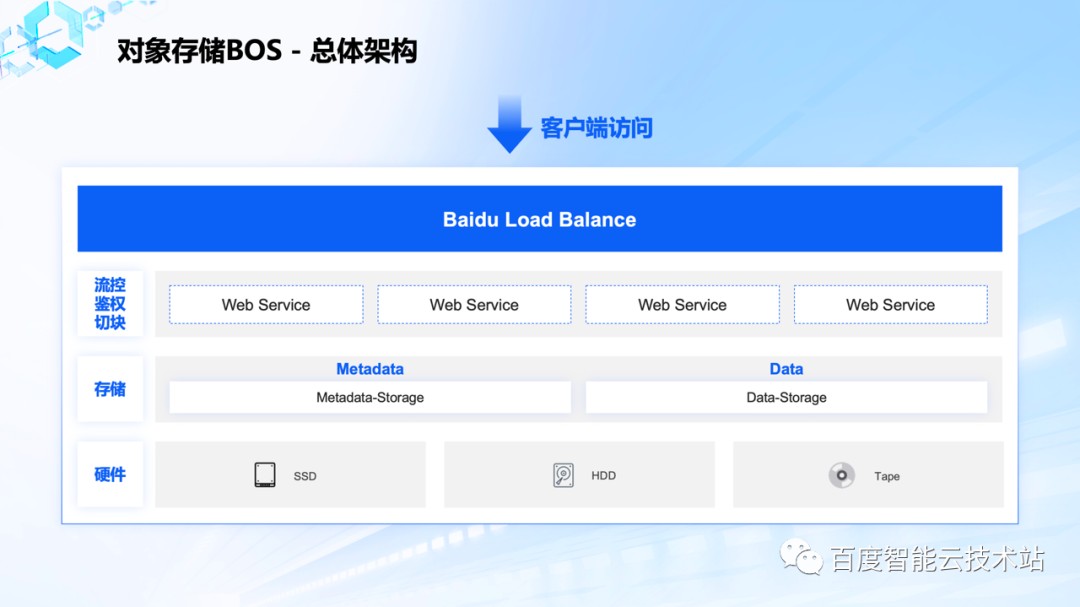
对象存储 BOS (Baidu Object Storage) 提供稳定、安全、高效的存储服务,支持文本、多媒体、二进制等任何类型的数据存储,单文件最大可达 48.8TB,对外提供标准 RESTful 的 HTTP API。整体架构分为四个层级:负载均衡、Webservice、存储以及硬件层。
整个 BOS 结构中,最上一层是自主研发的软 4 层负载均衡层:集群模式无单点,负责接入防攻击和 4 层负载均衡。
接下来一层是 Web Service,是无状态的可任意横向扩展服务,提供 HTTP 协议解析、流控、认证、鉴权、数据切块,数据流控制等功能。
存储层由元数据存储和数据存储这两套完全独立分布式系统组成。元数据存储系统基于高性能的 NewSQL 数据库系统构建。数据存储系统支持纠删码、超低副本数、单集群支持万台节点规模、EB 级存储,其中高度并发的纠删码 1PC 写入模式使得单流吞吐高达 200MB/s,副本数最低可以到 1.1 副本。
最底层的硬件支持了 SSD、HDD、磁带等不同介质,在不同的存储介质的组合下,BOS 推出了标准存储-多AZ、标准存储、低频存储-多AZ、低频存储、冷存储和归档存储等 6 级存储体系,其中冷存储是业界首发无需预先取回的适合归档数据存储的存储类型。
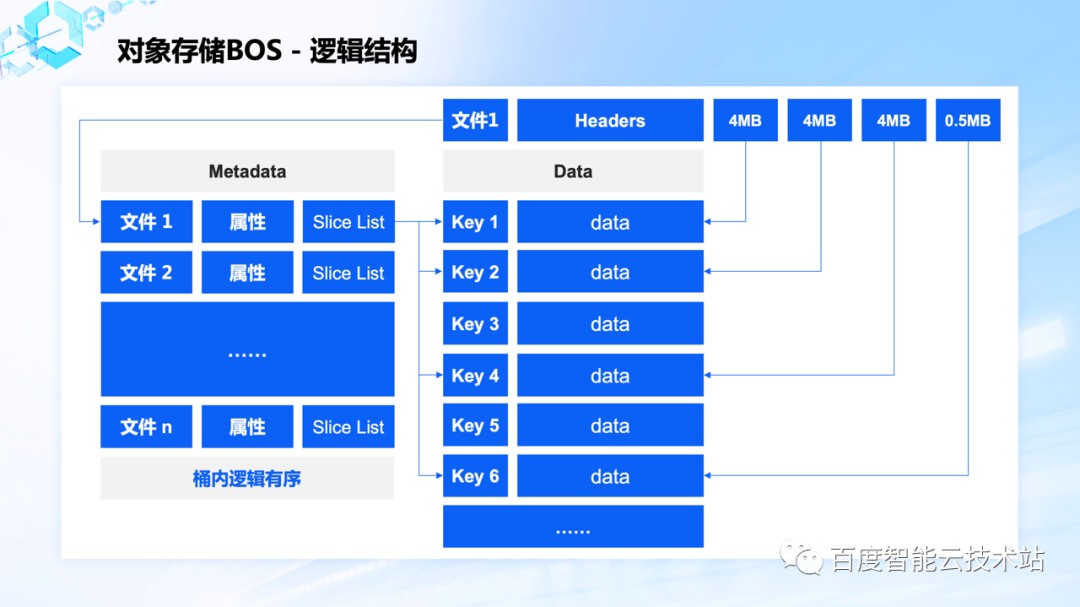
对象存储中有两个基础的概念,一个是桶,相当于文件存储中的文件系统。另外一个是对象,相当于文件存储中的文件,一个对象在 BOS 内部是如何组织的呢?它的逻辑结构如图所示:
首先数据按 4MB 切块存储到数据存储系统中,数据存储系统返回的 key 组成 Slice List,连同对象的一些属性信息存储到元数据系统中,元数据要求桶内逻辑有序,能够顺序 List objects。读取对象的时候先读取元数据,获取 Slice List 之后再去读数据,按顺序返回。
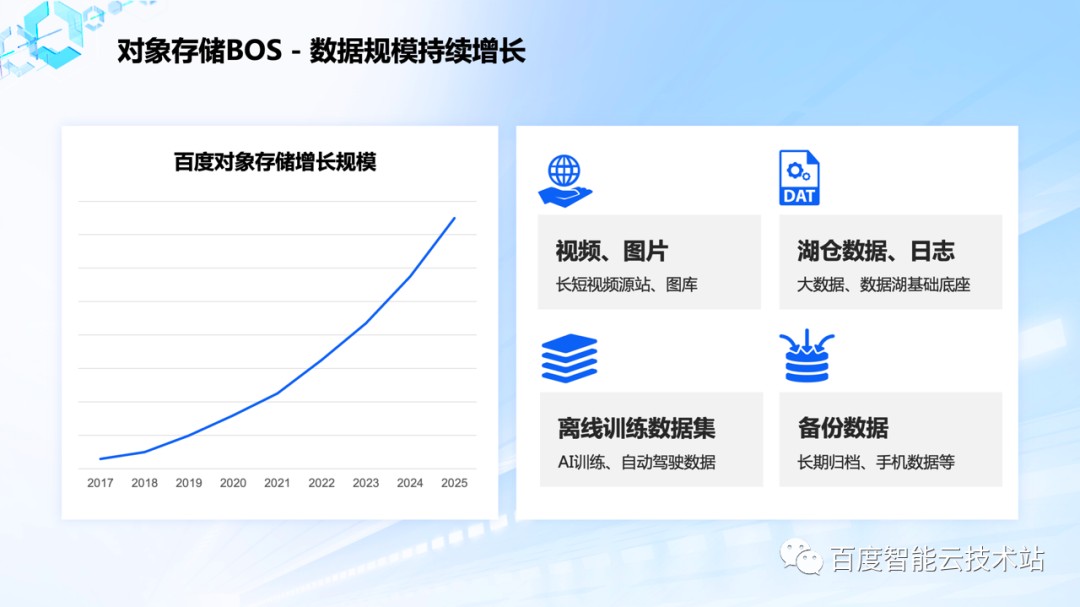
对象存储的数据主要以如下几种类型为主,第一种是视频、图片等媒体资源,也是占比最大的一部分;第二种是作为数据湖底座,存储大数据分析使用的日志、ETL 之后的格式化数据;第三种是供 AI 训练、自动驾驶仿真的离线数据集;第四种则是一些用于归档的备份数据。
随着百度智能云的体量不断增加,BOS 的规模持续增长,预计在 2024 年规模将会超过 10 万亿,如此大的规模和增长速度对元数据系统的挑战是非常大的。
2. 元数据架构与挑战
上一代元数据系统的核心逻辑是把每个桶的的元数据按 bucket id hash 的方式写入底层的一台或者几台 DataNode 中,DataNode 有主从做高可用,主节点提供强一致性读写。这样的系统架构有如下几个问题:
第一个是单桶容量受限。单个桶的数据 hash 到几台机器上,单桶的极限容量在百亿规模,最多极限也只是接近千亿;
第二个是吞吐量受限。由于单桶元数据节点数量的限制,单桶的吞吐的 QPS 最多就是在数万 QPS;
第三个是数据均衡的问题。由于桶和桶之间的对象数量差距很大,节点之间的容量存在非常大的数据倾斜问题,甚至有时会出现某些节点使用率 80%、某些节点不到 20% 的情况;
第四个是性能受限问题。主要体现在单桶的吞吐和 List objects 的性能存在跷跷板的关系——单桶吞吐越高,需要更多的存储节点,但是 List objects 时要 Merge 更多的数据才能返回结果;
最后一个问题是事务支持较差。比如要实现 object rename 的语义需要其他外部中间件支持或者补偿机制才能实现。

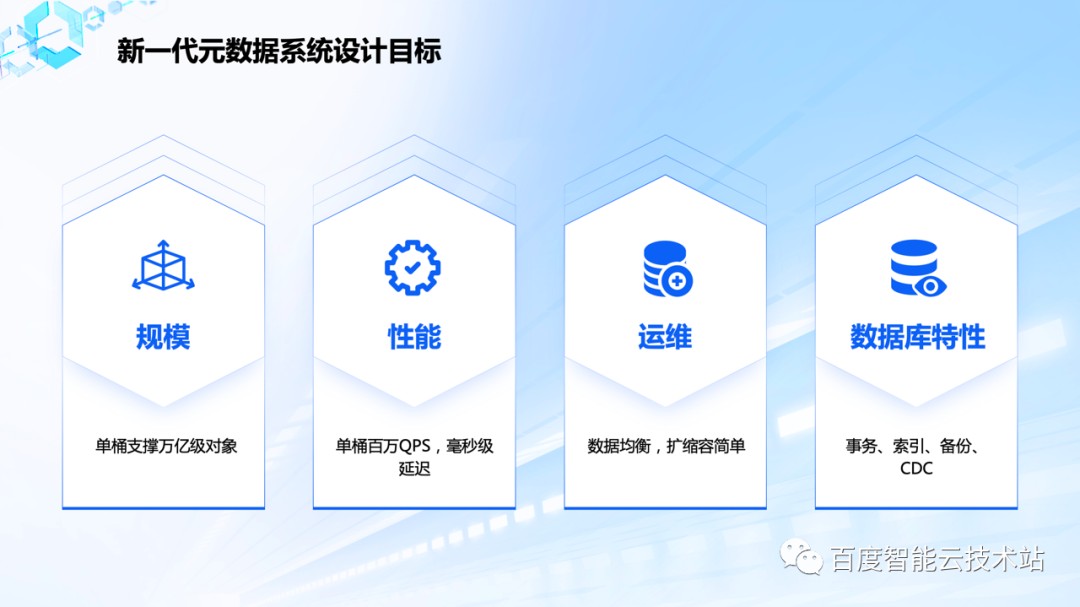
由于上一代元数据系统的问题,我们在 2020 年初启动了新一代元数据系统的设计和开发工作,在新一代元数据系统中要实现以下目标:
在规模上,单桶要支持万亿对象;
在性能指标上,单桶要支持百万 QPS,所有 API put、get、list 都实现毫秒级延迟;
在运维场景上,对运维友好,数据均衡分布,扩缩容简单方便;
同时具备一些数据库特性,比如事务的支持,二级索引,备份和 CDC 机制。
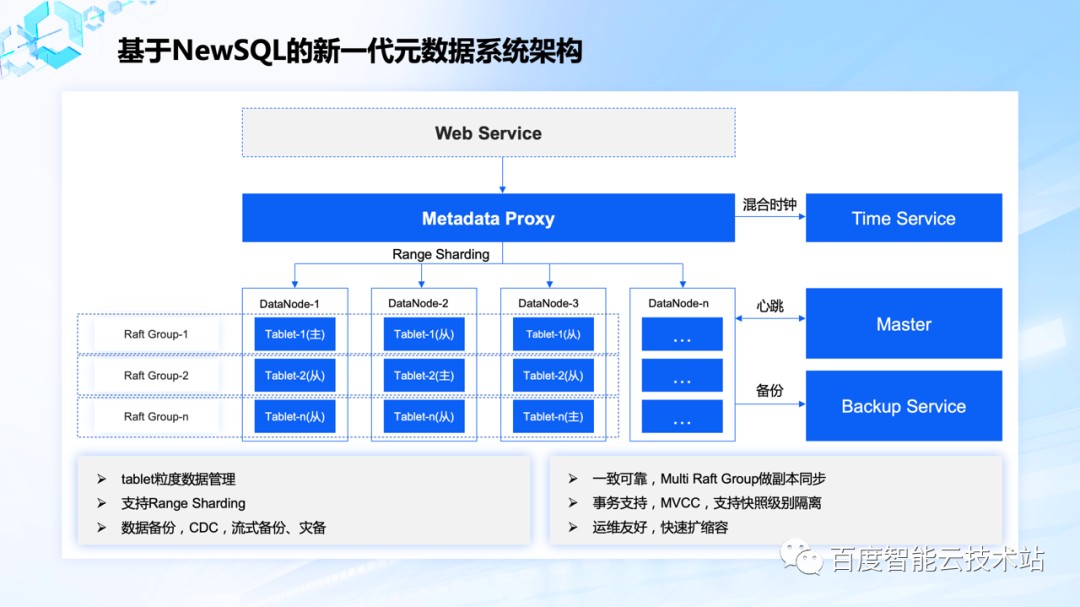
新一代元数据架构相对于上一代架构,主要做了如下的改进:
更小的数据管理粒度。分片作为最小的数据管理单元,而不是上一代系统的 DataNode,分片控制在 4GB 以下,能更好的实现数据的搬迁和均衡;
分片之间使用 Raft 实现数据复制和选主,实现高可靠、高可用;
引入 Master 管理分片的数据分布,并支持 Range 分区,可以更好的实现全局有序的特性;
支持事务机制,通过 MVCC 的方式支持快照级别隔离,object rename 的实现更加高效;
支持完善的数据备份机制,流式存量数据导出和实时增量同步,可支持天级导出千亿级数据。
3. 关键问题解决思路
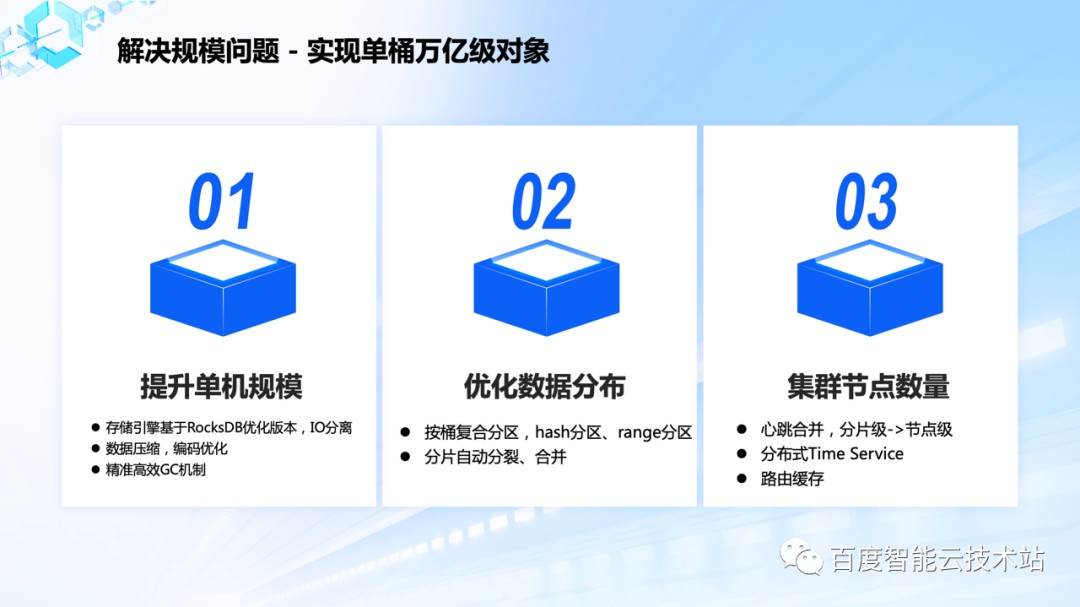
下面讨论如何解决规模问题,以实现单桶万亿级对象数。
在规模问题中,主要有三个变量:单机能支撑的数据量、数据能否分布到更多的节点、单个集群的规模能否支持足够多的节点数。只有将这三个点做到足够极致,才能满足单桶万亿的目标。
首先看单机支持的数据量。数据引擎基于 RocksDB 的优化版本,日志 I/O 和数据 I/O 做了分离。日志 I/O 使用更高性能、无使用寿命问题的 AEP 介质,使 NVMe SSD 的容量和 I/O 更均衡,数据使用率更高。同时也做了数据压缩和编码优化,使得单条元数据的空间占用更少,平均单条元数据 size 优化至 400 个 Byte 以内。第三是精准记录待 GC 的数据的起止位置,高效快速 Compaction,使得垃圾数据占比极低。做了这些优化之后,单机规模可以接近百亿。
再看下数据分布的优化。第一个优化是使用复合分区,先 hash 分区,再 range 分区。具体做法就是在元数据的编码最前面增加一位的 hash 产生的 shardKey,不同 shardKey 的数据间隔放置,同一个 shardKey 下的数据顺序放置,这样单个桶的元数据可以放置到更多节点上。第二个优化是分片支持自动分裂和合并机制,保证单个节点的数据不会太大也也不会太小,节点之间的数据保持均衡。
最后是集群节点规模方面的优化,主要有以下几个方面:
第一是心跳合并,Master 管理的单位是分片,满载时单机分片数接近 1W,假如集群管理 100 台机器,百万分片的心跳对 Master 是一个极大的负担,把分片的心跳合并至节点级可以有效解决心跳占用资源问题;
另外一个优化是做了分布式 Time Service,解决 Time Service 单点的问题,也做了客户端的路由缓存,减少对 Master 的访问压力。
现在单个集群管理的节点规模可以到 1000 台以上,单机支撑百亿规模 + 合理的数据分布 + 单集群 1000 台可以轻松支持单桶万亿级对象规模。
下面再讨论性能方面如何实现单桶百万 QPS,这里也有三个主要变量:单机能支撑的吞吐、数据如何分布、单个集群规模,数据分布和集群规模思路一致不再详细说明。除了这些点之外性能还要关注热点问题以及单次请求的资源消耗。
首先是单机引擎效率提升。第一个优化是做了日志的合并,把 Raft log 和 RocksDB 的日志合并成一路,节省了 I/O。 另外也支持了批量操作,批量 Commit Raft log 和存储引擎,用少量延迟换取更高的吞吐,优化后的单机引擎支持高达 10W QPS 的吞吐。
热点问题是分布式系统一个比较棘手的问题,热点问题解决不好,那么整个集群都会受到拖累,出现明显的瓶颈。
针对热点问题,我们设计了多维度探测机制,包括单机 CPU 负载、API 延迟长尾、单分片的请求数等。一旦出现热点,会立即触发原地分裂,分片一分为二,然后执行切主动作,把写入流量切到其他从节点,随后开始数据搬迁,把数据搬迁到负载较轻的节点上去。
另外一个策略是让从节点提供读服务,提供两种模式,默认强一致读,从节点要去主节点通信一次判断从节点的 applied index 是否跟主节点一致,如果是则返回结果给客户端;如果不是则需 302 到主节点。另一种模式是高频访问降级读模式,比如一个热点的图片访问 1000 QPS,这时候从节点直接返回数据,不再判断是不是最新。这种情况相当于用牺牲一些一致性,换取更高的可用性。
在单次请求资源消耗方面,因为事务消耗资源比较多,所以我们也针对事务操作进行了优化。对象存储要支持数据的生命周期,所以要支持按时间维度的索引。这个时候如果每次写入都要写数据表、索引表,每次都要 2PC,效率非常低。对象存储这个场景下并不要求索引和数据完全一致,所以做了特殊的优化,写数据表成功就返回,索引表采用异步批量的方式写入,这样能提升单机的写入吞吐,减少事务的开销。

4. 赋能产品功能升级
新一代元数据系统不只是提升了对象存储的规模、性能,也赋能了产品功能的升级。依托于新一代元数据系统,BOS 发布了原生层级 Namespace 和智能生命周期。
首先来看层级 Namespace。
对象存储默认的 Namespace 是平坦的,也就是对象和对象之间是相互独立的,没有层次关系,对象系统里面的层次结构也是前缀模拟出来的。这种设计对于大数据应用来说有较大的效率问题,尤其是文件夹 mv 操作,在平坦 Namespace 中,文件夹 mv 操作要逐条 mv 这个文件夹中的所有文件。所以当文件夹内的文件数很多时,耗时会明显增加。另外也有原子性问题,如果 mv 大量文件时失败,那么会出现一半在源文件夹、一半在目的文件夹的情况,大数据任务进入到异常状态,运行失败。
构建层级 Namespace 是解决这个问题的关键手段,有了层级目录树,文件夹 mv 操作就是一次 RPC,毫秒级就能完成该操作,但是层级 Namespace 也引入一个性能问题,即 Lookup 效率。比如要读取一个 4 层目录树下的文件 /a/b/c/d.txt,需要 Lookup 目录 a、目录 b和目录 c,3 次才能访问到元数据信息。新一代元数据系统实现了毫秒级查询,再加上批量查询和 cache 机制,总的 lookup 时间可以在 2ms 内完成。
TPC-DS 性能基准测试和线上实测数据均表明,相对于平坦的 Namespace,新一代元数据系统的性能有 10% 以上的提升,如果作业输入文件数较多的情况下,性能提升的幅度则更为明显。

其次是 BOS 的智能生命周期产品功能。
对象存储 BOS 共有 6 级存储:标准存储-多AZ、标准存储、低频存储-多AZ、低频存储、冷存储和归档存储。这 6 个存储级别越往后价格越低,同样的性能和吞吐也会有不同程度下降。
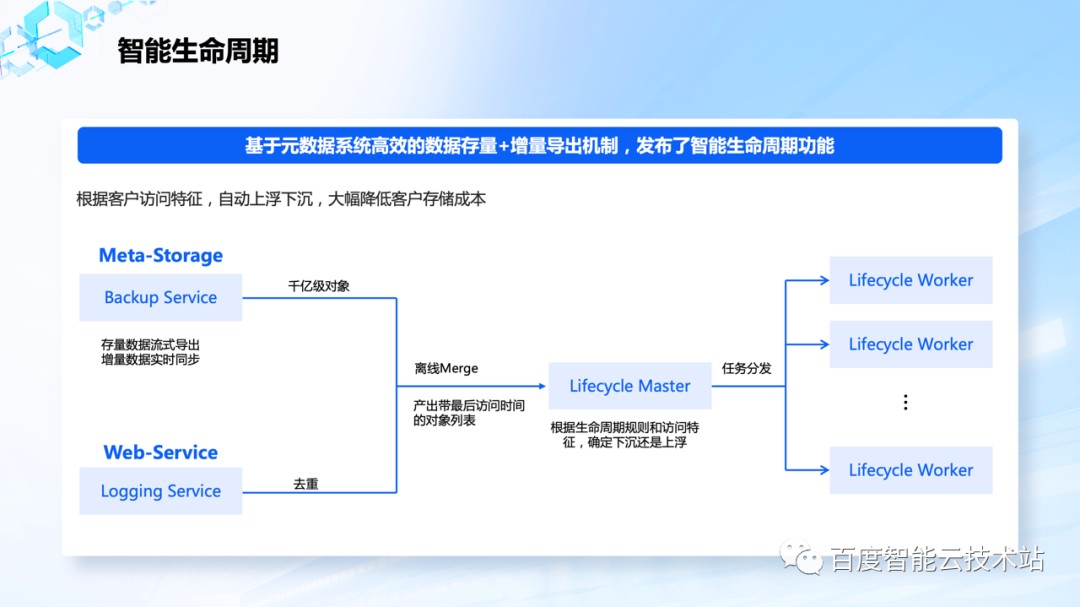
对于对象存储中的数据,生命周期比较理想的方式是,数据长时间没有访问,就下沉到一级,如果更长时间没有访问,就再下沉一级,如果有多次访问,还能自动上浮。
如果要实现这种生命周期机制,比较大的挑战是如何获取对象的最后访问时间,因为对象存储的访问量极大,每天有千亿次,这样的访问量如果每次读的时候都写一次元数据系统,更新一次时间戳,需要付出非常多的额外成本。
我们采用的是离线获取的方式,在设计元数据系统的的时候就考虑了这个场景,支持了高效的数据存量和增量导出机制,每天可以导出千亿量级的数据,跟去重之后的访问日志做离线 Merge,产生对象的最后访问时间戳,再根据生命周期规则和访问频度做下沉还是上浮的操作,该功能上线后大幅降低了客户的存储成本。
相关文章推荐
发表评论
关于作者

- 被阅读数
- 被赞数
- 被收藏数
登录后可评论,请前往 登录 或 注册