AI推理加速原理解析与工程实践分享
2023.06.15 15:17浏览量:2758简介:这次分享将端到端分析 AI 推理过程以及痛点,介绍业界典型的推理加速思路和具体方案。
在上一期分享中我们介绍了关于 AI 训练加速的原理和实践,本次分享我们将介绍如何加速 AI 推理过程。内容主要包括四部分:
第一部分,端到端的分析 AI 推理的过程以及这个过程中的痛点;
第二部分,我们将介绍业界典型的推理加速思路及具体方案;
第三部分,介绍百度百舸平台的 AI 推理加速套件 AIAK-Inference 的加速方案;
最后一部分,我们则将通过 demo 的方式,演示 AIAK-Inference 的使用方式及加速效果。
1. AI 推理的痛点
AI 推理是将用户输入的数据,通过训练好的模型产生有价值信息的过程。具体的是将训练好的 AI 模型部署到提供算力的硬件上,并通过 HTTP/RPC 等接口对外提供服务。
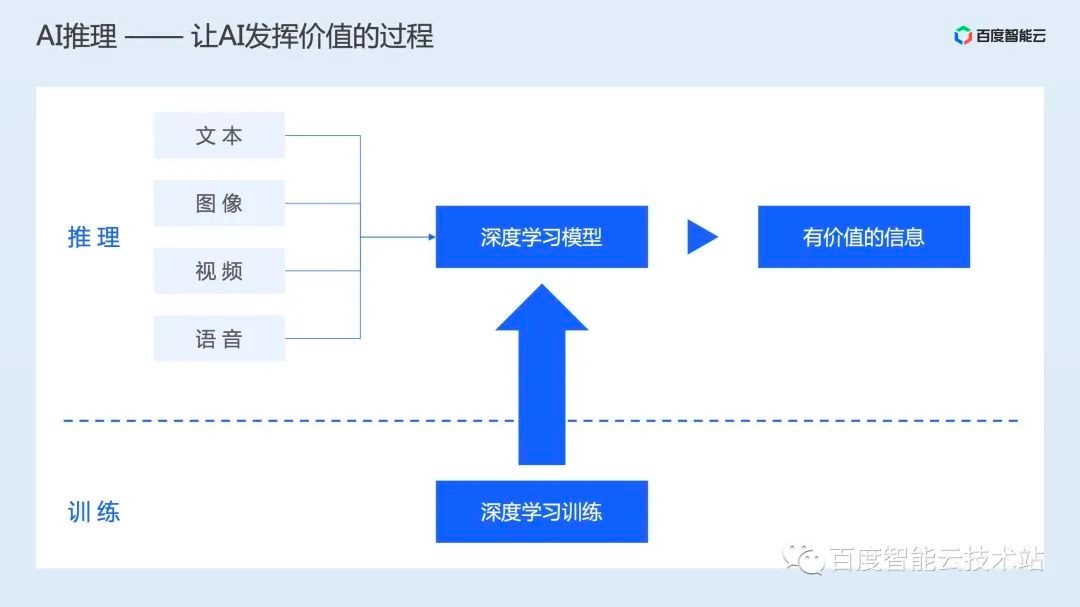
这个过程的参与者主要有两类人,一类是 AI 算法工程师,他们希望能将自己研发的模型高效的部署到线上,并为模型最终的效果负责。另外一类人则是基础架构工程师,他们负责管理异构算力集群,并为集群的资源利用效率负责。
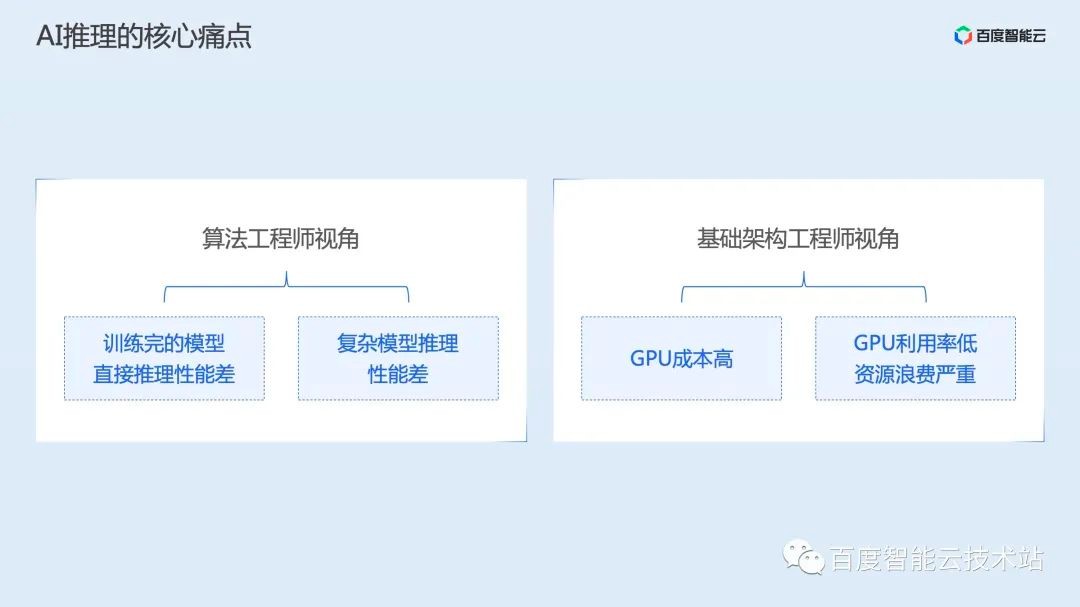
这两类人群的痛点分别如下:
对 AI 算法工程师来说,他们希望自己训练的复杂模型可以更快的提供服务。而对于基础架构工程师来说,他们则希望可以将价格昂贵的 GPU 资源发挥出效能。
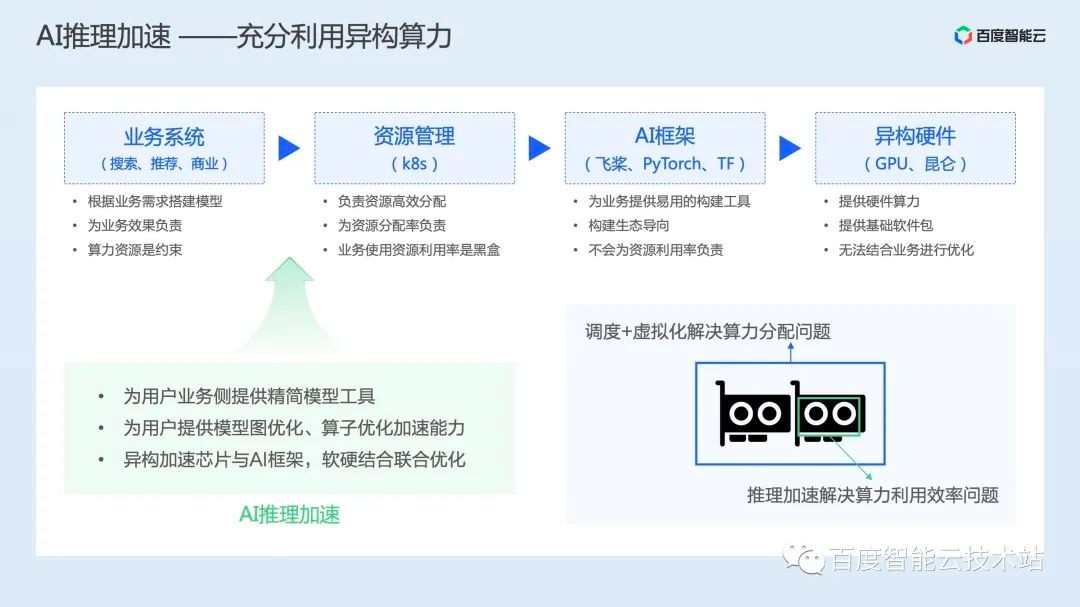
如果我们从端到端的视角再来分析下整个 AI 推理过程,会发现这两类用户的痛点目前没有得到很好的解决。
用户对 GPU 的使用初始于业务系统,用户根据业务需求搭建模型,并为最终模型的效果负责。
业务系统构建完成后,会从资源管理系统中申请资源,而资源管理器则会将 GPU 卡分配给业务系统,这个管理器只会为资源分配率负责,而不会关心资源分配后的业务使用效率。
用户在申请到资源后,会通过 AI 框架执行模型的计算过程。AI 框架更专注为用户提供易用的模型构建接口,而不会为业务的推理效率和资源利用率负责。
最后 AI 框架在使用异构硬件算力时,只能使用基础的加速包或工具,而不会专门结合业务特点进行优化。总的来看,整个过程中没有专门的工具为 GPU 算力的利用效率负责。
为此,我们需要 AI 推理加速,针对用户训练好的模型进行针对性的加速,缩短业务推理时间,同时提升资源利用率。
2. 推理加速的业界解决方案
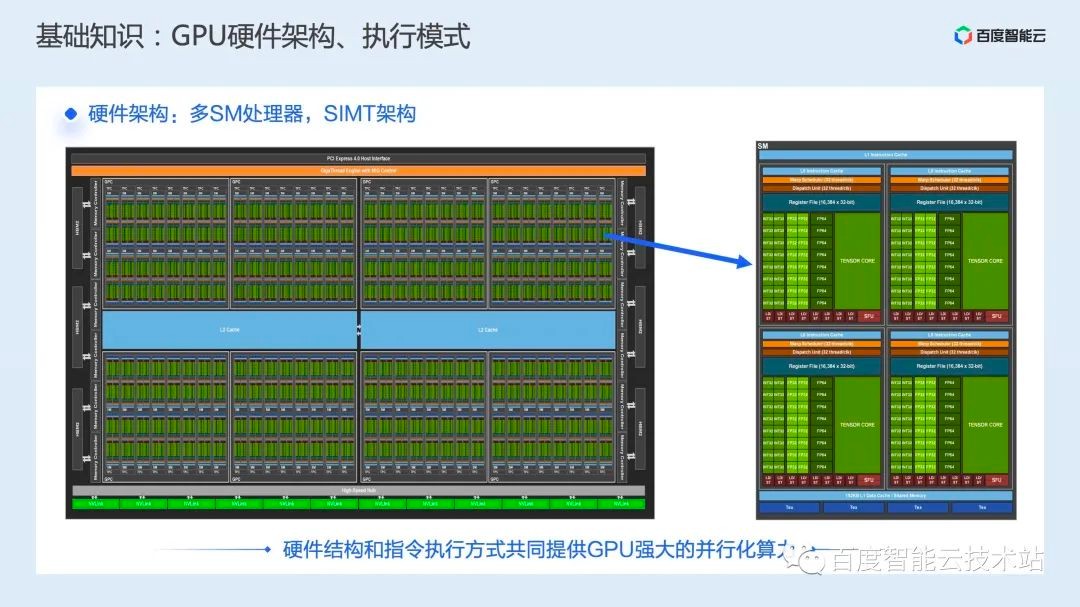
为了系统性的分析和进行推理加速方案,我们首先需要能够定义推理加速的优化目标。为此我们先简单回顾下 GPU 的硬件架构和执行模式。
从硬件上看,GPU 的强大算力来源于多 SM 处理器,每个 SM 中包含多个 ALU 计算单元和专有的 Tensor Core 处理单元。对 GPU 来说,当所有 SM 上的所有计算单元都在进行计算时,我们认为其算力得到了充分的发挥。
GPU 无法自己独立工作,其工作任务还是由 CPU 进行触发的。
整体的工作流程可以看做是 CPU 将需要执行的计算任务异步的交给 GPU,GPU 拿到任务后,会将 Kernel 调度到相应的 SM 上,而 SM 内部的线程则会按照任务的描述进行执行。当 CPU 不发起新的任务时,则 GPU 的处理单元就处在空闲状态。

通过这两个层面的分析,我们知道要想将 GPU 的算力充分发挥,其核心就是保持GPU 上有任务,同时对单个 GPU 计算任务,使其可以尽量充分的用好 SM 处理器。
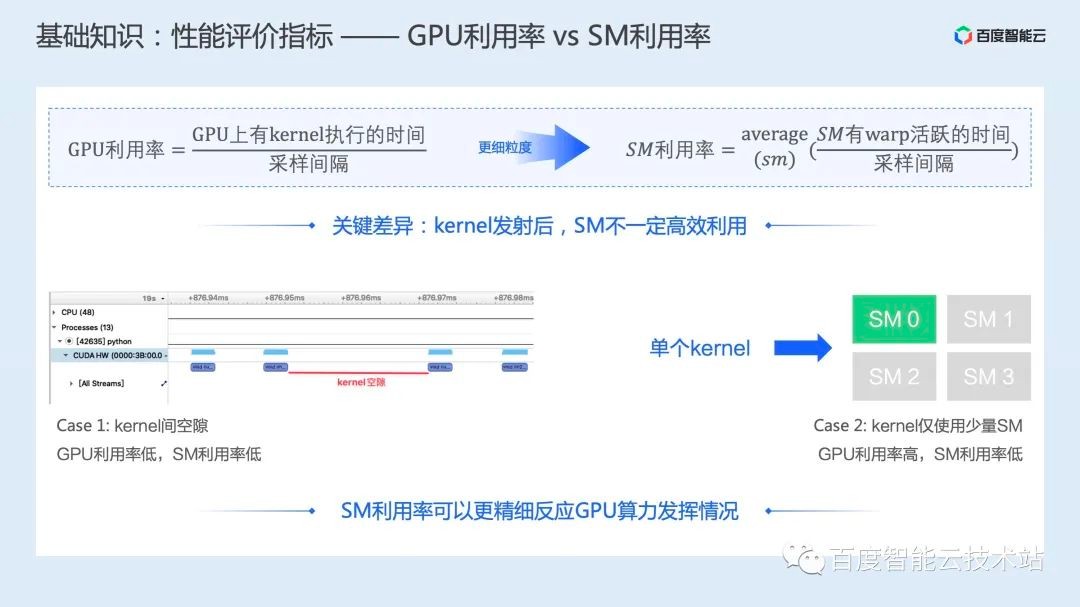
针对这两个层面的使用情况,NVIDIA 提供了相应的牵引指标 GPU 利用率和 SM 利用率:GPU 利用率被定义为在采样间隔内,GPU 上有任务在执行的时间。而 SM 利用率则被定义为在采样间隔内,每个 SM 有 warp 活跃时间的平均值。
我们可以通过 2 个 case 来比较下这两个指标的差异。在下图的 case 1 中,由于 CPU 异步发射任务到 GPU 上,GPU 很快就处理完了,于是就出现了等待下一个任务的空隙。在这种情况下,按照定义,GPU 利用率比较低,SM 利用率也相对较低。两个指标都能反应这种情况没有充分利用 GPU 资源。
针对下图的第二个 case,对于某一个 Kernel 来说,由于计算实现、参数配置等一系列问题,它只使用了 1 个 SM 处理器,而剩下的 3 个 SM 处理器(假设只有 4 个 SM 处理器)空闲。
对于这种情况,由于 GPU 上有 Kernel 在执行,在这个时间段内 GPU 利用率仍然是 100%,但 SM 利用率只有 25%。可以看到这种场景下,SM 利用率可以反应计算任务效率不高的问题,而 GPU 利用率则无法反应此类问题。
我们认为 SM 利用率可以更精细的反应 GPU 算力发挥情况,所以把 SM 利用率当做 AI 推理加速的牵引指标。
有了牵引指标,结合模型执行的流程,我们就可以在逻辑上将优化方案分为三类:
第一类优化是模型精简类,即在模型真正执行之前就对模型的计算量进行精简,从而提升推理速度。这部分业界常见的优化方向包括量化、减枝、蒸馏和 NAS 等;
第二类和第三类则是当模型已经交由推理引擎在 GPU 上执行时,如何更好的提升 GPU 的利用效率。
我们由 SM 利用率公式做一个近似可以导出这两类优化方案,分别是尽可能让 GPU 上有计算任务和单个计算任务在 GPU 上执行效率更高。这两类优化方案常见的手段分别是算子融合和单算子优化。
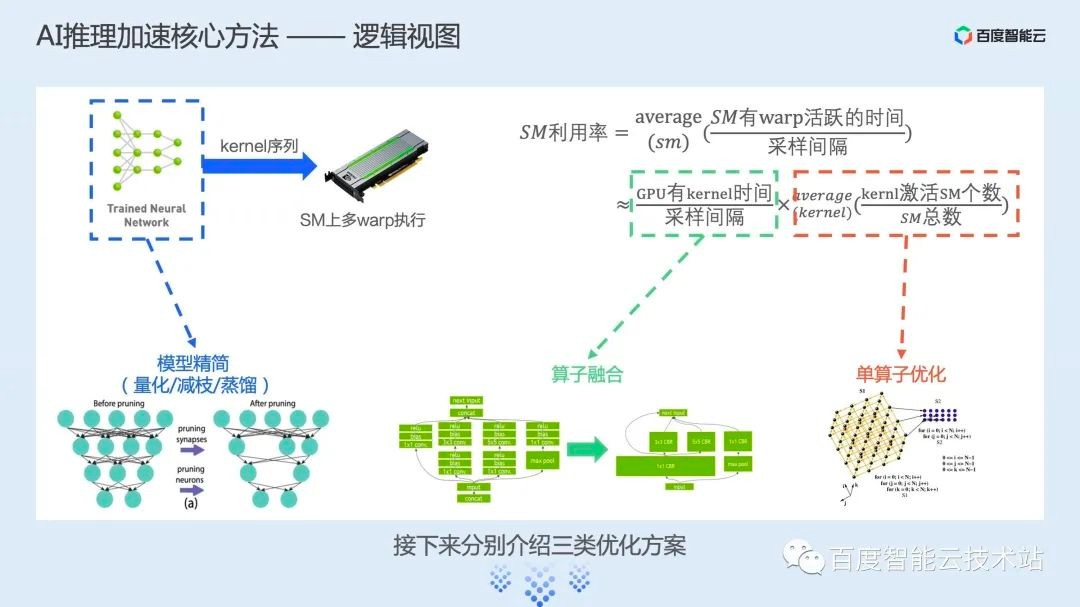
接下来分别介绍这三类优化方案。
在模型精简上,通常大家会采用量化、减枝和蒸馏等手段。
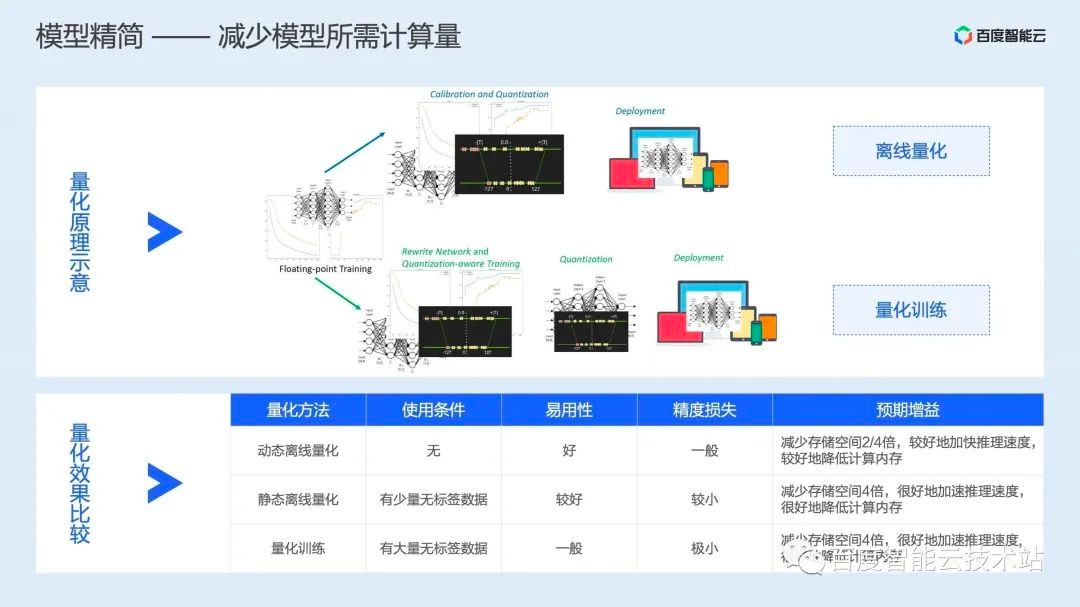
简单来说,量化就是将模型中的计算类型进行压缩,从而降低计算量。常见的手段包括离线量化和量化训练两类。
离线量化是指在模型训练完成后,离线的对计算算子进行量化,这种方案通常易用性较好,对算法开发人员几乎透明,但对模型精度会有一定损失;
量化训练则是在模型训练过程中就显示插入量化相关的操作,这样通常会有更好的精度,但需要算法开发同学准备相关数据。
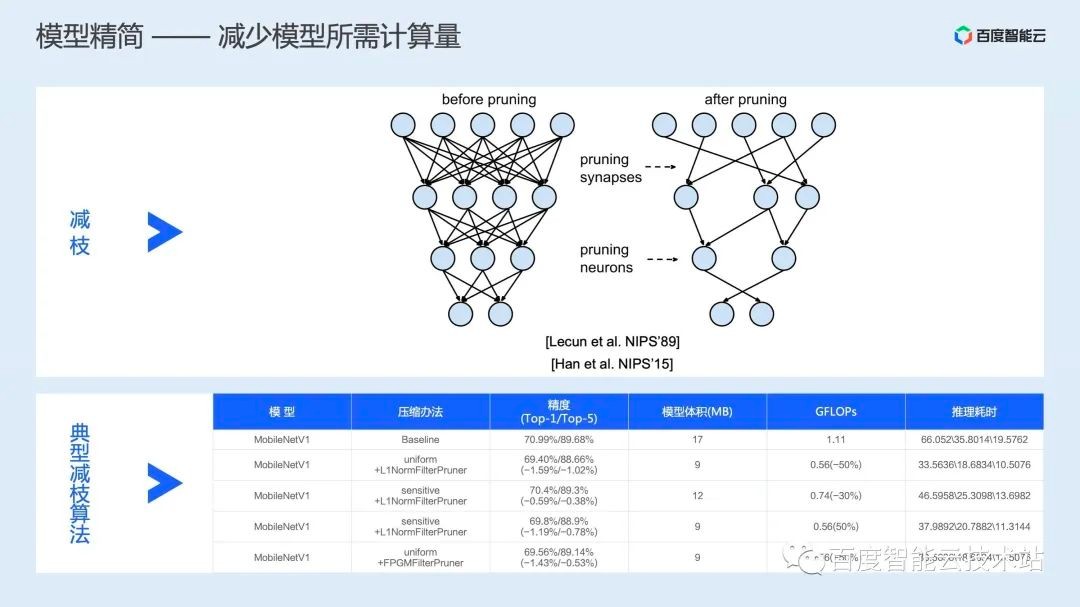
而减枝则是通过将模型中对结果影响较小的一些计算进行移除,从而降低计算量。
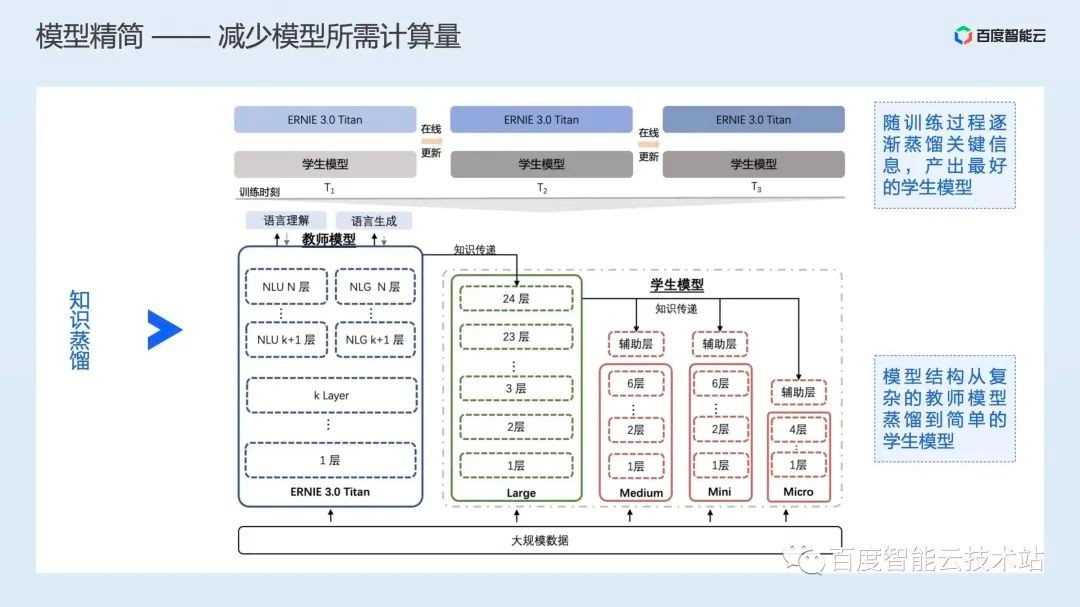
蒸馏则通常是将一个复杂的大模型通过降维的知识传递层,将大模型中的复杂计算,减少为效果相当的更小规模的计算,从而实现降低计算量,提升推理效率的效果。下图中是百度文心 3.0 大模型知识蒸馏的过程。
这些模型精简的方案,由于涉及到对精度的影响,通常需要算法工程师介入,协同优化。
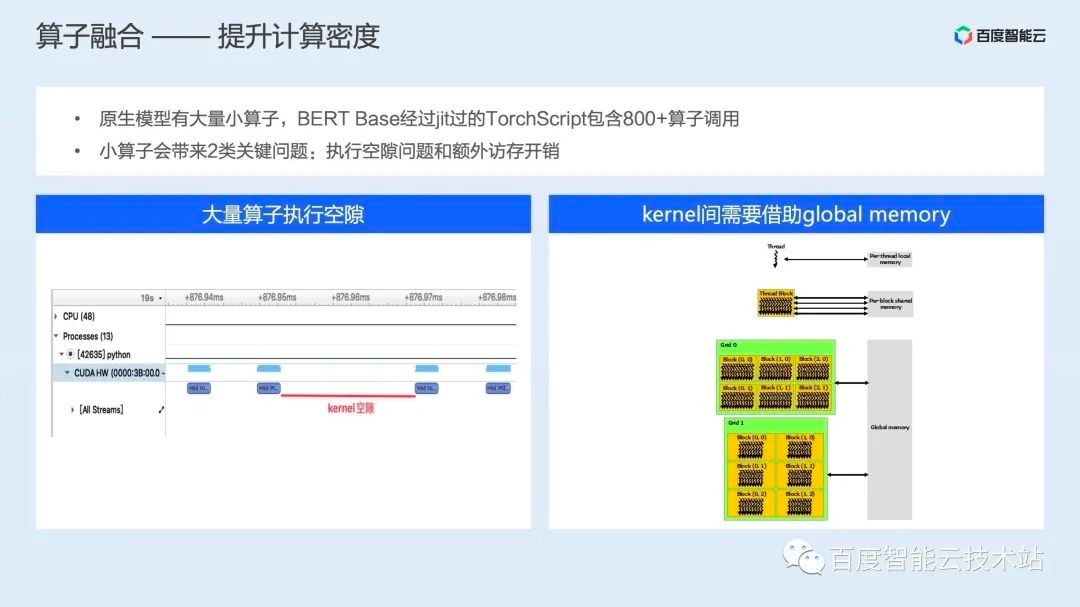
第二类优化则是算子融合,算子融合顾名思义是指将多个计算算子合并成一个大算子的过程。
例如对于 BERT Base 这个模型,经过 PyTorch 原生 jit 编译生成的 TorchScript 图中有 800 多个小算子,这些小算子会带来 2 类问题:一是这些算子通常执行过程较短,因此会造成大量的 GPU 空闲时间;二是由于不同的任务之间还有数据的依赖,因此也会带来额外的访存开销。
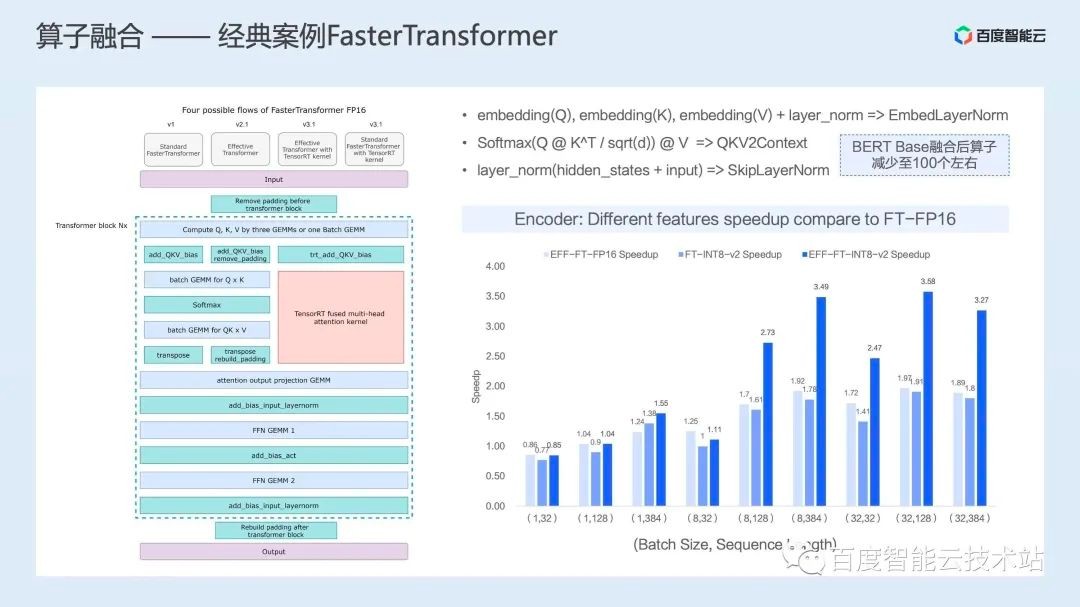
目前针对算子融合,业界通常会采用手写或自动化生成的方式发现可融合的模式,并提供融合后的算子。例如针对 Transformer 结构,NVIDIA 开发了 FasterTransformer 这个库,其中包括针对多种 Transformer 类结构模型的具体融合算子。
例如下图中,针对 batch GEMM Q x K、Softmax、batch GEMM for QK x V 和长尾的 transpose 等操作,FasterTransformer 提供 Fused Multi-head Attention 等融合后算子。BERT Base 在经过 FasterTransformer 的算子融合优化后,数量可以降到 100 个左右。
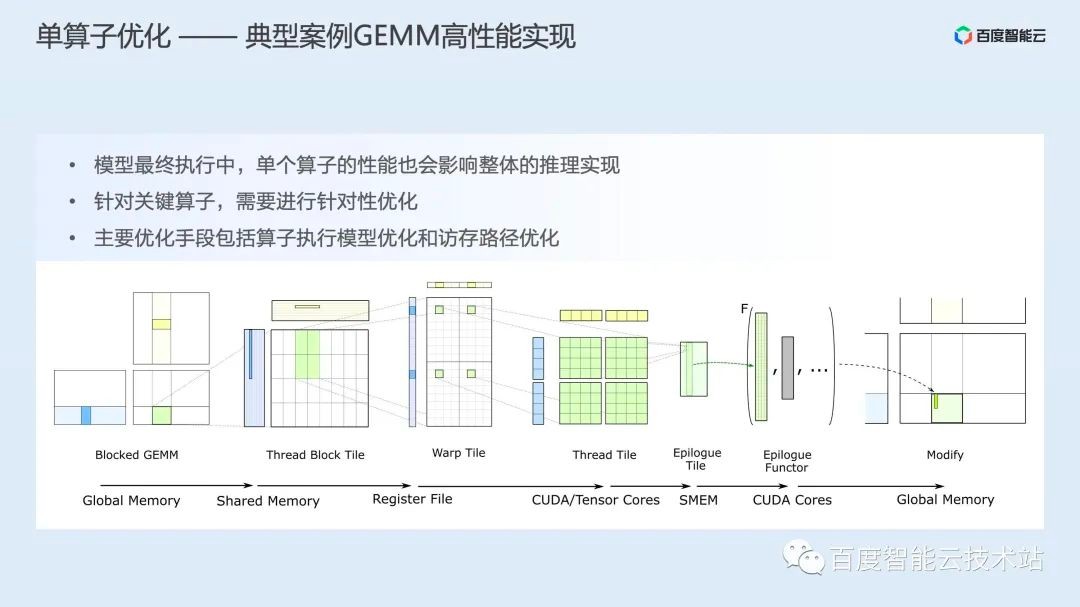
第三类优化则是单算子优化。单算子优化是根据单个算子,结合计算模式和硬件架构特点,调整 GPU 核函数的实现方法,从而提升具体算子的执行效率。单算子优化中,最经典的例子就是对通用矩阵乘(GEMM)的优化。
下图是 NVIDIA Cutlass 库对 GEMM 操作的抽象:
Cutlass 结合 GPU Global Memory、Shared Memory、Register File 这几层存储架构和 block、warp、thread 和 tensor core 这几层计算抽象,设计了一系列计算模板,并提供相关可优化参数(切分大小等),方便开发者开发高性能的 GEMM 实现。
以上就是业界常见的几类 AI 推理加速的方法和业界的一些解决方案。接下来我们重点介绍下 AIAK-Inference 是如何站在巨人的肩膀上,提供性能更好的推理加速方案。
3. AIAK-Inference推理加速套件简介
AIAK-Inference 是百度智能云提出的 AI 推理加速套件,是百度百舸整体方案中的一部分。
AIAK-Inference 旨在优化在百度智能云上采购的 GPU 等异构算力的推理效率,降低推理延迟,提升推理吞吐。只要通过百度百舸方案提供的 GPU 算力,都可以使用AIAK-Inference 进行推理加速。
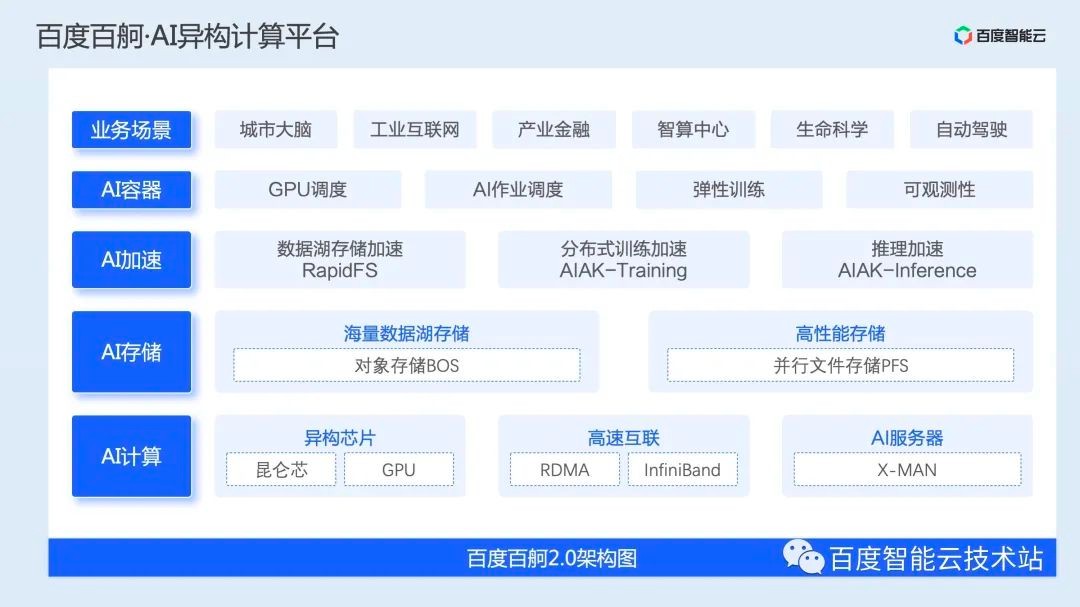
AIAK-Inference 的整体架构如下图所示,整体分为 4 个层次,分别解决的问题如下:
图接入:解决多框架动态图/静态图捕获问题,将动态图转换为推理友好的静态图;
后端抽象:支持将业界多种优化方案统一整合,通过计时的方式选择最优的加速后端;
具体加速后端,支持业界多种开源加速后端,包括飞桨提供的 FastDeploy 等;此外还有一套自研加速后端,通过图优化、图转换和加速运行时三部分对模型进行整体的推理加速;
算子库:除了使能业界最优的常见计算算子库,还针对具体场景的重点计算模式进行定制化开发,提供场景加速的算子库。

与业界其他方案相比,AIAK-Inference 主要有 2 大特点,第一个是博采众长,支持多种优化后端的无缝接入,并通过计时选优的方法将效果最后的加速后端提供给用户;第二则是深入场景,针对重点场景的计算模式,通过 AIAK-OP 算子库进行专有加速。
AIAK-Inference 的加速原理也类似第二节讨论的业界常见方案,主要从图精简、算子融合、算子优化几个层面展开:
在图精简上,AIAK-Inference 除了兼容社区常见的量化、减枝、蒸馏、NAS 等方案,还提供一些数学等价代换、死代码移除等精度无算的图精简操作;
在算子融合上,AIAK-Inference 支持访存密集型算子融合、GEMM/Conv 长尾运算融合和背靠背 GEMM 融合等多种融合策略;
而针对具体的单个算子,AIAK-Inference 则通过调度、访存、模板化优化等思路,实现了一系列高性能场景化算子。
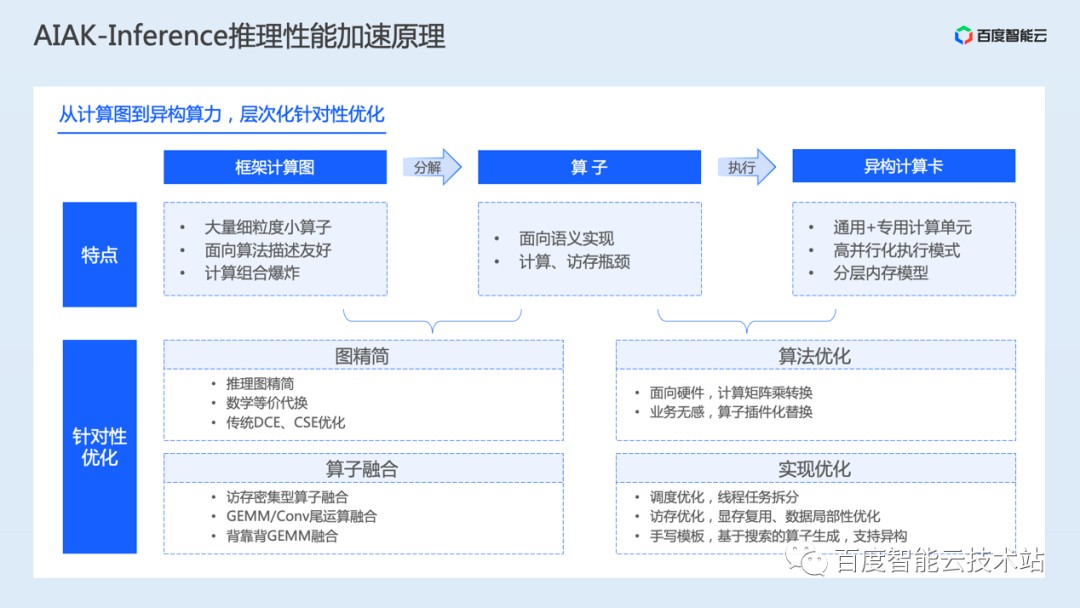
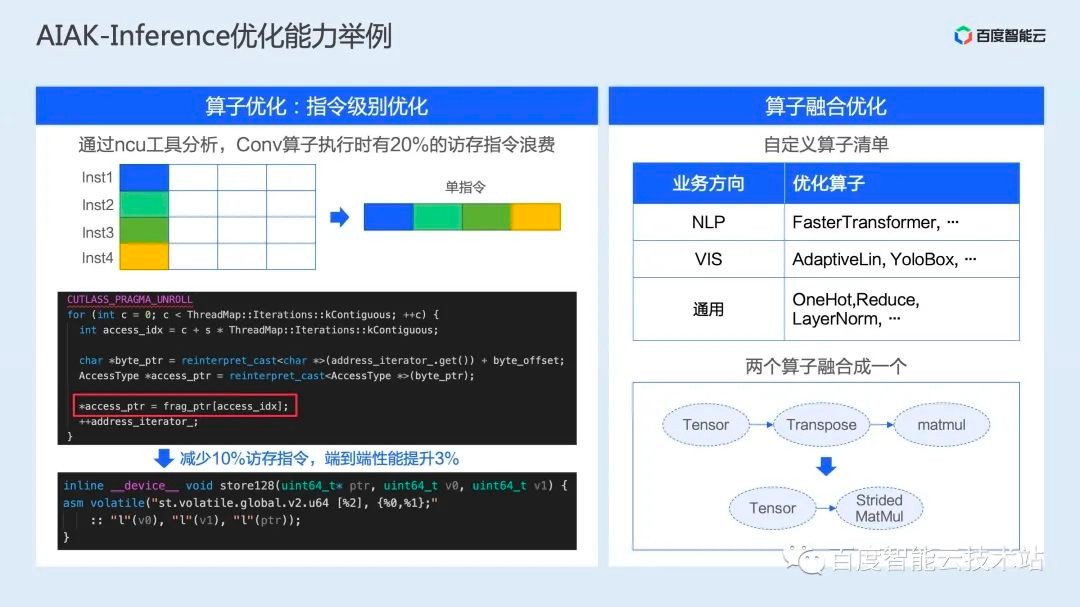
具体举几个例子,对于单算子优化,我们通过 ncu 工具发现我们生成的 Conv 算子执行时有 20% 的访存指令浪费,通过将访存操作聚合,减少访存操作,最终模型端到端性能提升 3%。
算子融合上,我们针对 NLP、CV 场景开发了相应的重点融合算子(如 FMHA、YoloBox 等),并在通用场景针对卷积 + 长尾操作生成了一系列融合算子。
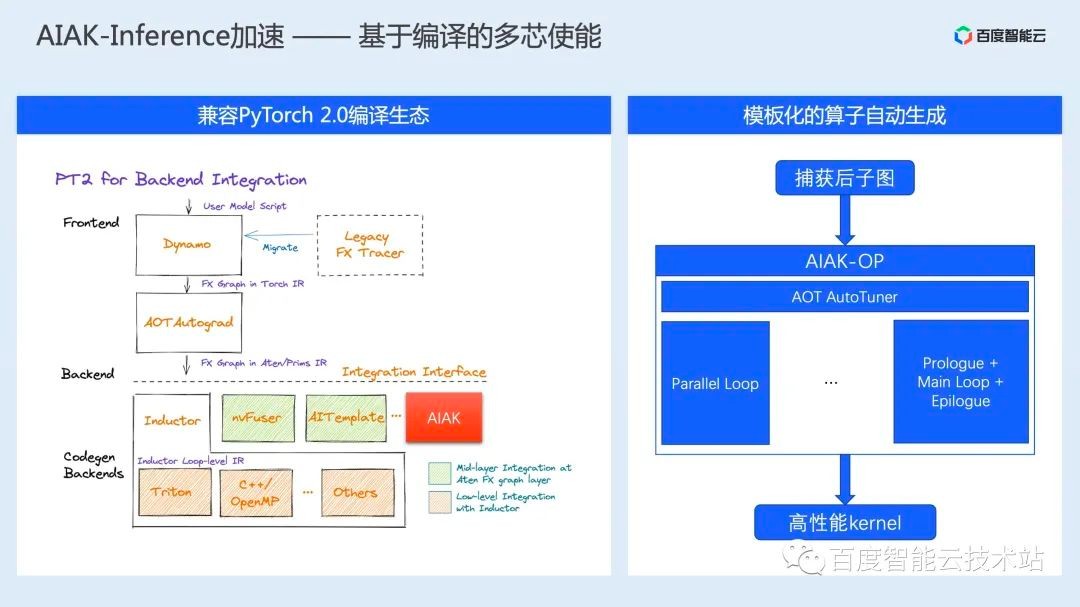
除了这些之外,我们还紧跟社区生态,正在开发适配 PyTorch 2.0 编译生态的 Dynamo 编译 Backend;在算子生成方面,我们也开发了一套针对模板的自动化算子生成方案。
以上就是 AIAK-Inference 推理加速套件的整体介绍,我们接下来看看如何在百度智能云上使用推理加速套件。
4. 使用 AIAK-Inference 推理加速套件
首先整体介绍下 AIAK-Inference 推理加速套件在 AI 推理流程中的位置。
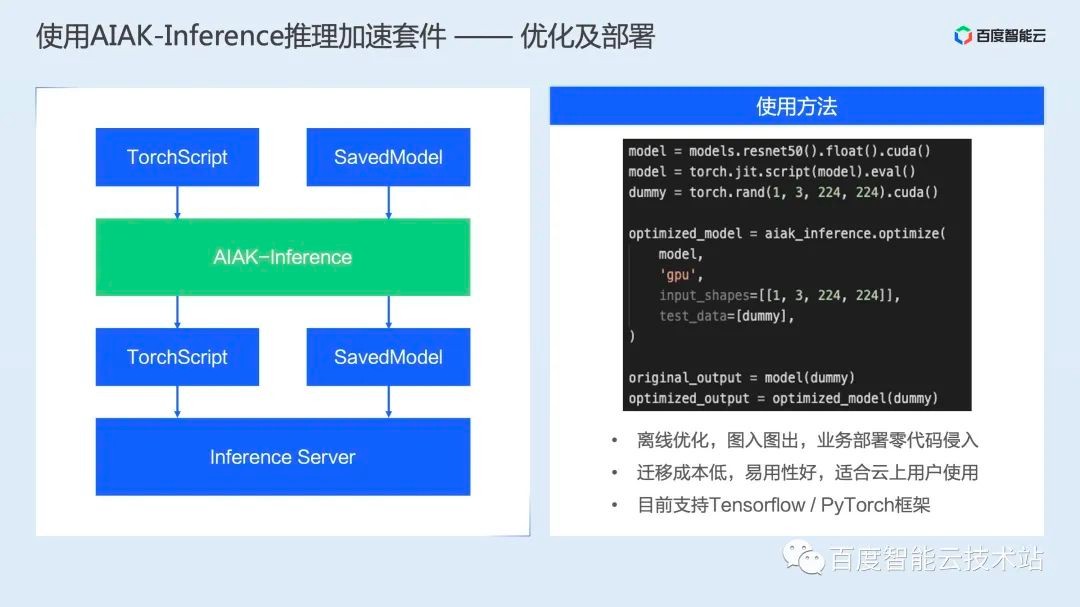
如下图所示,AIAK-Inference 是通过优化推理模型进行推理加速的。具体的说,算法工程师原来进行模型部署,是将 TorchScript/SavedModel 等训练好的模型通过 Inference Server 进行部署。
而 AIAK-Inference 则是在部署之前增加一个流程,通过开发一个核心只有 1 行代码的优化脚本,通过 aiak_inference.compile 优化接口,对 TorchScript/SavedModel 等模型进行优化,并返回优化后的模型。
用户可以将优化后的模型仍然部署到 Inference Server 上,部署无感的进行加速。总结下来就是优化代码离线化改造,业务部署零代码侵入。
了解了整体使用方式后,我们来具体操作一下。
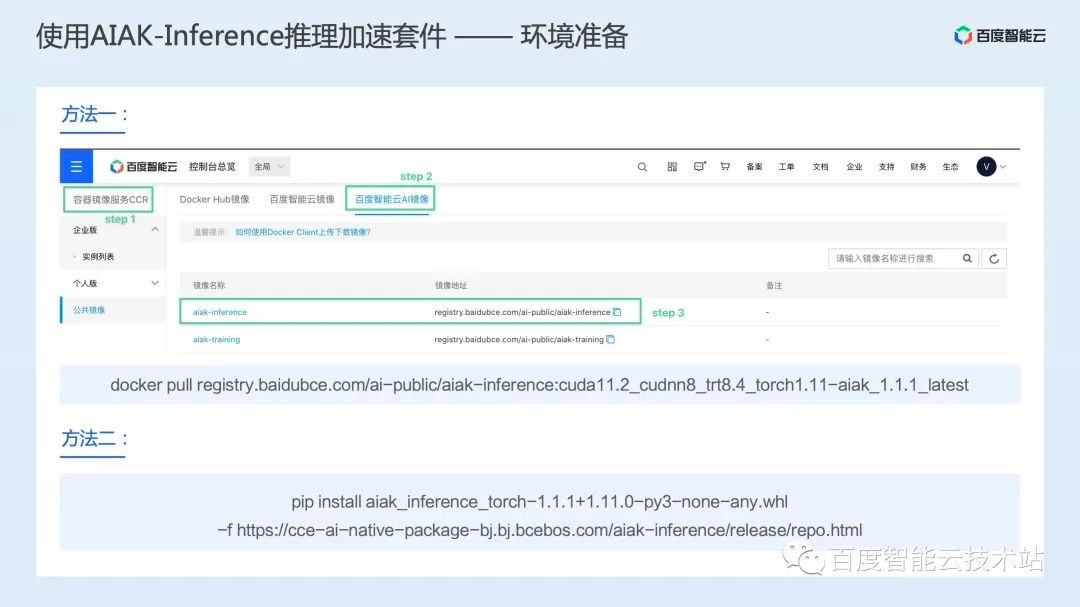
首先为了使用 AIAK-Inference 推理加速套件,需要进行环境准备。AIAK-Inference 提供加速镜像和 wheel 包两种安装方法,无论哪种方案,用户只需要下载对应的镜像或安装 wheel 包,即可完成环境准备。
环境准备完成后,只需要开发刚才演示的一个优化脚本,即可完成模型的优化。接下来以 ResNet50 模型为例,进行一个完整流程的演示。
AIAK Inference 操作演示视频
本次演示中使用了 2 个脚本,分别是 infer.py 和 optimize.py。其中 infer.py 是模拟用户部署的脚本,简单看下代码可以看到,这个脚本主要是加载模型,进行 100 次预热操作,然后执行 1000 次推理,并在 CPU 侧完成计时。
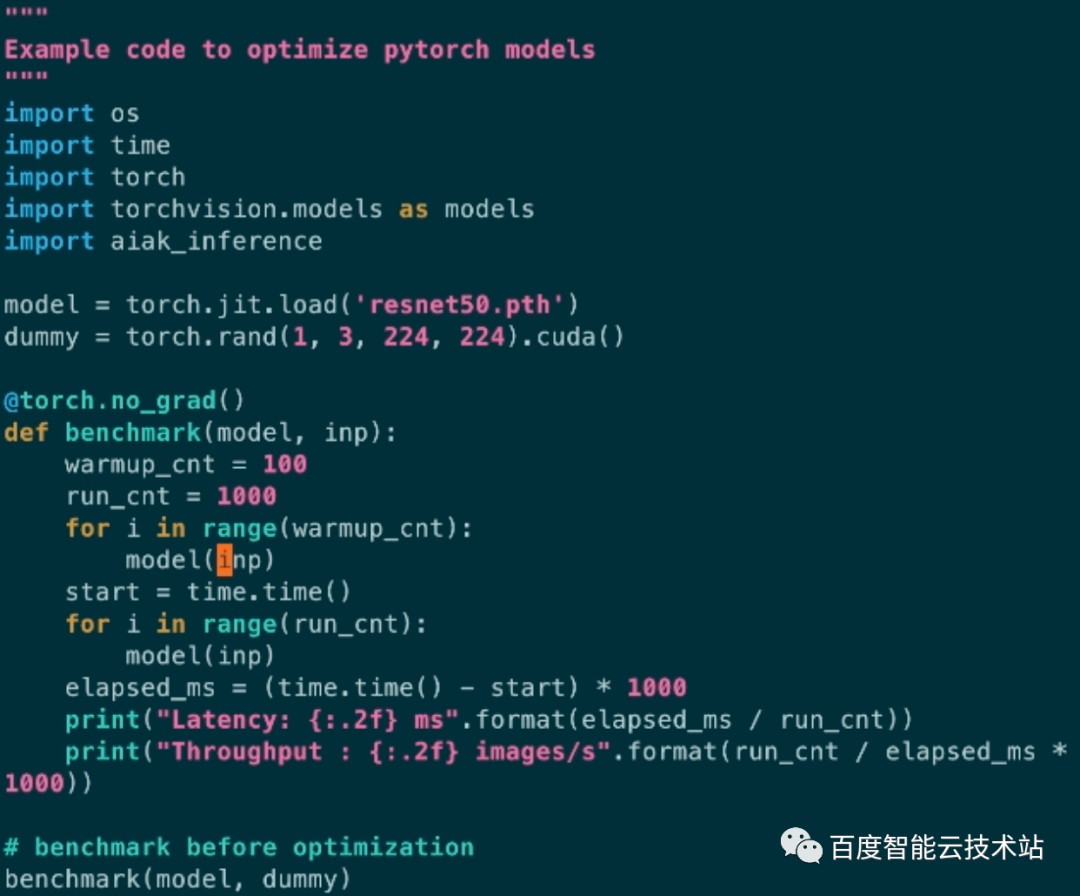
简单执行这个脚本,可以看到 FP32 精度下,BS=1 的 ResNet50 在 T4 平台上,推理平均延迟是 6.73ms。

接下来使用 AIAK-Inference 对模型进行优化。这里我们使用 optimize.py 脚本,其代码如下:
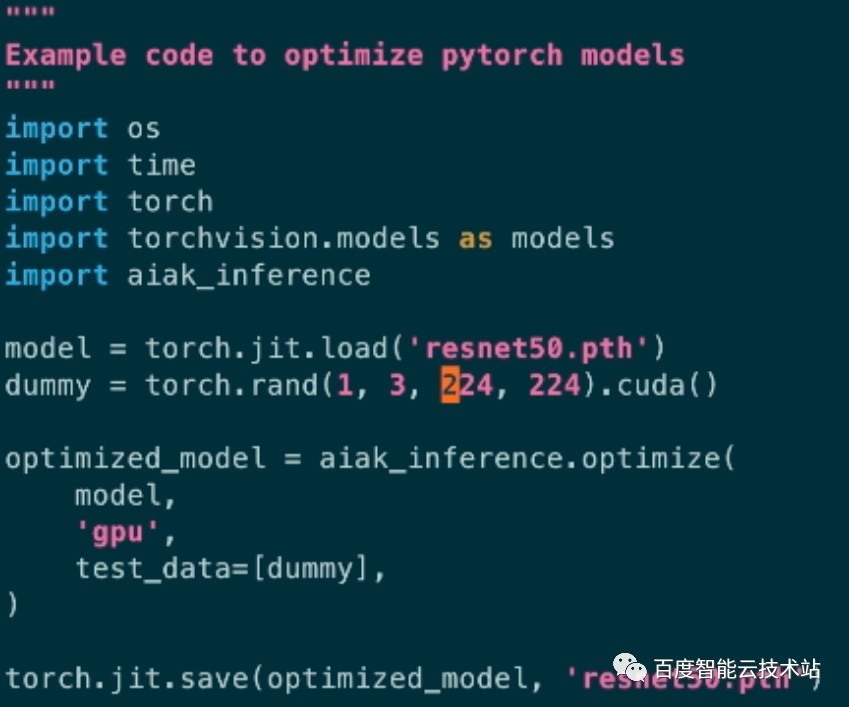
整体代码非常简单,加载模型,调用 aiak_inference.optimize 接口进行优化,并将优化后的模型进行保存。这里为了演示我将优化后的模型保存成与优化前模型同名的模型。
有了优化后的模型,我们什么都不做改动,再次执行 infer.py(即模拟业务部署代码零改动),可以看到模型推理耗时大幅降低,只需要 3.54ms。
从而可以看出使用 AIAK-Inference 可以通过简单的脚本对模型进行透明优化,优化后的模型在推理效率上有大幅提升。

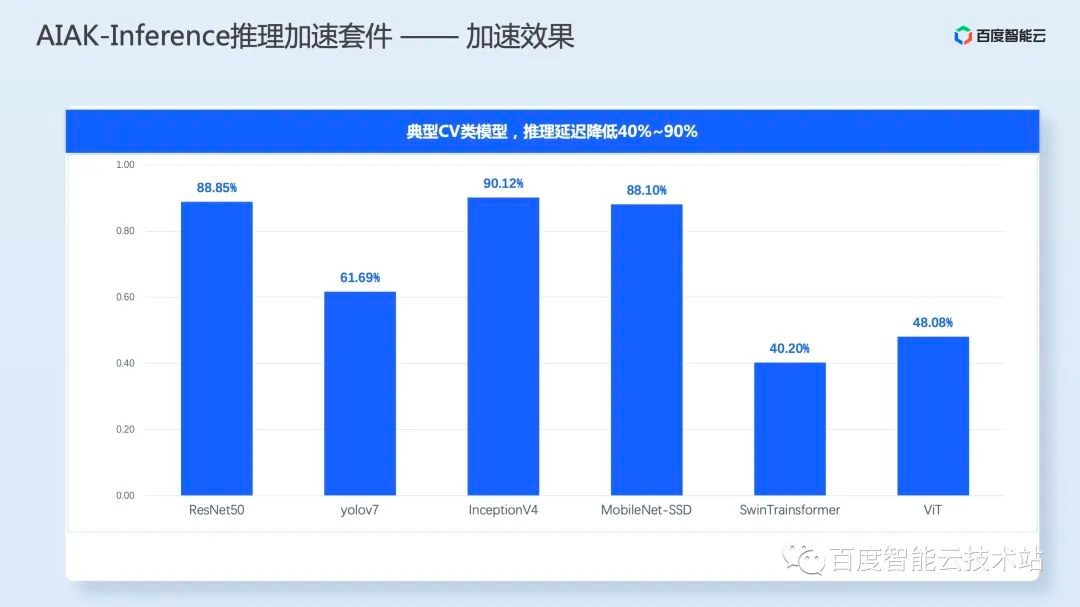
除了刚才演示的单个模型,AIAK-Inference 还在多个模型上验证了效果。下表是 6 个典型 CV 类模型,可以看到推理延迟分别降低 40%~90%。
以上就是今天分享的全部内容,谢谢大家。

发表评论
登录后可评论,请前往 登录 或 注册