生物计算大模型技术在药物研发领域的应用
2023.03.31 14:43浏览量:970简介:本文将首先概述当前全球生物医药在 AI 领域的发展趋势。
本文将首先概述当前全球生物医药在 AI 领域的发展趋势,然后分享百度智能云生物计算大模型技术、以及在产业智能化上的实践。
1. 生物医药产业的趋势和应用 AI 的技术挑战
从全球视角看,生物医药产业的需求处于一个高速增长的状态。但与之矛盾的是,当前生物医药产业正面临着反摩尔定律,现在 10 亿美金已经造不出一款新药。这种矛盾也催生了产业界对新技术的渴求。
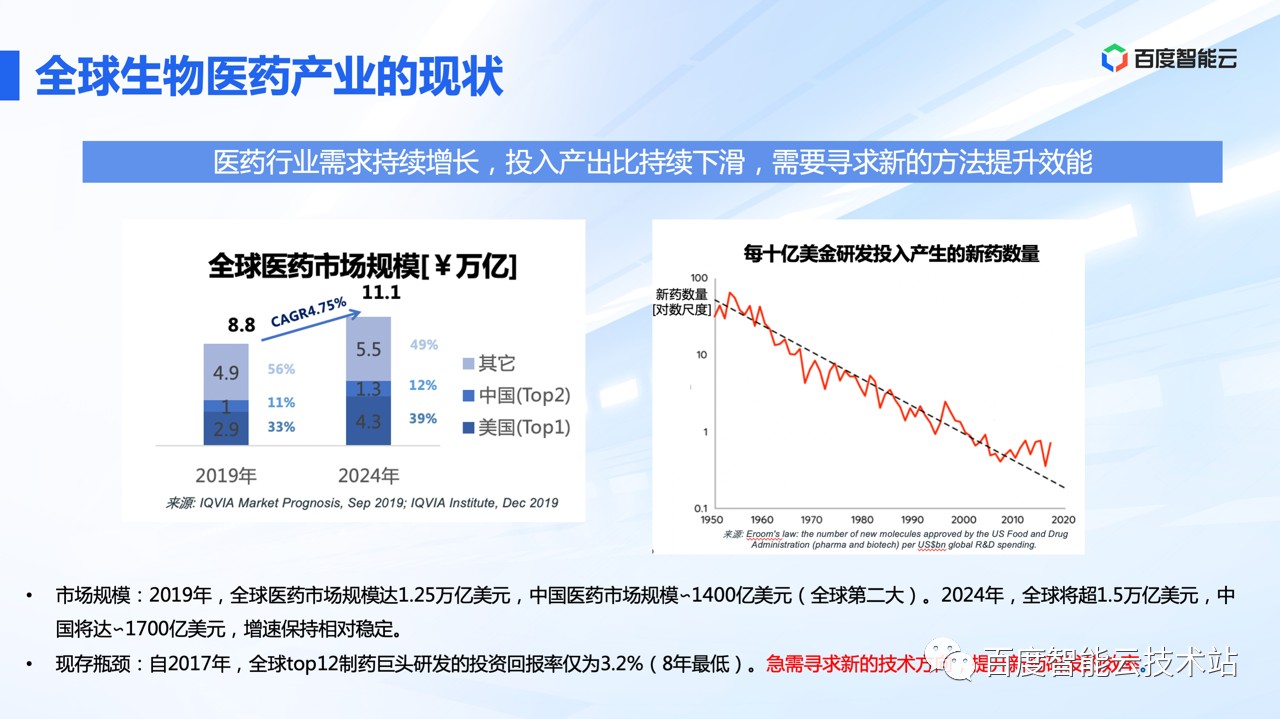
从国内视角看,当前的生物医药产业在政策和技术的双重驱动下,迎来了新的发展机遇。
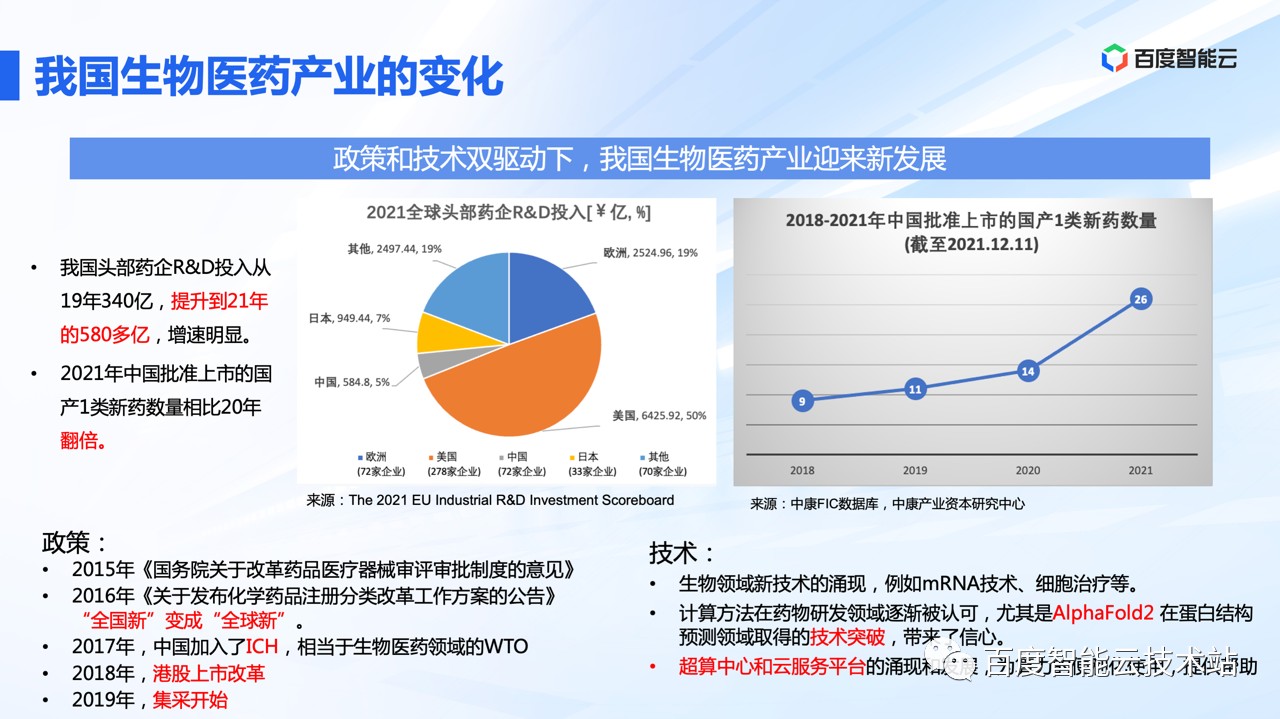
从头部药企的研发投入来看,2019 年到 2021 年头部药企的研发投入增长了近一倍。高研发投入也大大提高了产出,国内批准上市的 1 类新药,2021 年批准上市的数量是 18 年的近 3 倍。
在宏观政策的持续发力下,技术层面也迎来了诸多利好。除了生物领域新技术的涌现,AI 技术因为 AF2 在蛋白结构预测领域所取得的突破进展,带动了行业对 AI 技术的信心。
同时超算、智算等基础设施的发展普及,为 AI 技术在生物医药产业的落地创造了良好的条件。
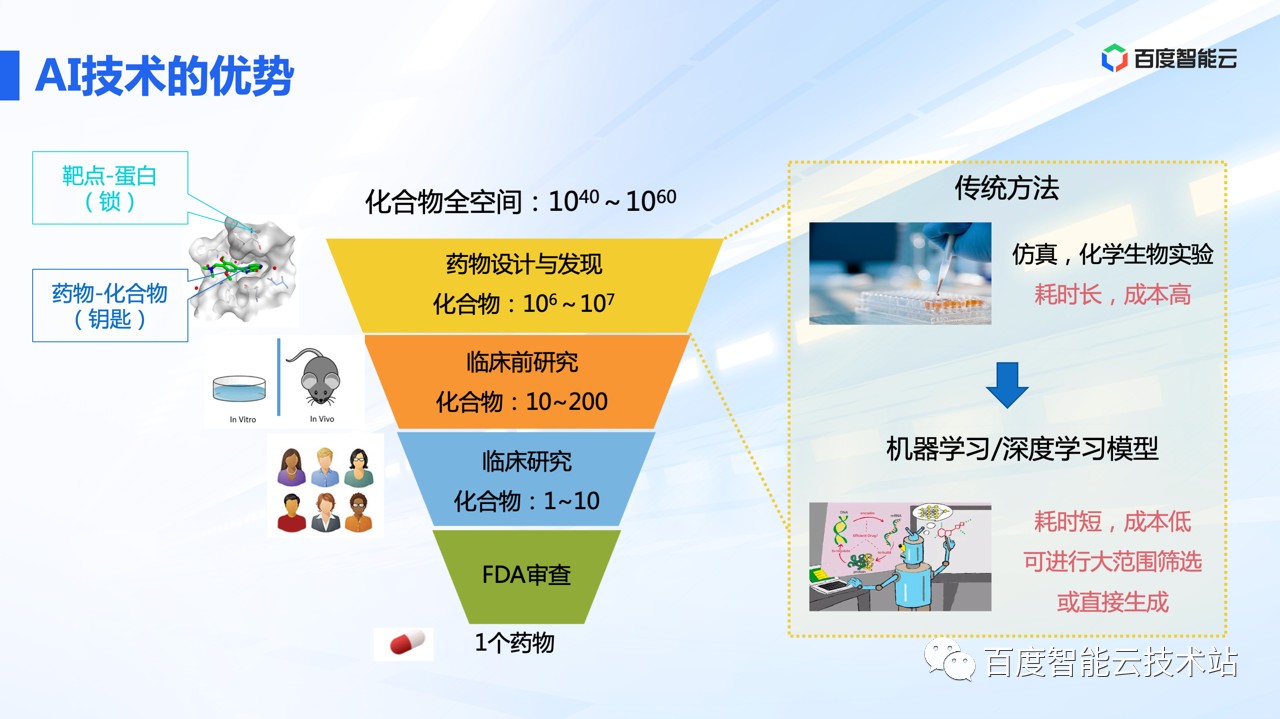
相比传统的高通量实验和仿真计算等药物设计的方法,AI 的方法核心优势在于提升效率上。
但是,AI 方法也面临了一些困难。
药物研发真实的高精度实验数据获取成本极高,且有实验的批次效应问题。另一方面,公开的数据库有大量的无标注数据,如何利用好大量无标注数据和少量高精度数据,这就对模型构建提出了较高的要求。
其次,生物领域的任务繁多且复杂。像 ADMET 成药性预测任务,常用属性指标多达几十项,想要一个模型对几十项指标都预测准确,这对技术的泛化性和可迁移能力也有较高的要求。
另外,生物领域相对知识门槛较高,不像图像和自然语言处理领域,算法工程师可以比较好的理解任务。但是生物领域有其独特的领域特性,比如对同分异构体的理解、研究对象需要建模三维结构等等。这些复杂且专业的生物领域知识,对算法研发人员提出了更高的要求。
最后,像是 AF2 这种中间计算量巨大的复杂的神经网络模型,还需要有强大的算力和框架技术的支持。
基于以上面临的挑战,百度智能云也提出了自己的技术解决方案。

2. 构建生物计算大模型技术
通过构建「数据和第一性原理双驱动」的文心·生物计算预训练大模型,以更好的在原子水平进行表征,使模型具备更好的外推能力和泛化性。
针对化合物、蛋白、RNA 等研究对象,通过海量数据,文心·生物计算预训练大模型学习到大量的生物化学知识。
在与功能更相关的结构和亲和力预测任务上,融合第一性原理,利用底层物理/化学规律驱动模型的构建,训练出外推能力更好的亲和力大模型,提升了模型的泛化能力,更好地支持小分子的药物设计、多肽/蛋白等设计任务。
我们希望将通用的大数据、大参数的预训练模型作为底座,在具体任务场景上,通过少量高精度的数据,进行 Fine-tuning 精调,提升具体场景的模型的效果,更好地解决生物计算领域的复杂场景问题。
百度将更多关注“亲和力大模型”、“表征大模型”两层底座模型的构建,我们也希望与更多合作伙伴一起,探索基于底座模型赋能上层应用的合作模式。

目前,在这个技术思路的指引下,我们面向小分子领域研发了 HelixGEM 系列模型。
HelixGEM-1 是 21 年的工作成果,在 22 年 2 月份正式发表在 Nature Machine Intelligence 期刊上。
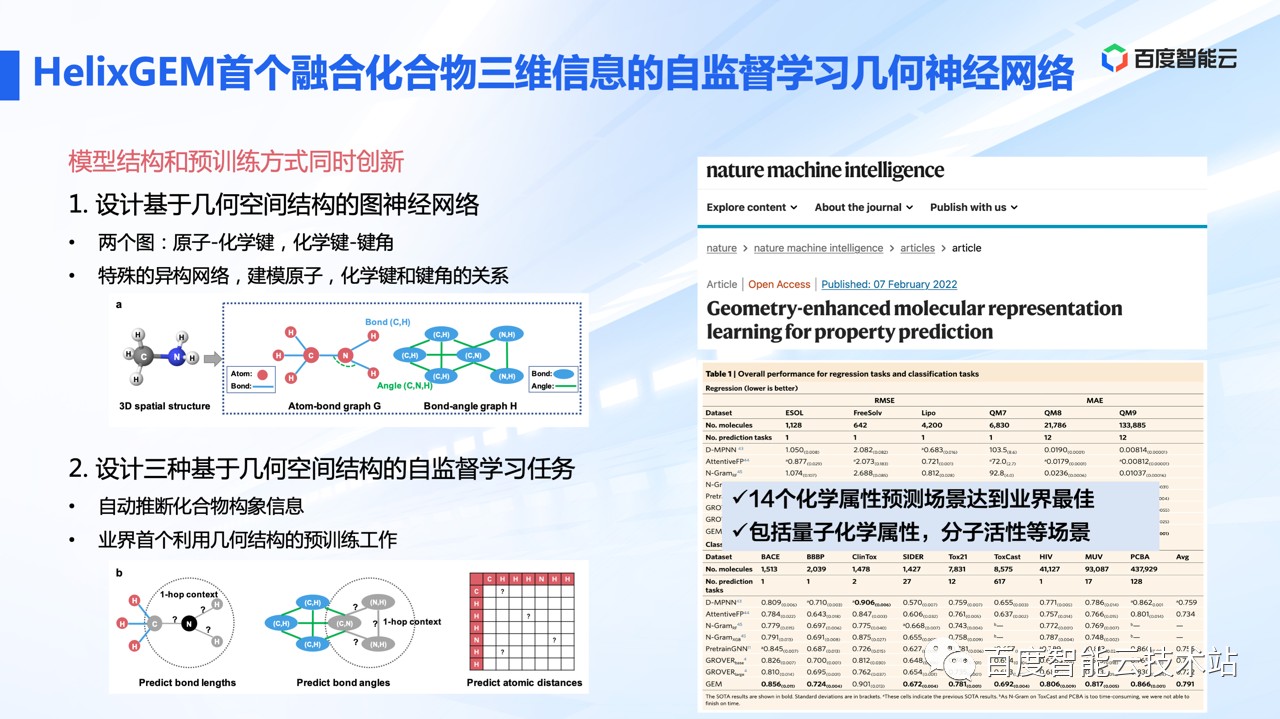
HelixGEM-1 使用 2000 万数据进行训练,是业内首个融合化合物三维几何空间构象信息的神经网络,进行自监督学习的工作。HelixGEM1 在 14 个药物属性相关的 benchmarks 都达到业界最优。
在此基础上,我们又进一步融合第一性原理,借鉴 AF2 的组合多轨机制,构建 HelixGEM 2 模型。这也是业内首个考虑原子间多体和长程交互的模型。
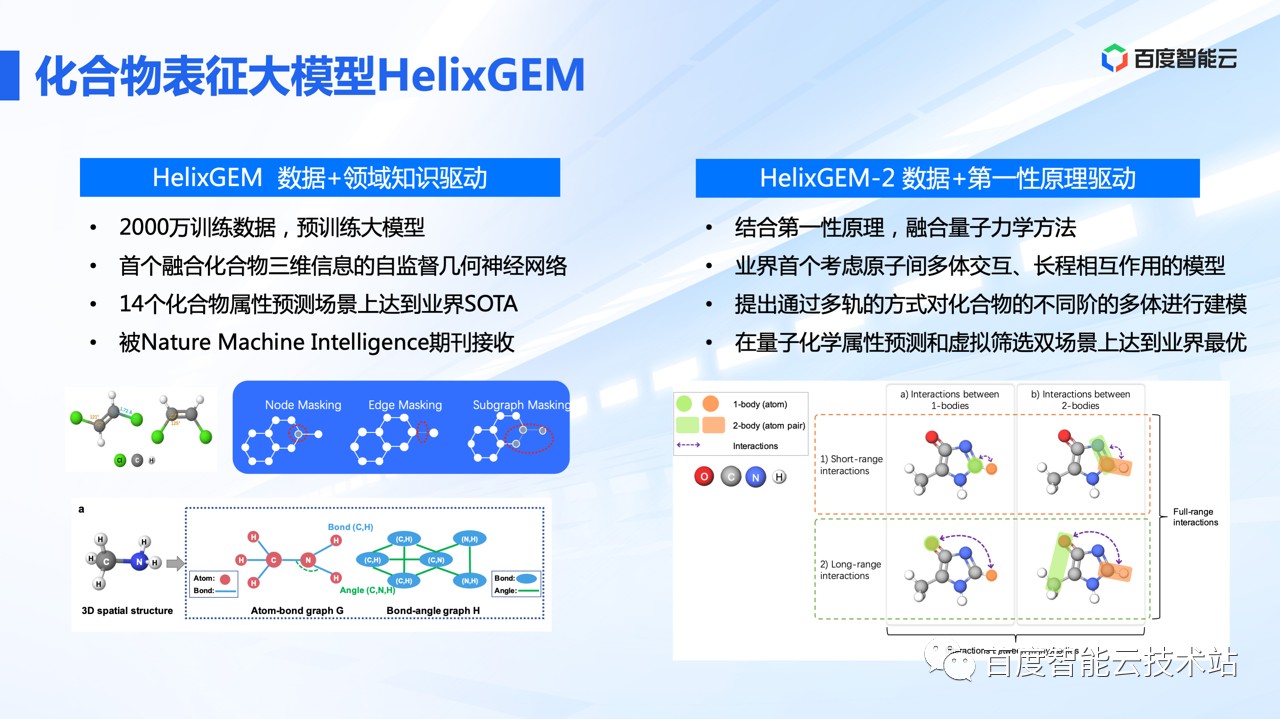
HelixGEM-1 的核心创新点在于: 设计了基于化合物几何空间结构的图神经网络、建模原子-化学键、化学键-键角之间的关系。
同时设计了三种基于几何空间结构的自监督学习任务,可以自动推断化合物的构象信息。在化合物属性预测的相关任务上,像 Tox21 毒性数据,QM 量子化学属性预测数据上,可以达到业界最佳。
基于 HelixGEM-1,通过多任务学习、学习指标任务之间的相关性,百度进一步提出一种融合多种任务的知识迁移框架。通过训练任务的先后顺序来控制模型的注意力重点,形成了 HelixADMET 成药性预测的工作。
在同样的预测目标上,HelixADMET 平均领先其他方法 4% 以上。该工作发表在 22 年 5 月份的 Bioinformatics 杂志上,同时也入选了中国信通院 2022 大模型优秀应用案例的名单。

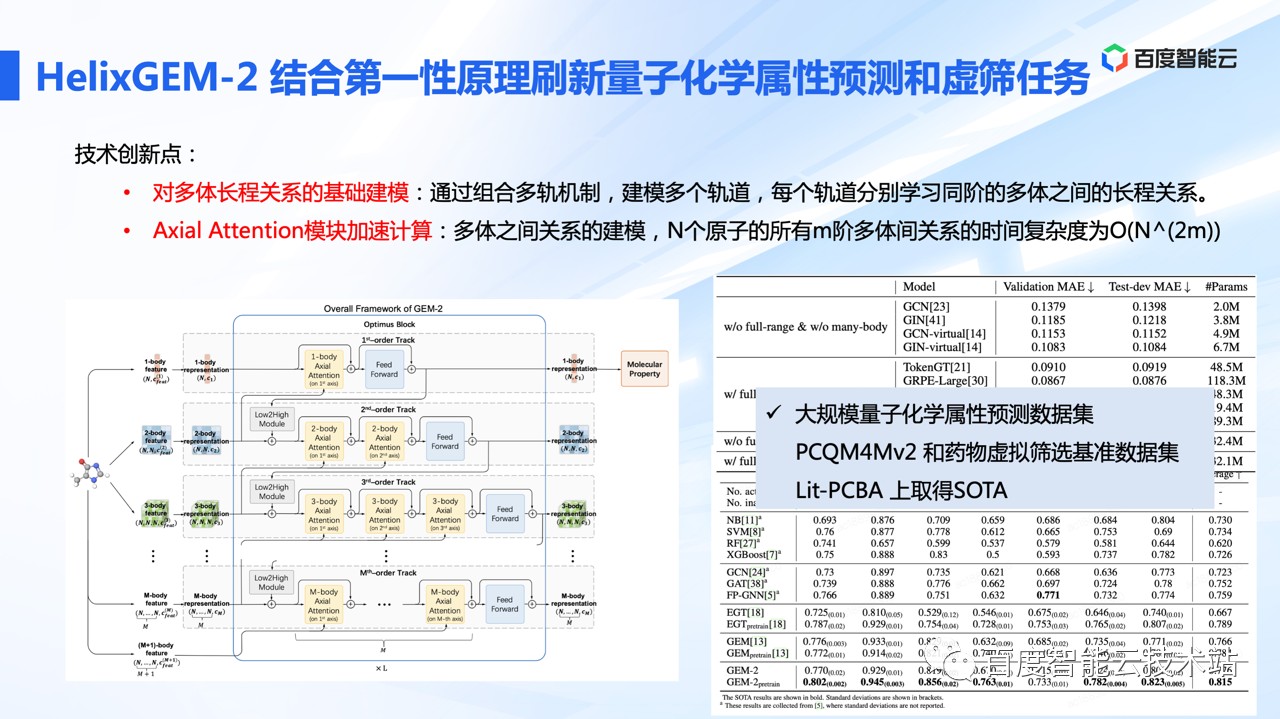
另一项工作是 HelixGEM-2,我们都知道化合物的性质很大程度上取决于化合物分子内部的相互作用、以及与环境中其他分子的相互作用。
从量子力学的角度来看,化合物及其环境是一个多粒子的体系,预测化合物性质的难点在于如何准确描述粒子间复杂的多体(Many-body)和长程(Long-range)相互作用。
为了更好描述这些相互作用,以预测化合物的性质,我们从量子力学仿真方法得到启发,开发了 HelixGEM-2。这是业内首个考虑化合物分子多体和长程关系的模型。
百度在量子化学属性预测数据集 PCQM 4mv2 和来源于真实实验数据的 Lit-PCBA两个数据集上都达到了业界 SOTA。
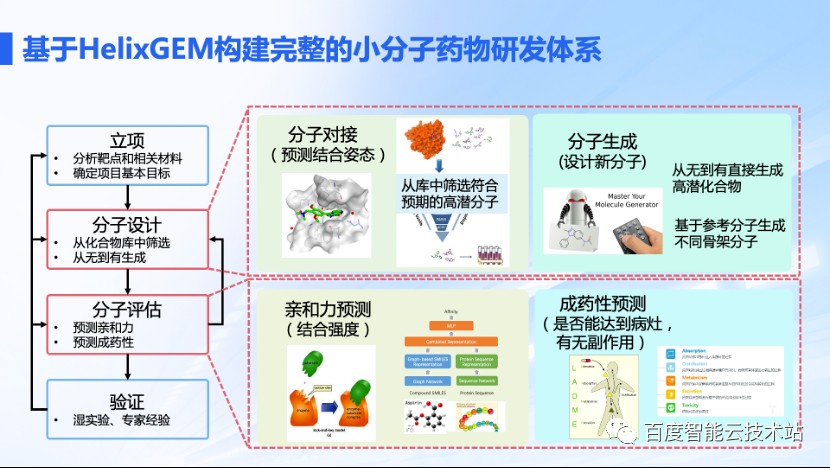
基于化合物表征大模型技术,螺旋桨已经构建成完整的小分子药物研发体系,实现了从立项到分子设计、筛选到药物靶点亲和力评估和成药性评估,再到专家判断和湿实验验证的完整闭环。
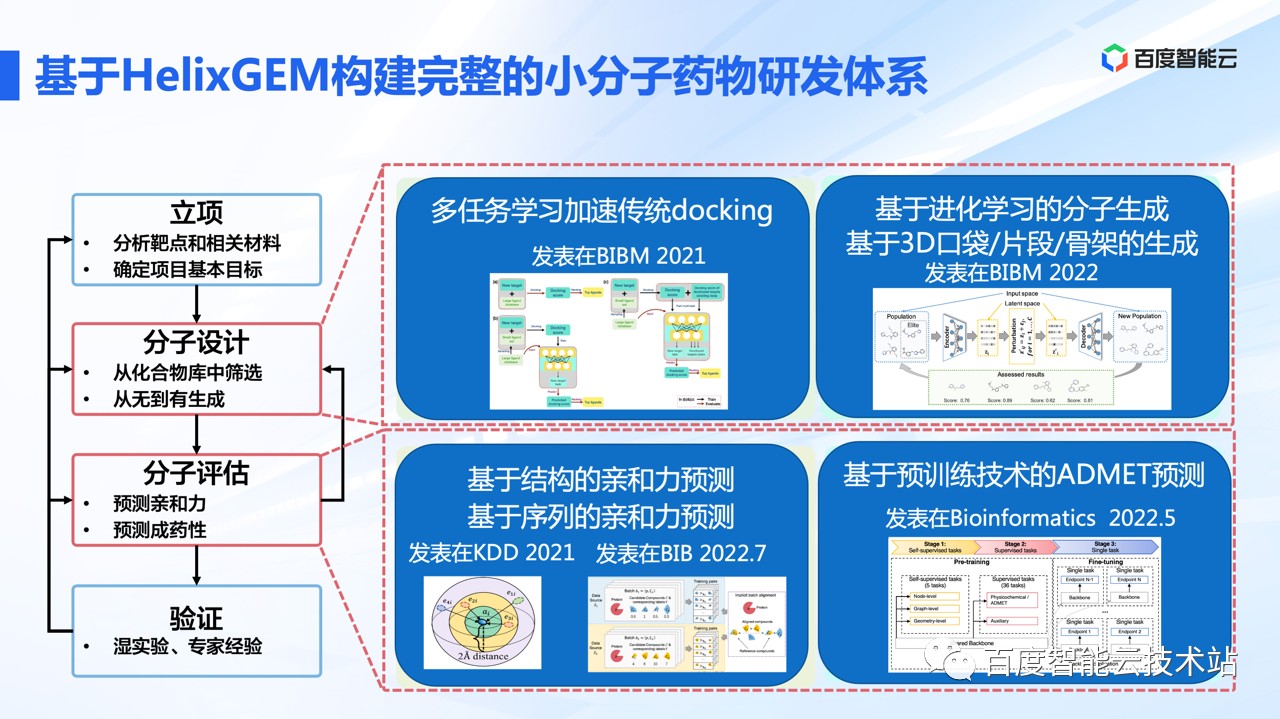
我们针对具体场景做了很多创新工作,像是基于多任务学习去加速分子对接的技术、基于进化学习的分子生成技术、基于共晶结构的药物靶点亲和力预测模型,以及基于预训练技术的 ADMET 预测技术等。
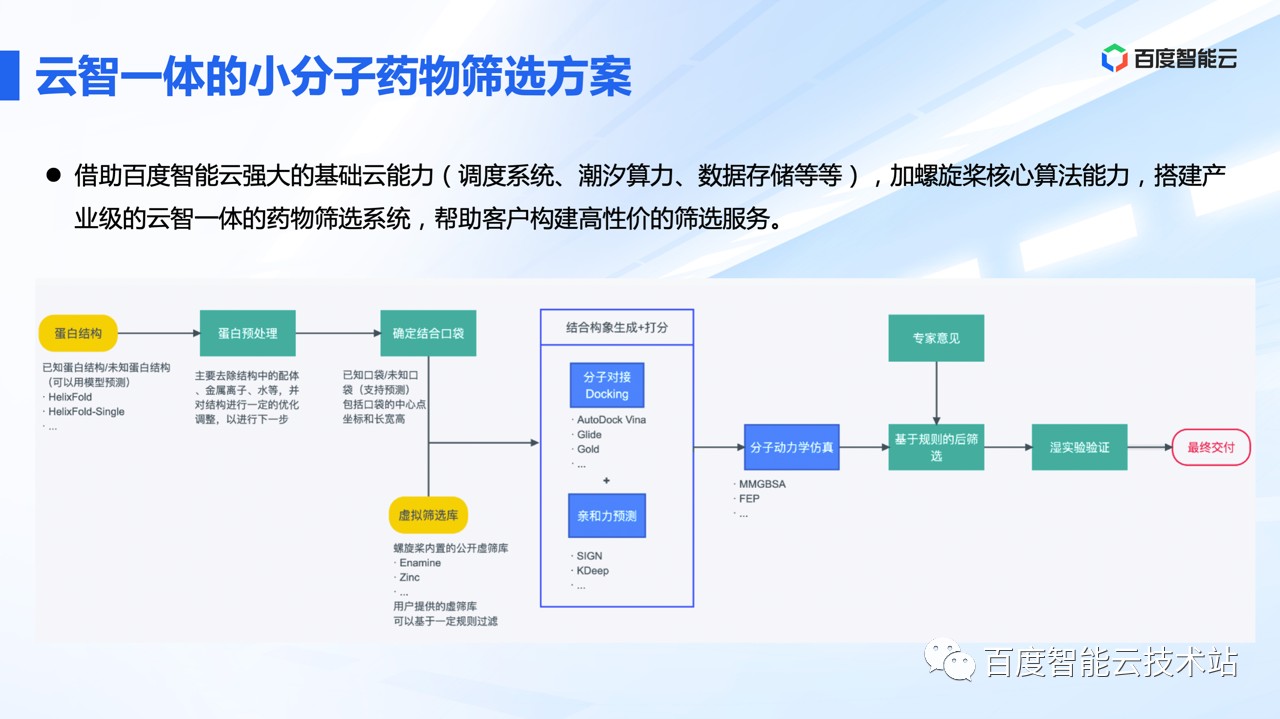
借助以上的技术能力,基于百度智能云的强大调度系统和并行计算能力,我们搭建了云智一体的小分子药物筛选系统。云智一体的小分子药物筛选系统可以帮助用户,以较高的性价比、较快的速度,获得苗头化合物。
基于公开数据集,我们还整理了一个百度自有的筛选库,2000 万已经计算属性的、可用于筛选的分子库。
接下来,我将系统介绍一下,螺旋桨在蛋白领域的工作。
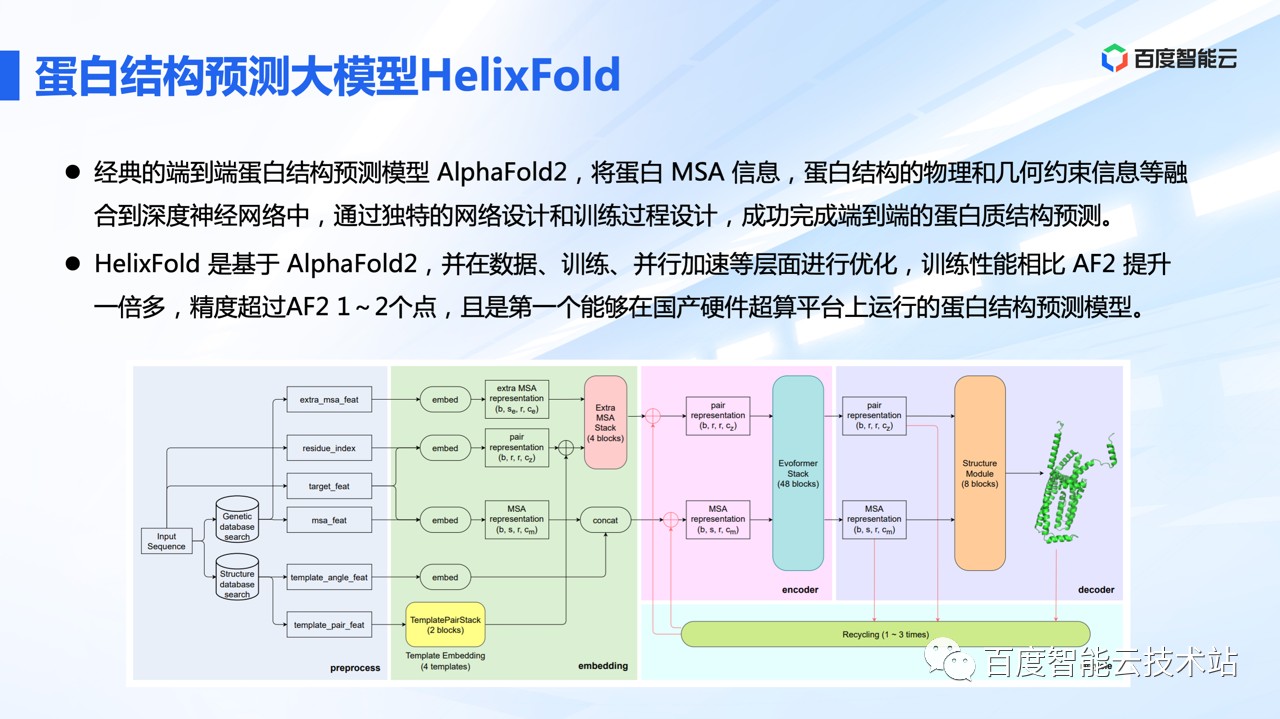
蛋白领域近期最受关注的工作,就是 Deep Mind 的 AF2。百度从头训练了 AF2 的模型,并在数据、训练和并行加速等层面进行了系统优化。我们使用了更多蛋白数据做训练,以及增加一些训练技巧,最后蛋白结构预测模型 HelixFold 在精度上超越 AF2 1-2 个点;在性能上,GPU 环境相比 AF2 提升 1 倍多;在国产 DCU 环境上,千卡集群 Initial Training 一轮只需要 2.6 天,这也帮助国内的超算平台,在国产硬件集群上,提供媲美 AF2 的蛋白结构预测的服务。
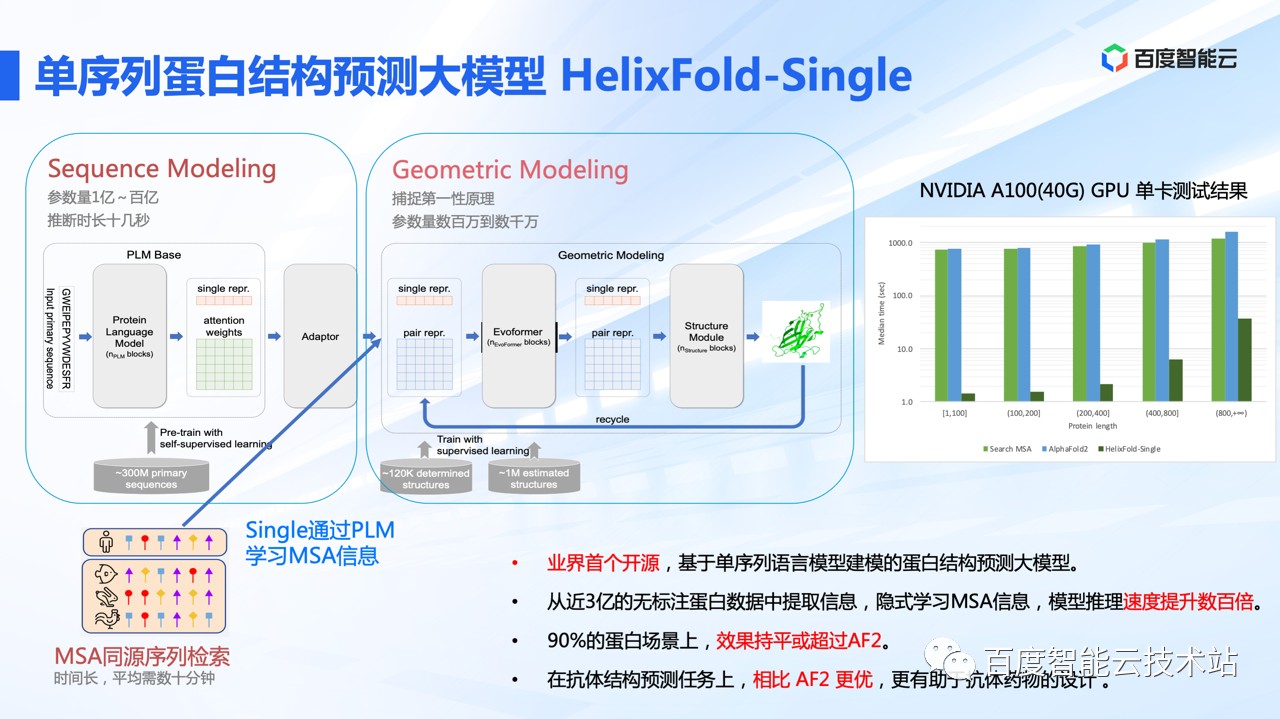
但我们都知道,AF2 的推理速度,尤其是遇到超长蛋白,会非常慢。主要的耗时在 MSA 的检索上面,这已经成为了蛋白结构预测模型在工业界广泛应用落地的一个瓶颈。
基于此,百度联合百图生科提出构建基于语言模型的单序列的蛋白结构预测模型 Helixfold-Single。从近 3 亿的无标注蛋白质数据中提取信息,隐式学习 MSA 信息,使得模型推理速度相比 AF2 提升数百倍。
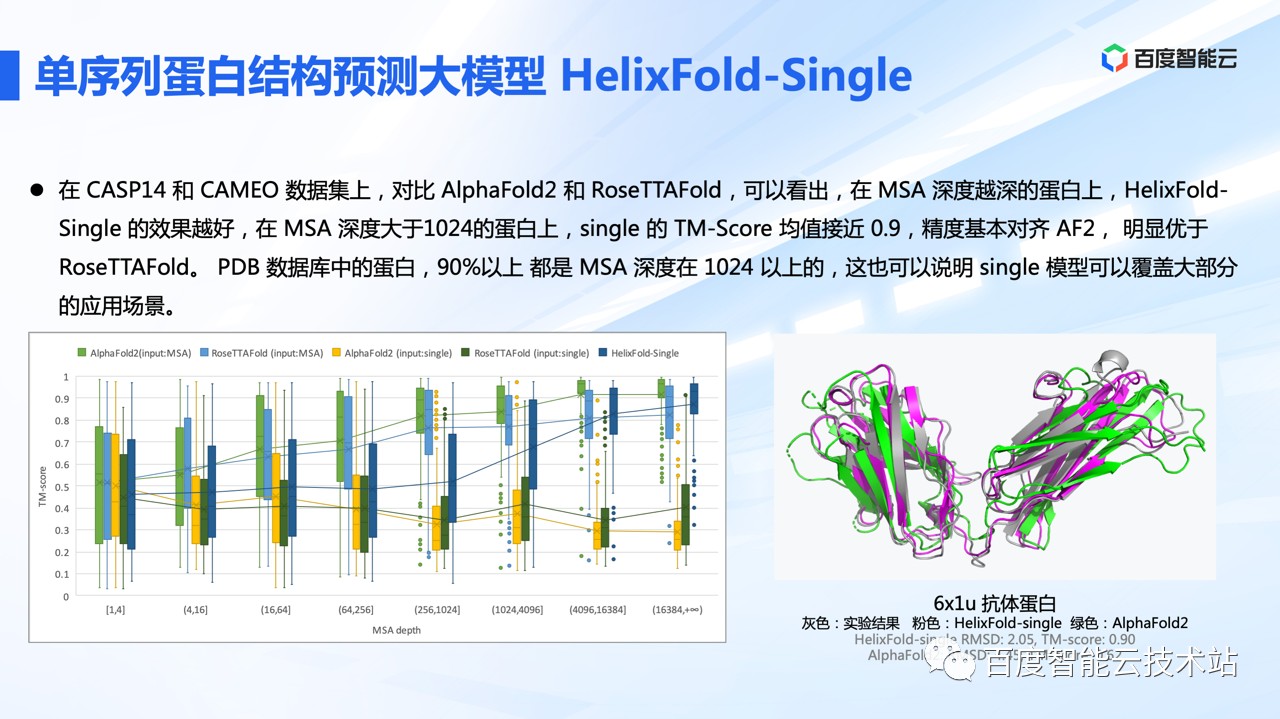
在效率极大提升的同时,预测精度上 HelixFold-Single 也媲美 AF2,在抗体蛋白结构预测上,Single 相比 AlphaFold2 的表现更优,这也更有助于如抗体药物的设计。
蛋白领域另一个工作是 PPI 方面的。我们都知道,蛋白-蛋白相互作用问题是大分子药物研发中的关键问题,PPI 和蛋白结构、功能都密切相关。
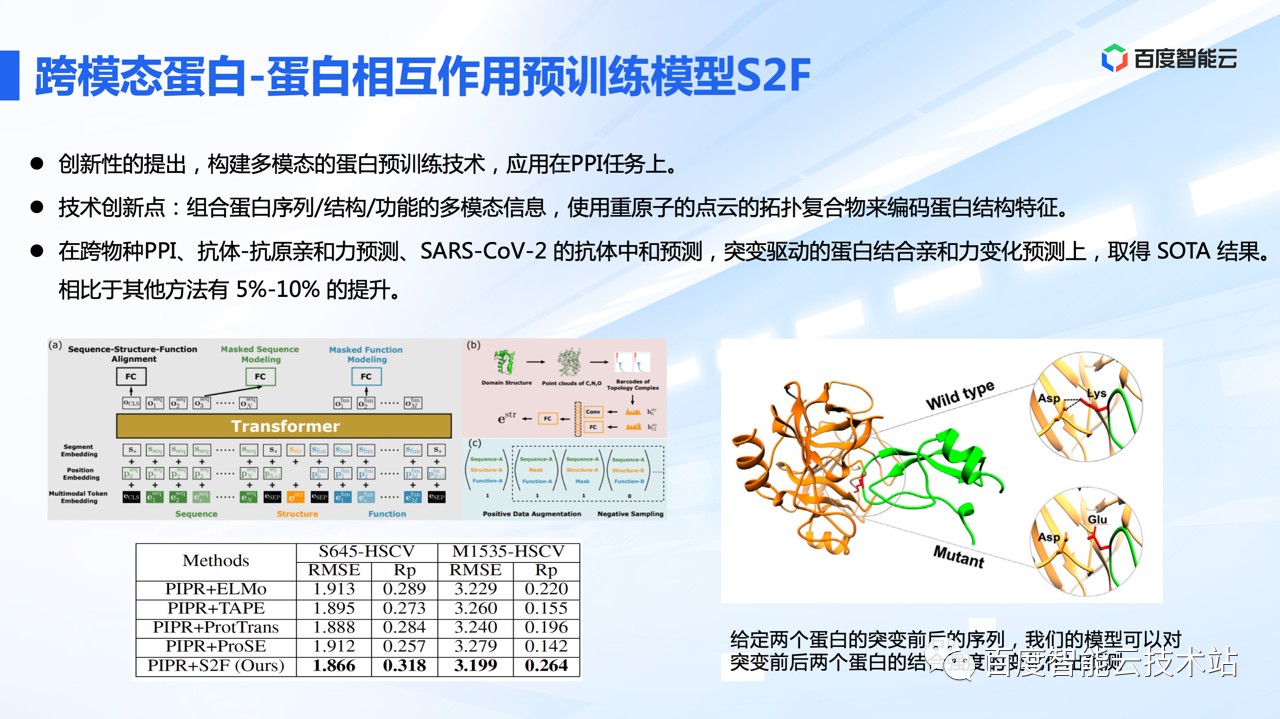
借鉴 CV 和 NLP 领域的多模态学习技术,我们创新性地提出「构建序列、结构和功能的蛋白质多模态预训练技术」,并将其应用在 PPI 任务上。
这里的核心创新点在于,组合蛋白序列/结构/功能的多模态信息,使用重原子的点云的拓扑复合物来编码蛋白结构特征。这样不仅可以学习骨架的结构信息,还可以学习侧链的结构信息。
在跨物种 PPI、抗原抗体亲和力预测、新冠抗体中和预测、以及突变驱动的蛋白结合亲和力预测上,都取得了 SOTA 结果,相比其他方法有 5–10 个百分点的提升。
基于蛋白领域的积累,目前飞桨螺旋桨已经构建起跨平台的蛋白结构分析方案,支持国产 DCU、GPU 和 CPU 等硬件生态,提供对标 AF2 且精度更高的版本 HelixFold,同时也提供性能更快的 HelixFold-Single 版本,供用户选择。
在此基础上,百度还在研发更快的复合体结构预测模型,希望能为产业界带来更快更准更全面的国产系的蛋白结构预测大模型工具集。

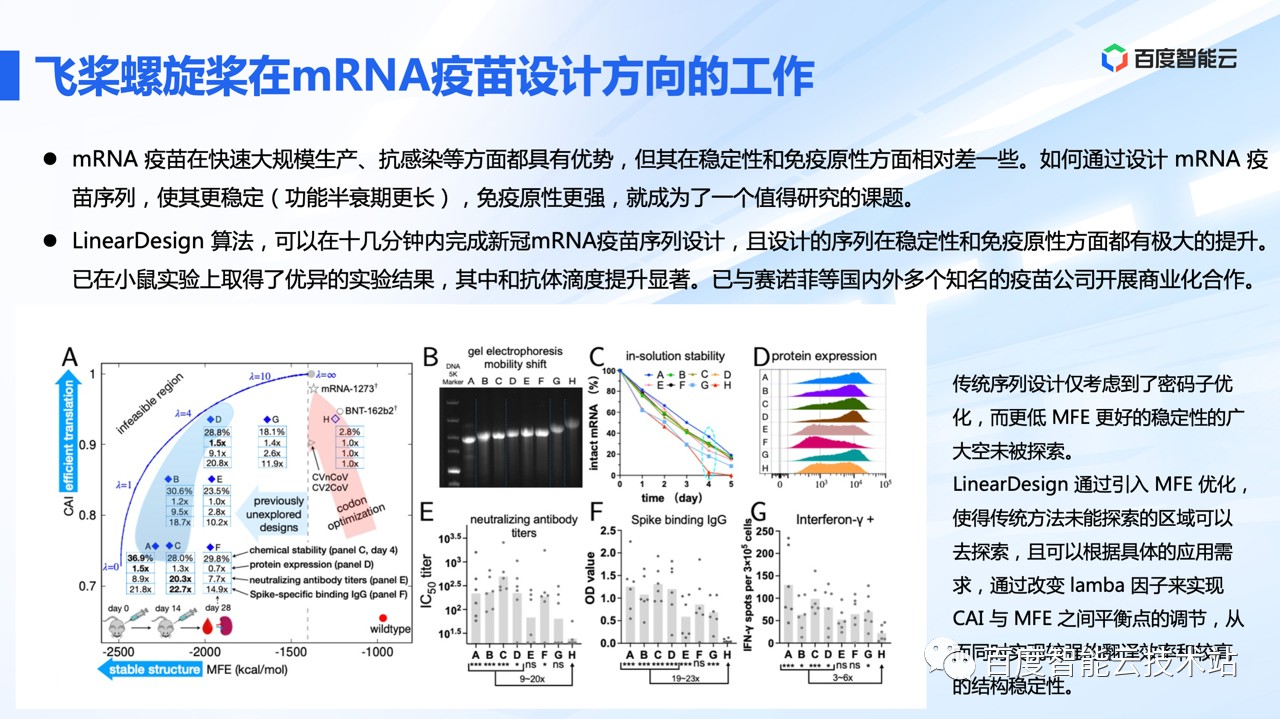
在 mRNA 序列设计方面,螺旋桨早在新冠疫情初期,就研发了 LinearDesign 算法,帮助科研人员设计稳定性更好、蛋白表达和免疫原性更优的 mRNA 序列。
我们在小鼠身上完成了新冠 mRNA 疫苗的湿实验验证,其抗体中和滴度提升显著。相比传统序列设计方法,通过引入 MFE 和 CAI 的动态优化,探索到更广泛的搜索区域。
通过改变 Lamba 因子来实现 CAI 与 MFE 之间平衡点的调节,从而同时实现较强的翻译效率和较高的结构稳定性。LinearDesign 算法已经通过商业化授权的方式,在国际制药巨头法国赛诺菲的实际管线中落地。
3. 飞桨螺旋桨的产业实践
最后举几个我们应用大模型技术,在实际的药物研发管线中的案例。
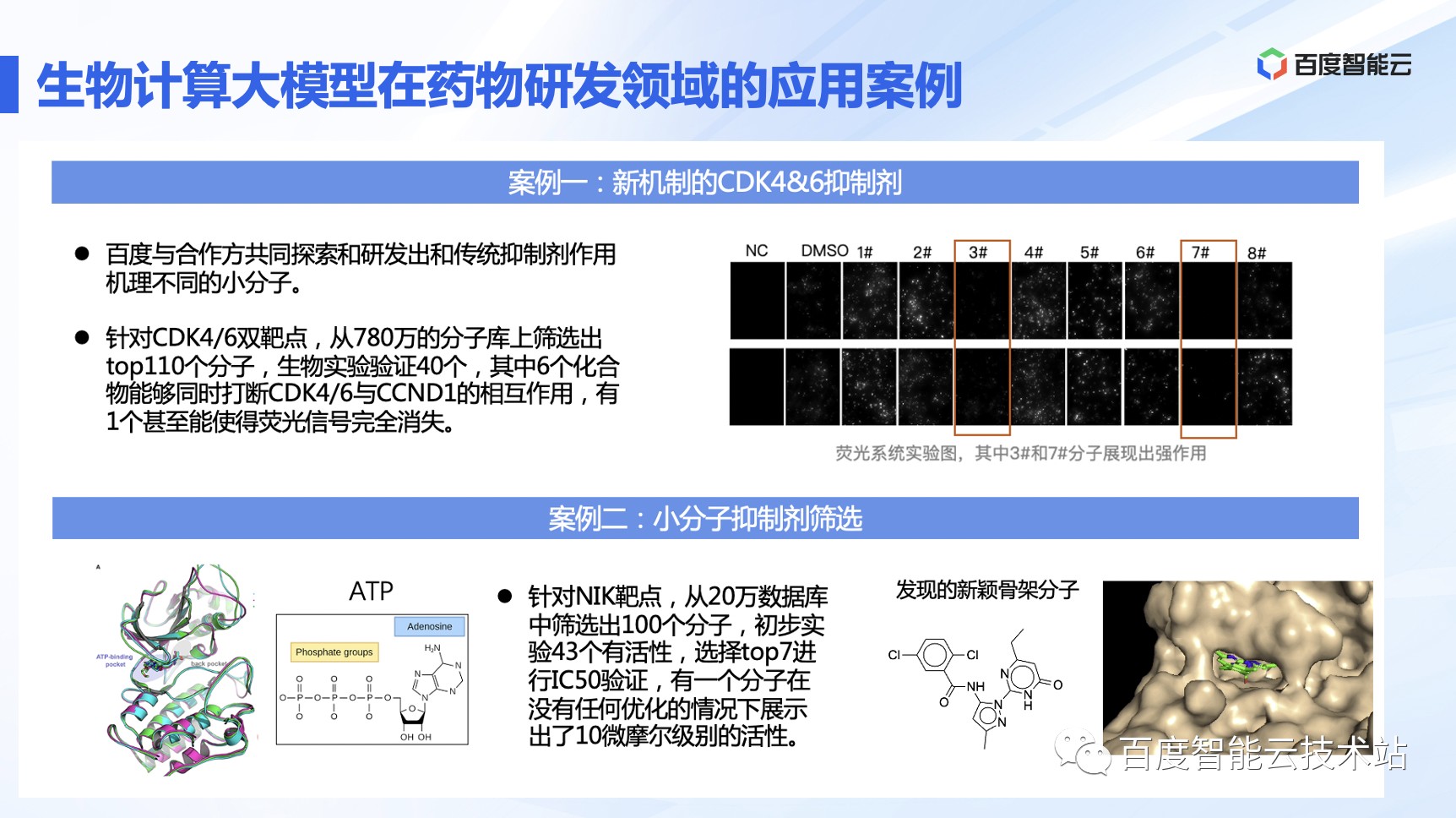
第一个案例是一个新机制的 PPI 打断问题,目标是找到 First-in-Class 的双靶点抑制剂。CDK4/6 是和乳腺癌密切相关的靶点,目前已有药物都有比较强的抗药性的问题,我们希望从机制出发,找到能够打断 CDK4/6 和 Cyclin D1 结合的小分子。最终,我们从 780 万的虚拟分子库中,筛选出 110 个分子,采买了 40 个进行活性实验验证,其中有 6 个分子能够同步打断 CDK4/6 和 CyclinD1 的相互作用,有 1 个化合物分子甚至能使荧光信号完全消失。
第二个案例是一个常规的小分子抑制剂的筛选,目标是发现新颖骨架。我们从很小的 20 万库中,做了 7 个分子的 IC50 实验,最后找到了 1 个骨架新颖的苗头分子。
在蛋白方面,我们联合国家超算成都中心帮助中国农业科学院都市农业研究所和四川农业大学农学院的 2 个课题组,利用蛋白结构预测模型,进行植物底层机制分析和小麦蛋白调控机制研究,以培育高质高产的小麦材料。
同时,利用蛋白结构预测模型和蛋白功能分析模型,帮助一家知名三甲医院在一个 4000+ 长度的蛋白上,进行疾病机理的研究分析。

目前,螺旋桨 PaddleHelix 已经构建起全栈一体的生物计算方案,在算法、算力层面,提供完整的底层到上层端到端的能力,部分模型已经通过开源平台对外赋能。
在数据层面,百度希望和更多的合作伙伴共建数据生态,更好的服务生物医药产业。
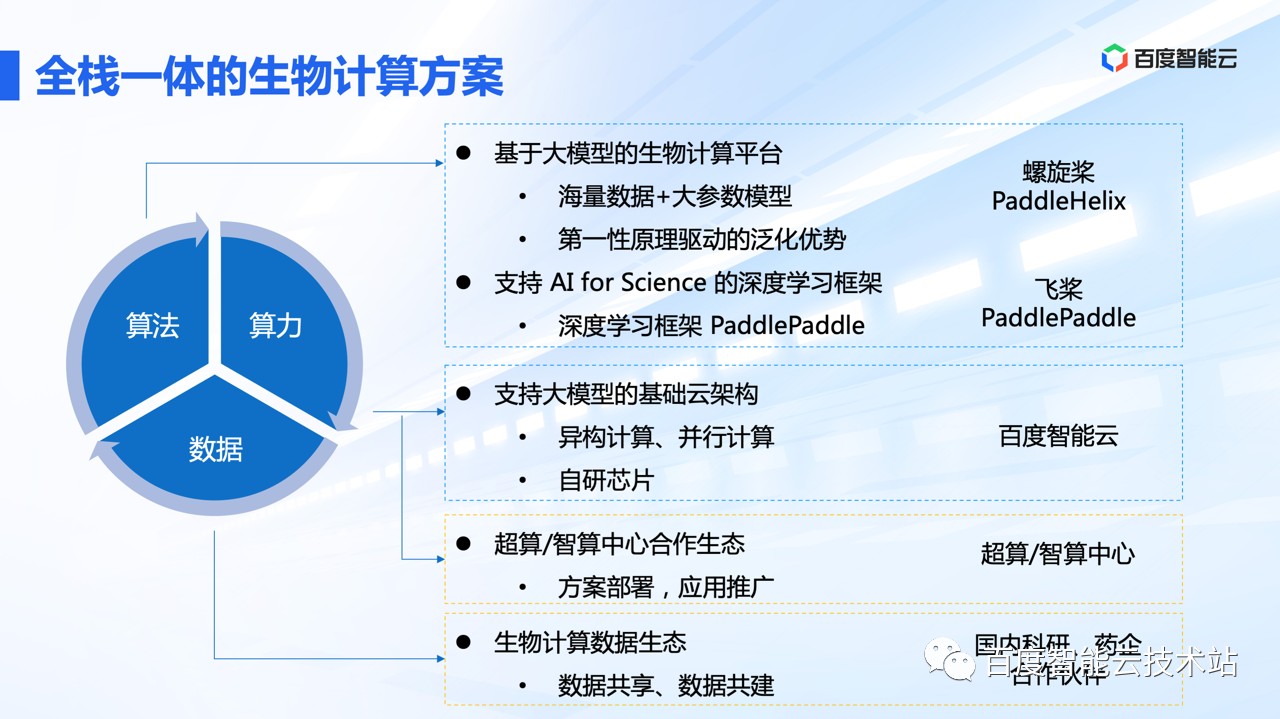
在技术能力之上,我们也构建了基于生物计算大模型的完整的产品方案,从底层算法 、到中台、到云智一体产品,到生态建设,通过开源平台和计算平台,对外提供服务,感兴趣的小伙伴们,也可以直接访问 https://paddlehelix.baidu.com/。

以上就是我今天带来的分享,感谢各位的聆听!

发表评论
登录后可评论,请前往 登录 或 注册