智能感知编码优化与落地实践
2023.04.25 15:29浏览量:951简介:基于人眼视觉特性出发的感知编码优化技术,成为互联网短视频、OTT 等 UGC 场景的重点优化手段。
今天主要有 4 个方面的内容。首先给大家介绍一下感知编码的技术背景;第二块是核心技术;第三块是给大家介绍一些应用的落地实践;最后给大家简单介绍一下编码的整个趋势。
1. 智能感知编码技术背景
现在是一个大视频的时代,视频的流量也在持续增长,4G 通信催生了短视频行业的爆发。直到今天,还是没有停止的状态。5G 通信技术已经被广泛应用,它的高带宽、低延迟带来了更超高清的视频体验。
自始至终,用户的视频体验跟成本节省之间是一对矛盾。视频流量持续增长就会带来更高的带宽费用,我们如何在体验不降低的情况下节省带宽成本达到双赢状态,是我们作为技术人持续努力的目标。
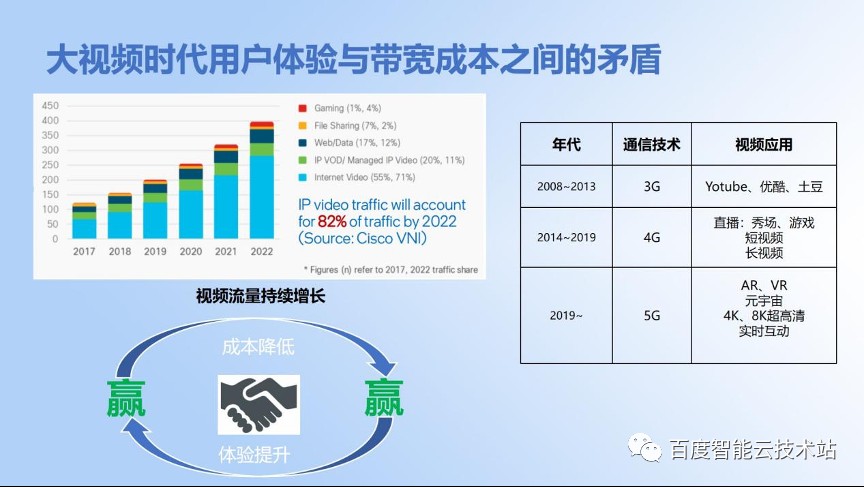
我们怎么去压缩带宽呢?
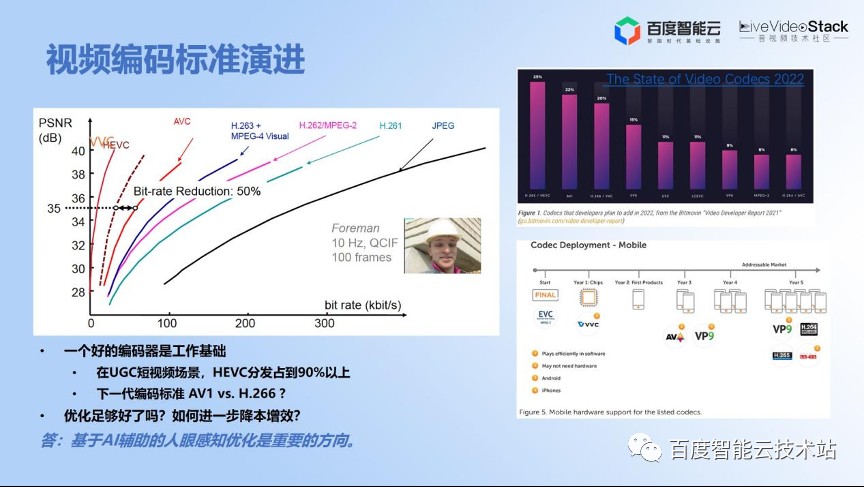
首先要有一个好的编码器,编码的标准也是经过了几十年的演进,已经有很多代的 CODEC,每一代的新的 CODEC 都是在上一代的基础上做很多的编码优化,研发出有竞争力的自研的编码器。
因为编码标准只是规定了视频的码流信息,我们可以加入更多新的工具、新的算法,去在同等质量下达到更优的压缩效率,这个也是做算法同学们持续工作的目标。
目前的情况是 HEVC 或者 H.265 已经在互联网 UGC 场景上占到了分发的 90% 以上。很多厂家也都在看下一代到底是 AV1,还是 H.266,行业内也有很多讨论。那么我们在基于编解码标准的优化之外,还有没有更多优化手段呢?这答案是肯定的。
基于 AI 辅助的人眼感知编码是一个很重要的优化方向。它可以给我们带来更多的带宽节省,业界也提出了窄带高清、高清低码等等。百度智能云「智感超清」技术中的「感知编码器」,本质上都是用了感知编码的优化技术。今天我们就对这个技术,结合实践,再进行一些新的解读。
我们先看一下整个感知优化的基本原理。
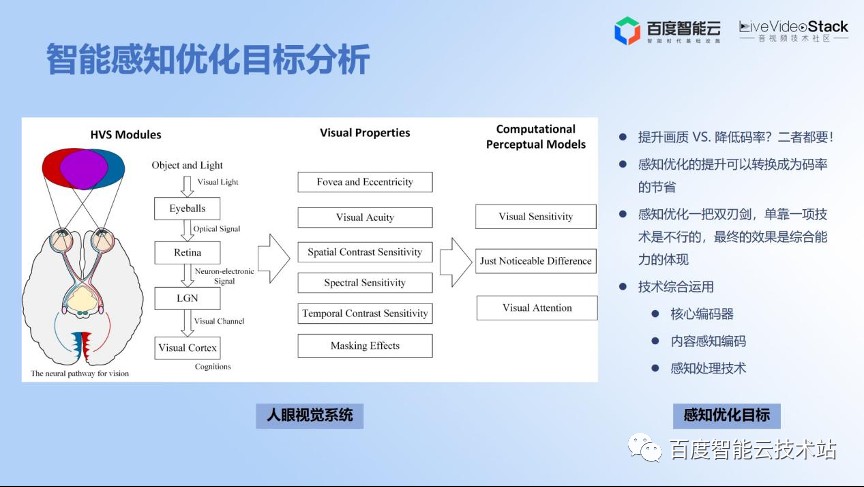
视频压缩算法最根本的目标还是要达成人眼更好的感知质量。从人眼视觉系统来看,传统的一些压缩算法,比如在 PGC 场景使用的压缩算法,他们一般利用 PSNR 作为质量评价指标,主要是考察压缩后的视频和原视频相比,在像素级别是不是足够像,足够接近。我们可以利用更接近人眼的一些新的视频质量评价指标,比如 SSIM 或者最新的 VMAF,甚至是更好的基于人工智能的无参考视频质量评估方法。
更好的视频质量评估算法也是我们持续追求的目标。我们从人眼特性出发可以归结几个视觉的模型,比如视觉敏感度,人眼到底是对纹理更更敏感,还是对平坦区域的质量更敏感。另外,人眼有 JND 的特性,就是恰可察觉失帧的特性,可能人眼到了一定程度才会失帧更敏感。同时,我们有视觉注意力机制,即人眼对局部更感兴趣,那么就可以利用这些人眼的特征去做更多的优化。
总结下来,感知编码优化包括以下内容:
首先,对内容进行感知,对图像画质进行增强处理;
然后,在画质增强的基础上,进行码率分配的优化,比如基于 ROI 区域的识别,进行码率更优的分配;
最后,结合核心编码器的优化,通过这些技术的综合运用,最终达到进一步节省码率的目标。
在目标上,我们不仅仅要压缩带宽,同时要提升用户体验。用户体验的提升反过来也可以转化成码率的节省。
感知优化是一个双刃键,更具体来讲就是通过前处理去转化成码率节省的时候,用好了就是码率节省,用不好可能会带来负向的问题,所以我们也一直在强调这是一个综合技术能力的提升。
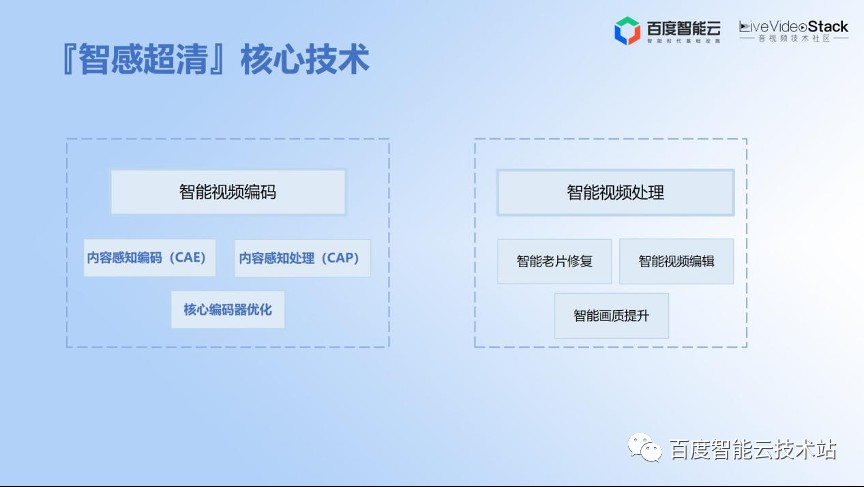
接下来,我们就看一下具体怎么去做。近年来,百度智能云的智能视频云团队一直在持续的建设的「智感超清」的技术品牌,感知编码器或者感知优化技术是整个「智感超清」技术品牌中非常重要的一部分。
刚才提到了这几部分内容,包括内容感知编码、感知处理,还包括核心编码器的优化。今天的内容也主要是围绕下面的几个核心技术来展开。
基于「智感超清」的技术,百度智能云的视频云团队为 ToB 客户打造了一系列的解决方案。
我们将算法转化成实际的产品,包括公有云、私有化、一体机的形式,通过一些硬件平台的加速,能够从视频的生产到播放,端到端地让算法为客户的业务赋能。
下图是我们整个产品方案的一个基础架构。
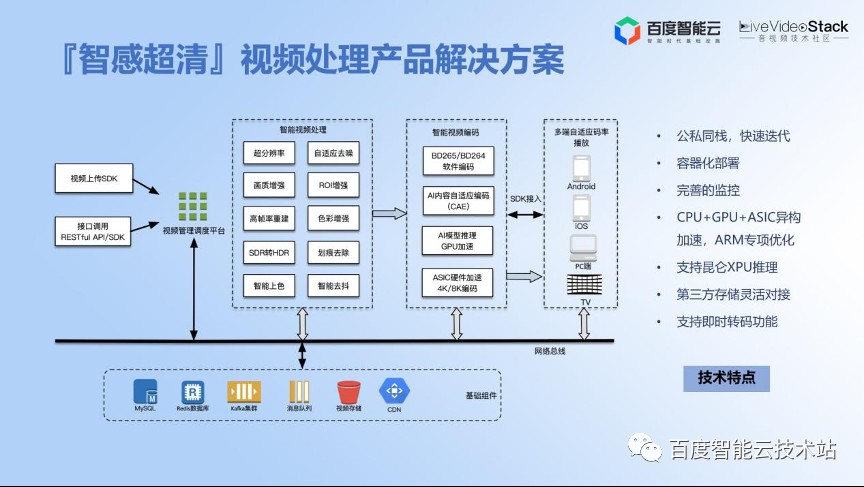
下图就是我们整个的产品形态。
作为云产品的输出,我们无法像 C 端业务一样,可以用技术去深度耦合地赋能业务。我们需要对技术做更多层次的产品抽象,把技术转化成标准化的产品,以产品的形式让更多的 B 端用户能够去用。
除了刚才提到的公有云、私有化、一体机之外,我们也支持感知编码的 SDK 输出。

2. 智能感知编码核心技术
介绍完一些基本的产品能力,我们就看一下整个智能感知编码的核心技术。
一开始我们就提到了编码器,一款好的编码器是一个工作的基础。
近两三年,我们持续投入 BD265 的核心编码器的研发。那么,在编码标准上如何去构建一个具有竞争力的编码器呢?
我们可以从这两方面去做:
- 一方面是正向技术驱动,比如在编码标准的基础上,通过一些正向的编码工具或者算法,提升编码器的压缩能力,比如更好的码率控制方式、码率分配是一个很重要的优化点,后面也会讲如何让码率分配到更合理的地方。我们陆续也加入了很多代码标准里不涵盖的算法,比如金字塔 B 帧、GPB,还有前处理相关的一些算法,这个是面向正向质量优化的。同时在工程优化方面主要是指编码效率的优化,也就是说在编码质量无损的条件下尽量提升它的编码速度,尤其是目前编码器也支持了 ARM 平台的专项优化,包括移动端和服务端,同时也支持各种各样的快速算法。这些都是一些正向驱动技术,同时研发到一定程度,我们也通过场景反馈驱动。比如我们的应用驱动在直播通信场景上做了很多专项的优化。
- 另一个方面是场景反馈驱动的优化。比如在点播场景上,面对降本增效持续的压力,我们在极致压缩场景上也做了很多优化。比如,在整个压缩算法上针对主观做了很多优化。右上角的这幅图大家可以看到,我们是整个持续迭代的过程,从 1.0 版本开始,一直持续到 5.0 版本。我们的压缩率比开源的 X265,包括 PSNR/SSIM 或 VMAF 在内的客观性指标上能够达到 40% 以上的码率节省。所以我们将编码器作为基础,可以开展更多的感知优化工作。
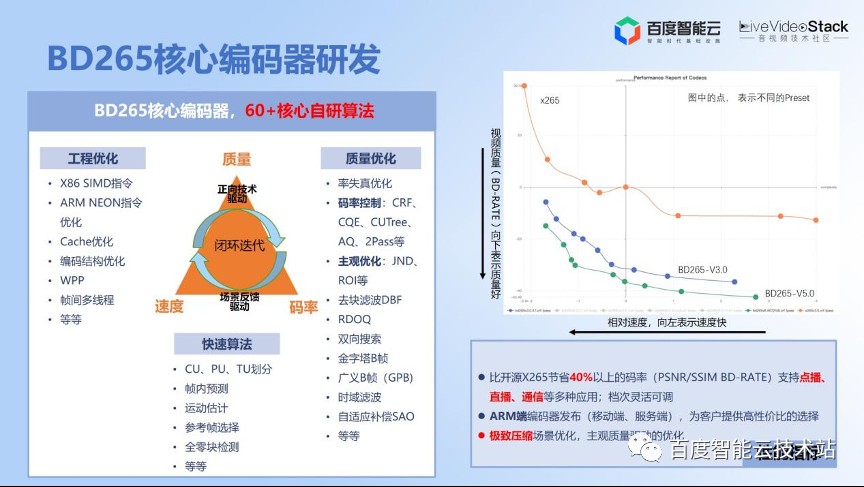
一直在讲感知,那么我们能感知的是什么呢?就是内容特性。
视频质量跟哪些特性有关系。所谓感官上“人”的主观质量,大家就认为码率高了,质量会好,分辨率高了,质量也会好,帧率高可能更播放更平滑和顺畅。然后就是跟 CODEC 相关,不同 CODEC,不同压缩率。但是还有一个很重要的,就是内容特性。因为每一个不同的内容都有自己的 RD(码率-失真)曲线,每一条曲线是跟内容特性息息相关的。
那么我们如何针对每一个视频内容,甚至说视频的每一帧给出一个更优的码率分配呢?或者说给一个最优的码率配置?
更具体来讲,我们如何在业务上给出一个视频的最优码率和分辨率组合。因为现在业务上都是有 ABR(码率自适应)的方案,到底怎么给出最优的组合,就需要对内容特性进行深度分析。
因为本质上内容自适应编码还是码率控制问题,这就需要根据内容特性,找到视频质量、视频内容与视频码率、分辨率之间的关系。那怎么去找,还是有些难度,最笨的方法就是遍历一遍,但是这样显然达不到业务的时效性要求。
人工智能为我们提供了对内容进行分析和理解的手段,并在此基础上完成快速、最优的参数编码的预测。

这个是我们 2019 年做的一个工作,也有相关的论文发表,发表在 PCS2019 的会议上。
我们构建了一个基于 AI 的模型。首先,我们在视频场景这边输入一个视频,之后对视频进行分片,每一个场景的分片通过视频参数的预测模型进行分段预测。
我们是如何评价的呢?首先是我们一直在讲的视频复杂度,视频复杂度包括时间的复杂度,也包括空间的复杂度。那就可以提取时间的一些特征和空间的一些特征,同时基于预训练的大规模的 CNN 网络,提取一些特征。然后利用 TSN 的网络把这些特征做一些融合,融合在一起之后过一个预测模型,就可以得到更优的编码参数。
我们的优势是基于线上的视频构建了百万视频场景级别的训练集,根据不同的分辨率去做更多的训练。这个模型已经在线上跑了 3 年多,效果也是非常的稳定。
我们在这个基础上做了更多的迭代,包括根据不同分辨率更精细化地进行数据标注,同时现在的算法也支持整个工程化,ToB 输出也可以用到这个模型支持,通过 FFmpeg filter 的形式进行编码参数的预测。
但是它有一个不足的地方,就是它现在是一个点播场景的应用,因为一开始设计的时候,我们就是设计在一个转码的工程里边,后面也会做一些改进。
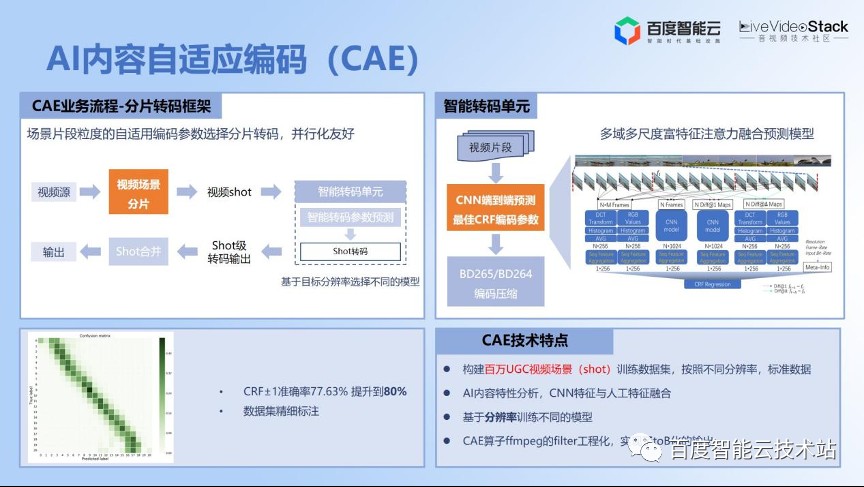
在这个需求基础上,我们后面也研发了 CQE 技术,它是恒定质量的编码来进行码率控制,同时更加轻量级的方法。
原理上可以利用编码器里边的一些已经预分析的特征,然后设计一个模型,最后给出编码的参数决策。如果在点播场景下,质量有问题的话,可以利用重编去解决。当然我们现在重点也支持直播场景的 CQE 技术,几乎是做到零延迟。
讲完了对内容特性的感知,给出一个最优的编码参数之后,我们在码率控制上还可以做更多的事情。
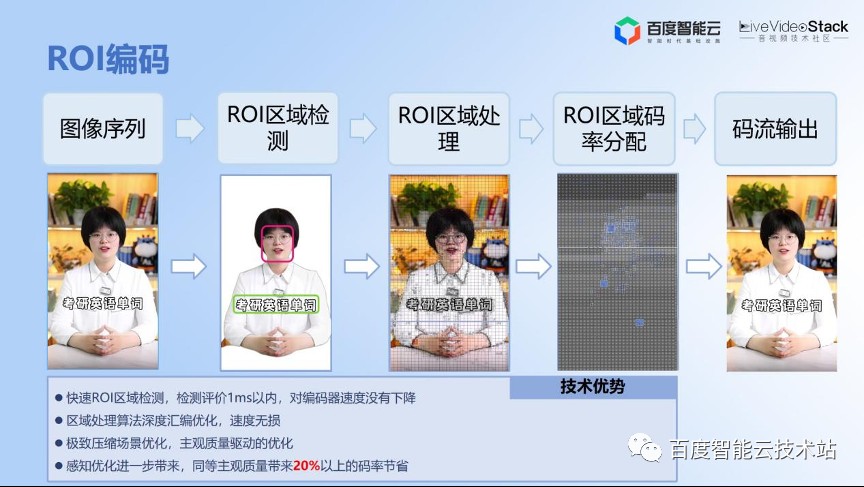
首先,大家一直在做的就是基于 ROI 的编码。所谓 ROI 就是人眼感兴趣的区域。刚才提到,人眼有注意力机制,人眼在看一幅图像或者看视频的时候有更敏感的区域。最近注意力机制非常流行,这就是大模型的基本原理,Transformer 即 Attention Is All You Need。
整个视频输入之后,人眼最感兴趣的区域,首先是人体,然后是人脸,还有一个是字幕,字幕也非常敏感。我们检测到感兴趣区域之后,就可以对这些 ROI 的区域进行预处理。处理的话可以做一些边缘增强锐化,平坦区域可以做更多的处理。
我们在 UGC 场景上提供了一个空间,因为输入的视频质量可能是参差不齐的,有质量好的,有质量差的,那么在算法上也需要有针对性地做更多处理,输入视频的质量是什么样的层级,做什么样的算法我们会有更多的处理。
刚才讲到了前处理,还有一个是码率分配。如果只做前处理也是不够的,码率分配的环节也需要做更多的考量。因为做了前处理之后,视频的内容特性发生了变化,所以这个地方的码率分配策略,需要特定算法去做更优的调整。
当然我们也有更快速的检测方式,可以达到 1 ms 的检测速度,这也非常重要。
那么我们就看一下效果,可以看到,左边的视频是 1080P 的原视频,8.9 Mbps 的码率。右边的是 720P,经过 ROI 处理和编码的视频,码率是 514 Kbps 。
通过这 2 个视频的对比,可以看到通过百度智能云的 ROI 感知优化技术,它的视频质量是正向提升的,同时它的码率压缩了 18 倍之多。这个就体现了整个 ROI 感知编码的优势。

我们再看一下 ROI 的编码和区域视频。
人脸是整个短视频产品上非常重要和常见的感兴趣的区域,因为人就是天天看人脸,你在路上会遇到形形色色的人,我们看短视频主要也是经常看人脸。因为人眼经过长期的训练,对人脸的质量非常敏感。人脸区域上稍微有点噪声或者稍微有点马赛克等等,很快就会被看出来。
所以说在做前处理的时候,不能比较笼统的去做,还是要根据人脸的区域特性做不一样的处理。同时人眼对肤色特别敏感,到底是偏红、偏绿还是偏黄非常敏感。而且人眼对不同人种也非常敏感。
所以在策略上肯定要更多地呈现细节。在极致压缩的场景上,要尽量控制伪影和块效应,这个是我们在主观优化上要持续解决的问题。那么我们在这里也用了很多算法去做专项处理。从跟竞品的比较效果可以看到,我们的 BD 感知编码器在人脸区域上有更多的细节呈现,不像友商有糊的感觉。

这个是跟竞品比较的效果,右边可以看到更多的细节。

讲了人眼体验之后,我们再看一下色彩。
色彩增强也是主观优化很重要的一个方面。比较重量级的话可以用 AI 的方式去做,比较轻量级的话可以用一些传统方式去做。
我们可以看到在色彩方面,左边是 606Kbps 码率没有经过色彩增强的压缩视频,右边是 485Kbps 码率的经过色彩增强的压缩视频。可以看到在通过一些色彩的处理算法之后,码率可以达到 20% 的节省,但是主观效果有明显的提升。
但是这样也会有问题,就是色彩增强也是一把双刃剑,如果用不好,就会容易犯错误。这个也是我们针对人脸专项优化的一些经验。

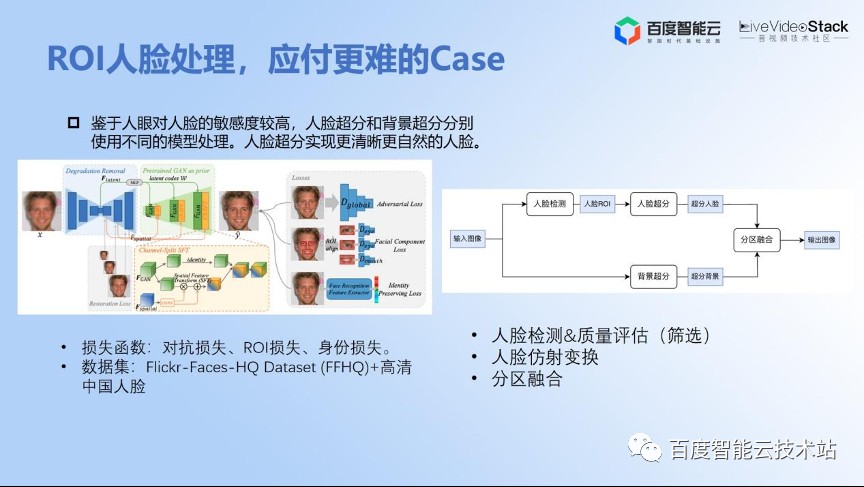
我们刚才讲到短视频场景的人脸处理,其实还有很多更难的 case,这些在整个广播电视场景上或者其他一些 OTT 场景上也是很常见的。那么如何去应付这些更难的 case 呢?
我们可以把人脸专门抠出来,让人脸化作专用的人脸超分模型,把它分区域进行处理。
我们采用基于生成对抗神经网络(GAN)的模型,主要优化还是在工程化的落地方面和数据处理方面、在损失函数的设计方面做了专项的人脸超分的工程化,损失函数就包括一些对抗的损失,ROI 的损失还有身份的损失。让超分之后的人脸跟原始的人脸看起来像同一个人。
同时,我们在数据上做了大量的优化工作。做完之后我们通过人脸分区融合的算法让人脸的超分效果和视频超分效果能够很好地融合在一起。
我们可以看一下效果。
这些是线上的一些实际客户的 case。可以看到在通过人脸专项的优化模型之后,画面的清晰度得到了极大程度的恢复,这也是基于生成模型的思路去做了更多的恢复,在人眼的视觉质量上很自然,同时又更清晰。这个是做专项人脸优化要达到的一个目标。

这个是教育场景的一个 case,经过处理后可以看到,这个老师的清晰度,还有后边的字幕都有比较明显的提升。

其实还有很多场景上,除了人脸还有一些其他的感兴趣的区域,比如图像里边没有人脸,可能左边有一只狗,狗也是一个很重要的感兴趣区域。所以显著性可以理解成感兴趣区域的扩展。
其实这里的基本思路类似,也做了一些有特色的优化。同时我们在做显著性检测时,不仅仅把区域扩展到非人体,也包括一些前景对象。重点对人脸区域进行了保护,也就是说既有人脸,也有非人脸、非人体。我们根据显著性的优先级进行了侧重处理和码率分配的优化,这样达到最终的目标。
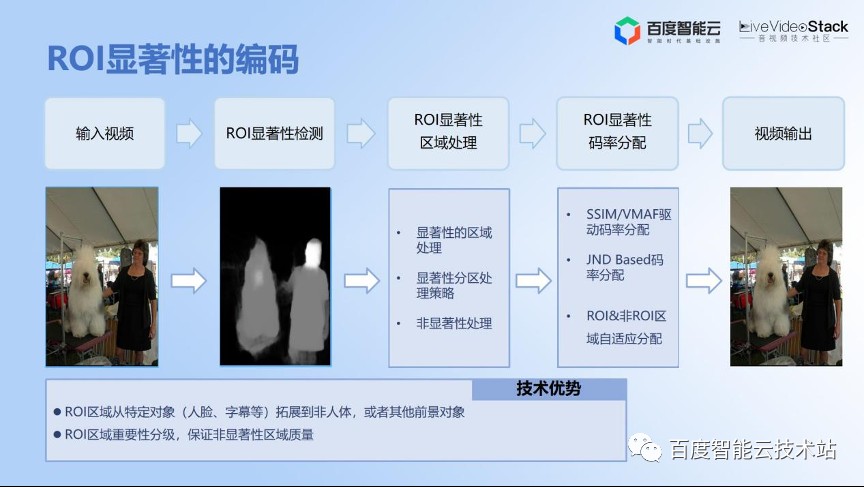
显著性检测的技术也是基于更经典的 U 型网络即 U2-NET,在这个基础上做了很大量的工程优化的工作包括模型的裁剪,整个新增了人脸的分支和其他效率上的优化。
我们目前在 CPU 上可以达到很快的检测的速度,差不多能够替代一个单独的人脸检测模型,这个也是我们优化的一个目标。

这个视频它的背景有山有河流。因为山上有很多树,这种属于很耗码率,但是人眼可能不怎么敏感的地方。同时人眼会重点关注小女孩的衣服和小女孩的脸部是不是够清晰。
左上角是一个非显著性的压缩视频,右上角是显著性的压缩视频,左下角是 20M 的原视频,右下角是显著性区域的展示。所以通过显著性的优化可以在感知质量上达到更好的效果。

我们刚才把感知优化的核心技术点给大家过了一遍。
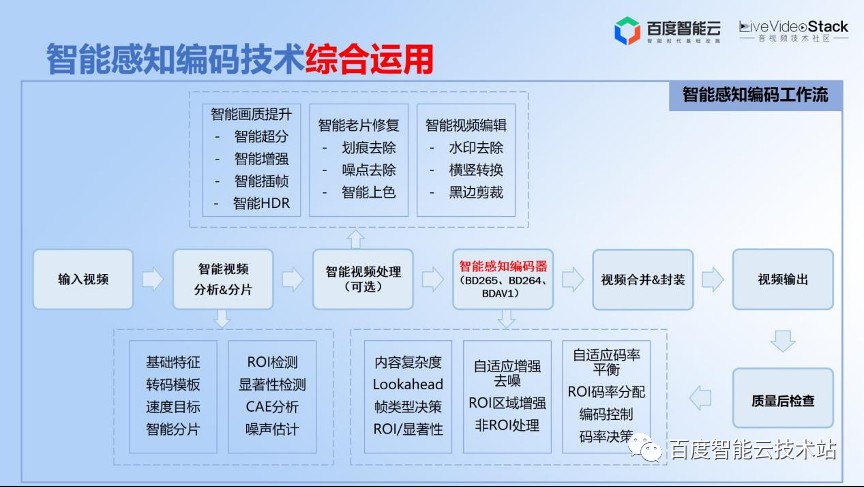
一开始提到,其实整个感知优化技术手段并不是拿过来放到编码器里边去,它就能很好的工作,这个是不现实的。我们需要做的事情就是要把所有的工具、方法跟最基础的 BD265 编码器进行深度融合,包括前置分析、检测。
然后在码率分配上与 CAE 技术结合。通过增强控制影响后面的分配,我们也做了码率平衡的策略,保证做了前处理之后的码率能够在控制在范围之内,还有包括 ROI 整个码率分配的优化。同时,可以把人工智能的 AI 重量级优化技术,包括人脸超分技术,作为一个可选项。
根据对原视频质量的评估,可以有选择地利用基于 AI 的处理,包括增强 HDR 等等。这样的话,总结起来就叫感知编码技术的综合运用,只有这样感知编码技术才能够达到线上可用的目标。
3. 技术落地实践
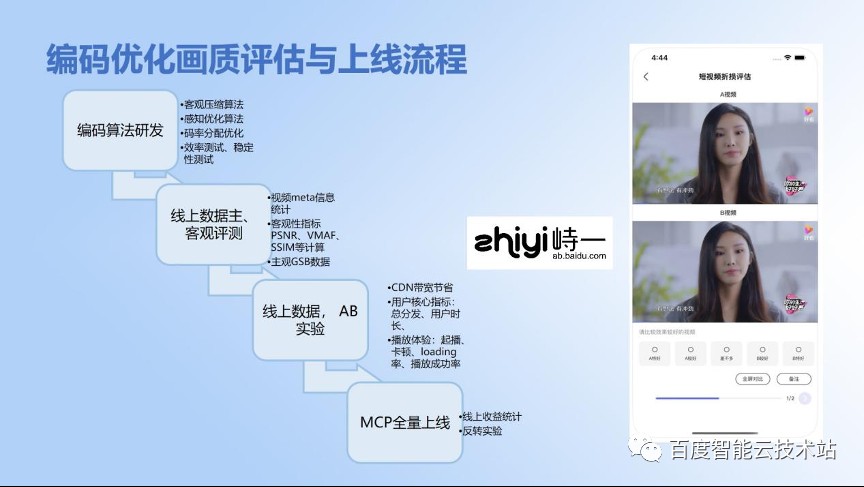
在百度公司内部,百度 FEED 流视频也是一个很大的体量,所以可以先分享一下整个,包括画质、评测,还有上线的基本流程。
首先是核心算法的研发,包括客观性的压缩算法、感知优化算法的研发,以及主观优化的一些算法的评价指标。在主观评价自测过关之后,进行编码器的效率测试、稳定性测试。
在工程上的话,首先要跑一批视频,让 PM 同学或者运营同学去做主观 GSB 的数据评价。GSB(Good、Same、Bad)就是拥有主观评价的平台,比如说 G 就是 A 比 B 好,S 就是 B 和 A 一样好,或者 B 就是 bad,就是 A 比 B 差。这样的话就会形成一些打分,有了这些打分之后就决定 GSB 是不是过关,能不能达到上线的标准和要求。
我们还要做线上的实验。通过百度公司的 AB 实验平台做大量的实验。刚才讲到的主观评价,百度内部有一套名叫「灵镜」,支持多终端的主观评价平台,可以基于人眼的评价进行打分。那么,到了 AB 实验环节的话,就会有更多数据驱动的数据,包括能不能带来实际的带宽节省。那么在用户指标(UBS)上,包括分发、时长、用户播放的体验和起播、卡顿、loading 率等等,都需要经过很严格的指标性考核才能达到最终能不能达成上限的目标,就是说这上面的几关都要过。
最后是一个全量的过程,要经过发展实验再验证一下这个结果是不是符合预期,即整个带宽是不是符合预期,其他指标有没有恶化。这个是整个的上线流程。
有了这项流程之后,我们从去年到今年持续地给线上产生一些收益。
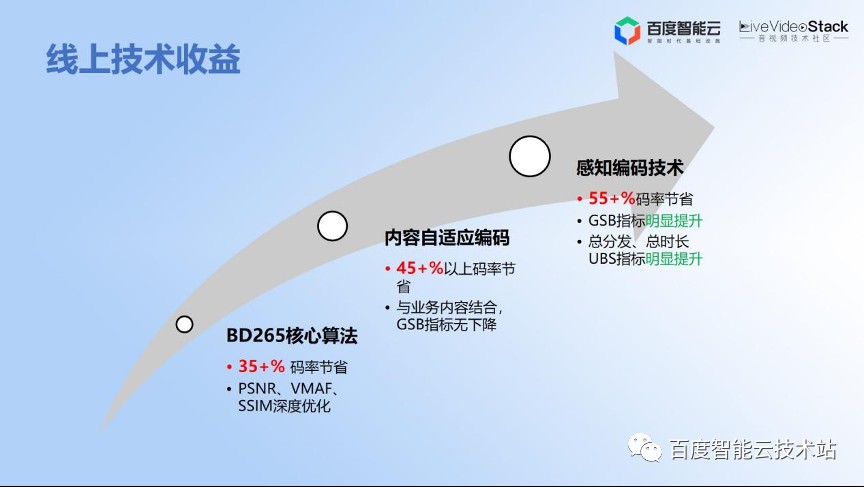
首先,我们通过核心编码器的算法优化,在客观性指标可以达到 35% 到 40% 的码率节省。
然后我们通过内容自适应的编码又能达到 40%-50% 的节省。通过与感知编码技术的深度融合,最终的感知编码器能够带来 50% 到 60% 的码率节省。通过感知编码优化技术,用户指标数据(UBS)有明显提升,总分发、总时长和最终的业务指标是有明显的正向提升。
这个就是回馈到一开始给大家讲的如何在不降低用户体验,甚至提升用户体验的同时,又进一步节省带宽。也就是说,我们通过感知编码技术的优化达成了最终想要的目标。
4. 智能编解码技术趋势
最后还有一点时间,我给大家简单介绍一下智能编解码的技术趋势。
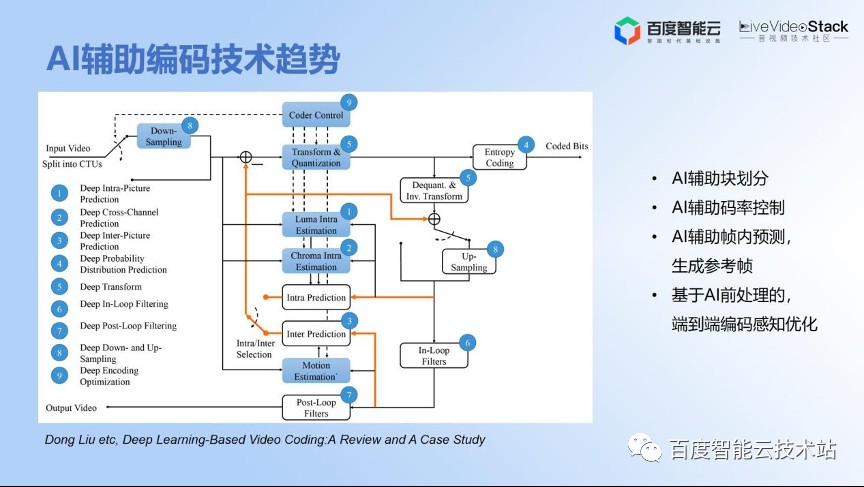
后面的材料主要是还是引用一些论文趋势。首先是基于深度学习的编码方向的一个 Review 的文章
我为什么要参考这个呢?因为它在经典的编解码框架基础之上为各个模块都引入了 AI 工具的讨论 。那这些模块能不能用 AI 进行辅助的编码赋能呢?其实在下一代编码过程中,比如说 AV1 或者 H.266 会越来越多地用到 AI 辅助模块化的辅助编码工具去进行加速或更优的判决。当然,一开始的 CAE 技术也是用了 AI 的辅助码率控制,还包括其他方面,如通过端到端进行 AI 的前置处理,就是从开环走向闭环,这是我们下一步要去做的工作。
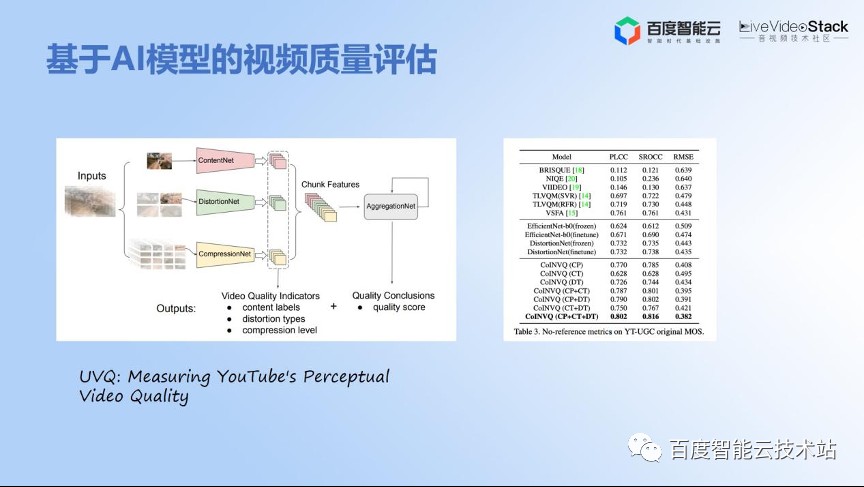
下一个分享是视频质量评价,这也是非常重要的一个课题。
为什么叫课题呢?因为这个 topic 是大家持续都在做,但是没有最好,只有更好。大家最近都在做 YouTube 分享工作,是基于 AI 的利用多个特性,包括内容、distortion(压缩的损失),还包括压缩本身用多个网络进行特征融合的方式来回归,这样的话可以达到更好的人眼用户体验,这号称也是达到 SOTA 的结果。
为什么讲这个的话呢?因为我们整个感知编码都是围绕质量。那什么是感知质量?如何更优地评估?这个也是客观性指标,解决不了的问题。所以我们就需要通过建立与业务相结合的质量评估模型去推动技术进一步发展,甚至包括 CAE 的技术,还包括主观处理的策略,都可以用这种更优的主观质量模型去辅助,达到更优的效果。
最后我简单分享几点非常浅薄的思考,还是跟感知编码相关,感知编码会越来越多地使用 AI 手段。
这边是几点总结:
- AI 是基础,它需要紧密结合应用的需求,构建综合的研发能力。意思是说仅仅有单点的能力是不够的,需要把综合能力都串起来,进行综合运用。
- AI 是一个工具,它需要紧密结合客户的需求。解决行业的痛点问题是指它是一个工具,到底要解决什么样的问题,就需要用什么样的工具。
- AI 辅助编码将会在下一代编码中产生更多的收益,因为下一代编码的工具越来越复杂,可以通过 AI 做更多的加速。
- AI 视频处理的方向需要持续打磨,分场景、分步骤解决问题、解决效果和效率问题。这个也是我们多年来在 ToB 场景上,尤其是 AI 的处理场景落地过程中进行的一些总结。AI 现在并不完美,但是我们还是在个别场景上,通过细分场景去持续地打磨,为解决客户的实际问题,达到生产效果和效率的要求。
- AI 在视频生产处理和编码过程中的应用仍然有广阔的发展空间。这句话是有点泛,但是大家都知道,现在尤其是大模型,像 ChatGPT、文心一言等这些都将在视频生产处理过程中产生一些促进的作用。

以上是我的分享。

发表评论
登录后可评论,请前往 登录 或 注册