容量成本性能全都要有, Redis 容量版 PegaDB 设计与实践
作者:青年2024.02.28 15:07浏览量:586简介:Redis 作为“扛流量”和“加速”的利器,在百度集团内部有着极其广泛的应用。
1. PegaDB概述
百度智能云 Redis 容量版又叫 PegaDB,它是一个完全兼容 Redis 协议、大容量、低成本、高性能的分布式 KV 数据库。PegaDB 具备以下特点:
- 全面兼容 Redis,支持业务平滑迁移;
- 支持水平扩展,单集群 PB 级存储;
- 基于 SSD 构建,单 GB 成本相比 Redis 降低 80%+;
- 支持毫秒级在线数据处理;
- 支持异地多活架构,提供多地域容灾能力;
- 支持可调一致性、冷热分离、JSON 数据模型等企业级特性;
PegaDB 典型应用场景包括:大数据量场景,Redis 存储成本高;开源 KV 数据库,在性能、功能和可用性方面无法完全满足需求;典型冷热分离场景,传统 Cache + DB 架构,业务开发复杂度高。
目前 PegaDB 已广泛应用于百度凤巢、Feed、手百、地图、度秘等多个核心业务。
2. PegaDB 设计与实践
2.1 背景
首先介绍一下研发 PegaDB 的背景。最早设计 PegaDB 主要是为了解决百度集团在使用 Redis 过程中遇到的成本和容量问题。
Redis 是内存存储,开启持久化时需要额外预留内存,存储成本较高;同时,Redis 单个集群的容量是有限的,公有云产品最大支持 4TB,无法支撑大数据量存储;不仅如此,百度集团还有其它 KV 数据库,在兼容性、通用性、易用性也存在一定的问题。
明确了业务痛点,PegaDB 的定位也就清晰了。大容量、低成本、兼容 Redis、通用 KV 存储, 同时还要具备高性能、高可用、可扩展等分布式存储系统必备的特性。
2.2 业界方案
兼容 Redis 协议的 KV 数据库,大致有如下三类方案:
第一类方案以 Pika、Kvrocks 为代表,采用基于磁盘的设计,数据全部存储在磁盘,在单机 KV 存储引擎 RocksDB 之上实现 Redis 的数据类型。但这类方案目前都没有成熟的集群方案去解决扩展性问题, 同时还存在性能、不支持多活架构等问题。
第二类方案以 Meitu Titan、Tedis 为代表的,也是采用基于磁盘的设计,数据全部存储在磁盘,但是在分布式 KV 存储引擎 TiKV 之上实现 Redis 的数据类型。但这类方案通常对 Redis 兼容性不太好,同时也存在性能、不支持多活架构等问题。
第三类方案以 Redis On Flash 为代表,数据存储在内存和磁盘,在内存中存储热点数据,在磁盘中存储冷数据,可以调整内存和磁盘的配比。这类方案基于 Redis 二次开发, 再组合单机 KV 存储引擎 RocksDB 去扩展存储容量,但这类方案比较适合数据冷热区分明显的场景, 存在通用性问题, 同时也存在大 Value 场景性能不好等问题。
2.3 设计选型
PegaDB 在选型时面临的主要问题有:是二次开发还是从 0 开始?如果二次开发, 基于哪个开源项目进行开发(Pika、Kvrocks、Ardb ……)?
出于研发人力、项目上线时间等因素考虑, 百度智能云选择了基于开源项目进行二次开发。考虑到代码简洁性、方便二次开发、设计思路及发展规划契合度等因素,最终选择了基于 Kvrocks 进行二次开发,并深度参与开源社区建设。
2.4 Kvrocks 介绍
Kvrocks 是美图公司开发的一款分布式 KV 数据库,并于 2019 年正式开源。使用 RocksDB 作为底层存储引擎并兼容 Redis 协议,旨在解决 Redis 内存成本高以及容量有限的问题。
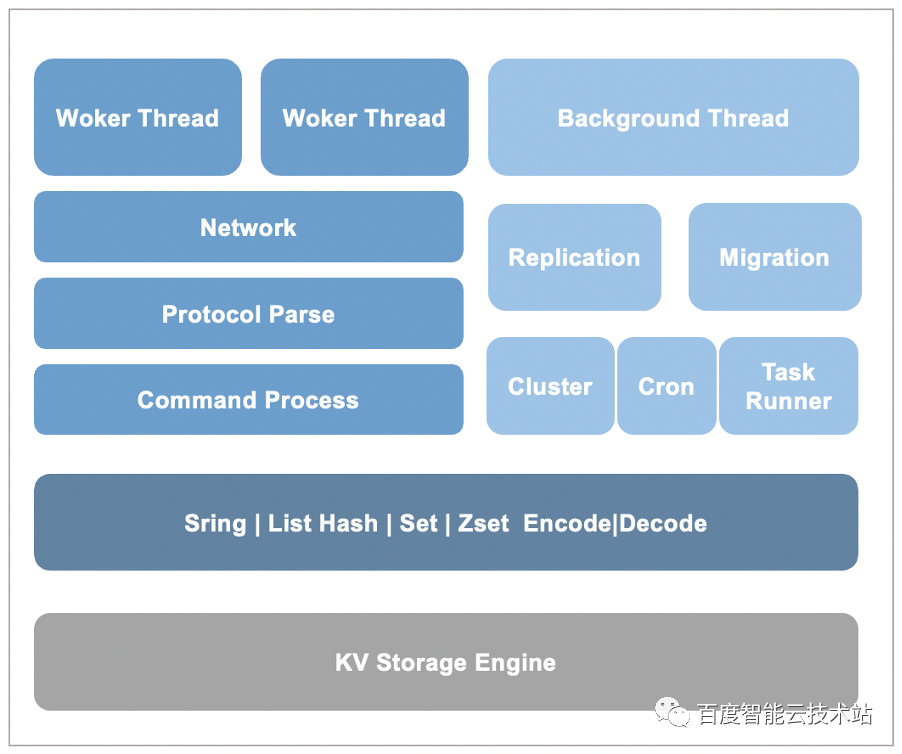
接下来分享一下 Kvrocks 的基本设计思路。
Kvrocks 是基于 RocksDB 存储引擎来封装 Redis 的数据类型,Hash 等复杂数据类型会被拆分为多条 KV 数据。
同时为了提升性能,Kvrocks 采用了多 Worker 线程的处理模型。
多副本间数据复制,Kvrocks 同 Redis 一样采用了主从复制的方式,不过增量复制是基于引擎 WAL 的“物理复制”。
此外,Kvrocks 还借助 RocksDB Compaction Filter 特性实现了数据过期,并通过增加 Version 信息实现了大 Key 秒删。
2.5 Kvrocks 不足
针对百度的业务场景,Kvrocks 存在一定的不足。
扩展性方面,Kvrocks 不支持水平扩展,无法支撑业务几十 TB 甚至百 TB 级规模数据存储;
性能方面,Kvrocks 在大 Value、冷热区分明显等场景下存在性能问题, 无法满足业务高 QPS 和毫秒级响应延迟的需求;
可用性方面,由于 Kvrocks 和 Redis 一样, 选择了异步复制模型,无法满足较高一致性需求。Kvrocks 不支持多活架构, 无法满足业务地域级容灾需求;
功能方面,Kvrocks 不支持 Redis4.0 以上版本命令、事务、Lua、多 DB 特性, 无法满足使用高版本 Redis 业务平滑迁移的需求。
为此,结合生产环境中实际遇到的问题,PegaDB 在 Kvrocks 基础上做了很多改进:
2.6 集群方案
对于扩展性需求, 首先需要支持集群。
在数据分布策略选择上,PegaDB 选择了同 Redis-Cluster 一样的思路,预分配固定数量的 Slot。在集群架构方面选择了中心化的架构,由 MetaServer 统一管理集群元信息。
同时,PegaDB 的集群架构不强依赖代理层,支持 MetaServer 向 PegaDB 下发拓扑,完全兼容 Redis-Cluster SDK。
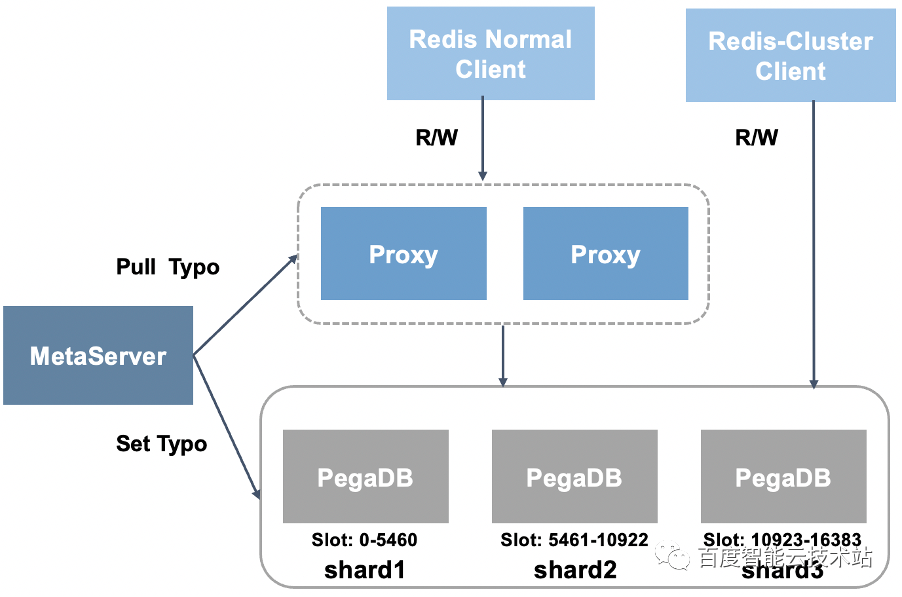
由于实际生产环境业务的数据规模和访问量是不断变化的,PegaDB 集群还需要具备弹性伸缩的能力。
2.7 扩缩容设计
对于数据库这种有状态的服务,集群的扩缩容,主要有两个问题要解决:数据迁移和拓扑变更。
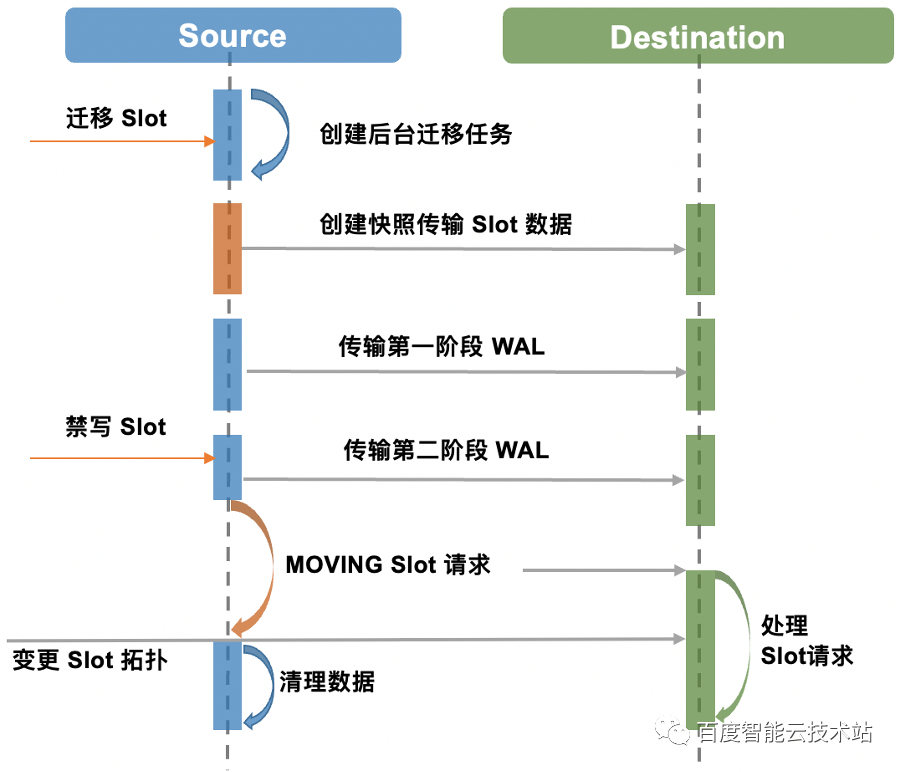
PegaDB 集群的数据分布到固定数量的 Slot,每个 PegaDB 负责一定数量的 Slot,数据迁移就是将源节点中的一部分 Slot 搬迁到目标节点。PegaDB 数据迁移采用了类似选择性复制的思路,迁移流程分为全量数据迁移、增量数据迁移两个阶段。
全量数据迁移借助 RocksDB Snapshot 快照将需要迁移的 Slot 所包含的 Key 迭代出来,同时在 Key 编码中增加了 SlotID,这样同一个 Slot 的 Key 会存储在一起,显著提升了迭代效率。PegaDB 增量数据迁移直接使用了引擎层的 WAL 日志,这种方式不需要经过 Redis 协议解析和命令处理,相比发送原生 Redis 命令的方式更加高效。
此外,为了迁移时不影响正常请求,使用了独立的迁移线程,并且通过支持 Slot 并发迁移,利用 RocksDB Delete Range 特性清理源端数据来提升效率。为了保证数据一致性,拓扑变更期间会有短时间禁写,通常是毫秒级。
2.8 主从复制优化**
介绍 PegaDB 对主从复制的优化前,先简单回顾下 Kvrocks 的主从复制实现。
Kvrocks 和 Redis 主从复制思路类似,都包括全量复制和增量复制。Kvrocks 在全量复制方面基于 RocksDB Checkpoint 数据快照,增量复制基于引擎层 WAL 的“物理复制”,并且基于 WAL seq_id 实现了断点续传。
但是 Kvrocks 复制模型有两个典型的问题:第一,无同源增量复制保证主从切换会带来数据不一致;第二,异步复制模型,主从切换可能会导致数据丢失。
PegaDB 是如何针对上述两个问题进行优化的呢?
PegaDB 引入了复制 ID 的概念,当实例成为主库时会生成新的 Replication ID(复制历史的标识),每条写入 RocksDB 的操作都包含一个单调递增的 Sequence ID 和 Replication ID,只有从库 Replication ID 与主库相同并且 Sequence ID 小于主库时才可以进行重同步。由于 Sequence ID 和 Replication ID 是存在于 WAL 中的,因此不仅支持 Failover 后部分重同步,而且支持重启后部分重同步。

针对第二个问题,PegaDB 采用了半同步复制的方案,其具有更强的一致性,支持配置同步的从库个数,并且支持超时机制。此外,PegaDB 的代理层还支持配置请求粒度读取一致性。
2.9 性能优化
为了更好的满足业务需求,PegaDB 在性能方面也做了很多优化。本次分享主要介绍 PegaDB 在存储引擎、缓存、数据编码方面所做的优化。
存储引擎方面,LSM 引擎存在明显的写放大问题,尤其在写入量比较高的大 Value 场景下,经常会触发磁盘带宽瓶颈,导致性能显著下降。
对于这个问题,业界有 WiscKey 和 PebbleDB 两种典型的方案。WiscKey 采用了 Key Value 分离的思路,PebblesDB 采用了弱化全局有序约束的思路。
由于 PebbleDB 没有成熟的开源实现,最终我们选择了 WiscKey 的思路。对于 WiscKey 的方案,当时有 Badger、TitanDB 这两个相对成熟开源实现。
TianDB 基于 RocksDB 扩展了 Key Value 分离的功能,天然兼容 RocksDB 丰富的特性,而且方便后续升级到高版本 RocksDB。而 Badger 是使用 GO 语言重新开发的存储引擎,Badger 支持的特性相对较少,PegaDB 使用了大量 RocksDB 的特性,选择 Badger 适配成本较高。再者 TianDB 也不会有 Badger GO 语言 GC 时带来的 STW 问题,因此最终选择了 TianDB, 并扩展实现了 CheckPoint 特性(已提交社区 #207)。
随着 RocksDB 社区全新版本的 Key-Value 分离实现 BlobDB(2021 年发布)越来越成熟, PegaDB 也从 TianDB 逐步迁移到了 BlobDB。
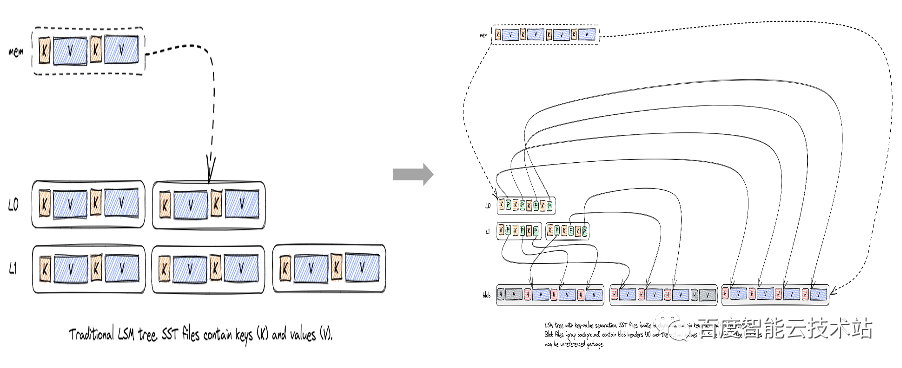
除了 Key-Value 分离,PegaDB 针对存储引擎还做了很多调优工作,主要有耗时抖动优化、读取优化、写入优化。
耗时抖动优化:利用Rate Limiter 对 Compaction 进行限速,支持部分 Compaction,升级高版本 RocksDB(Compaction 有显著优化 #9423),使用 Partition index/filter;
读取优化:Memtable 开启全局 Filter,Data Block 开启 Hash 索引,L0 和 L1 不压缩,自定义 Prefix Extractor,支持配置多 CF 共享和独享 Block Cache。
写入优化:Key-Value 分离,开启 GC 预读,开启 enable_pipelined_write,开启 sync_file_range。
接下来介绍一下在缓存方面所做的优化。
针对冷热数据区分明显场景通常采用传统 Cache (Redis)+DB (MySQL)架构,但是这种架构需要业务自己来维护 Cache 的 DB 的数据一致性,业务开发复杂度较高。
为此 PegaDB 支持了热 Key 缓存,单节点可支持百万级热 Key 访问, 大大简化了冷热区分明显场景的业务架构。
RocksDB 支持 Block Cache和Row Cache, 为什么 PegaDB 还要再增加处理层的缓存?
PegaDB 的热 Key 缓存,相比 Block Cache, 粒度更细,缓存利用率高;相比 Row Cache,没有 Compaction 导致的快速失效的问题,缓存命令中更高。
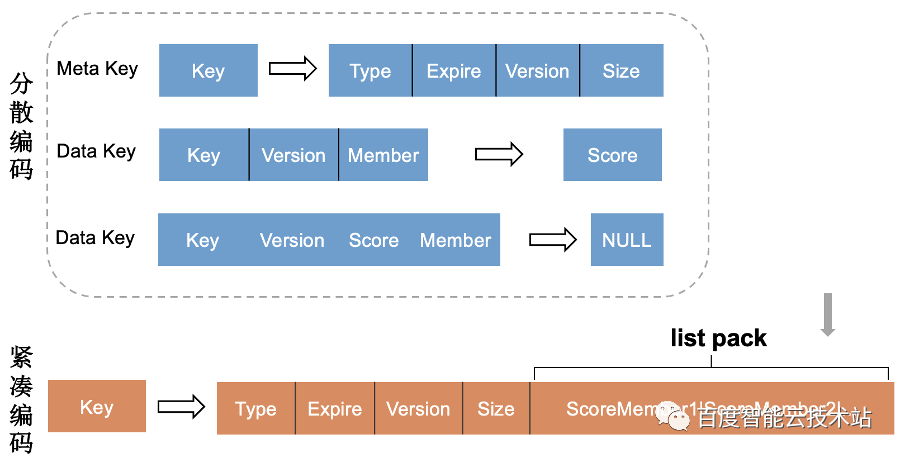
在编码优化方面,Kvrocks 分散编码的方式在批量、范围操作时会涉及多次磁盘 IO 性能差。PegaDB 自定了前缀迭代器,显著提升了迭代效率。
同时,PegaDB 扩展了紧凑型编码,批量、范围操作时,一次磁盘操作可以读到全部的数据,大大提升了性能。
2.10 异地多活架构
百度很多业务场景对可用性有着很高的要求,需要支持地域级别容灾。这就要求 PegaDB 支持多地域部署,同时为了降低业务访问延迟,PegaDB 多个地域的集群还需要支持就近访问。
为此,PegaDB 设计了异地多活的架构。PegaDB 并没有采用传统基于 DTS 的方案来进行多个地域间数据的同步,这主要是出于同步性能的考虑。
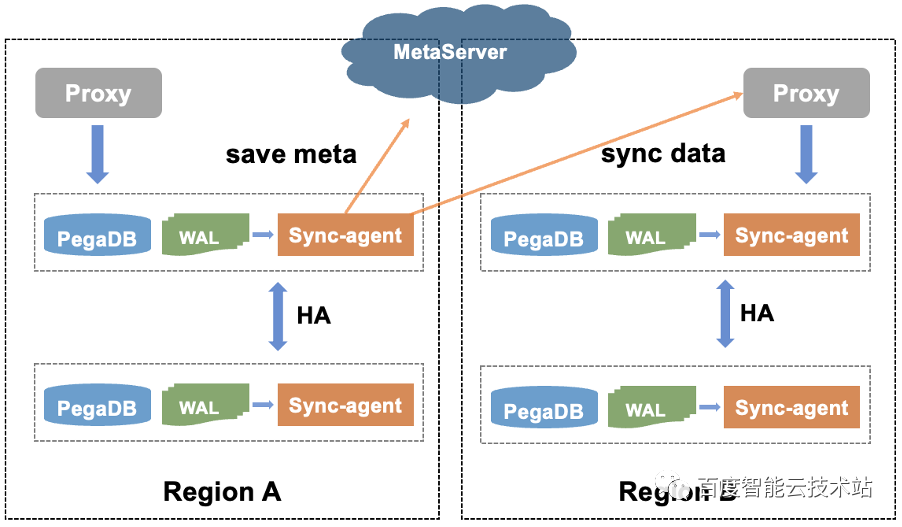
如下图所示,PegaDB 设计了 SyncAgent 同步组件来同步数据,SyncAgent 和 PegaDB 同机部署,并且出于 HA 考虑 SyncAgent 在 PegaDB 主从实例上都会部署,但是只有主库上的 SyncAgent 会工作。
为了避免循环复制,在 WAL 日志中增加了 ShardID 信息,ShardID 全局唯一,SyncAgent 通过 ShardID 区分是否是本地域写入的数据,SyncAgent 只会同步本地写入的数据,因此也就解决了循环复制的问题。
为了支持断点续传,PegaDB 增加了 OpID 信息,OpID 单调递增,并且会及时更新到配置中心,同步中断后基于配置中心中存储的 OpID 信息进行断点续传。对于异地多活架构,还需要解决多地域写冲突的问题, PegaDB 采用简单的 LWW 方案(Last Write Win)。
2.11 PJSON 数据模型
PegaDB 虽然兼容 Redis 丰富的数据类型,但是业务实际使用过程中仍遇到了一些问题。比如业务要存储 JSON 格式的数据,只能转换成 STRING/HASH 数据类型来存储,这就带来了一些问题:
- 需要业务对数据进行序列化/反序列操作,增加了开发复杂度;
- 读取、更新部分字段,存在读写放大问题;
- 并发更新字段时存在数据一致性问题。
针对上述问题,PegaDB 借鉴 RedisJSON Module 的思路,原生支持了 JSON 数据模型,这样做的好处是业务无需再做模型转换,使用 STRING/HASH 存储 JSON 格式数据的问题自然也就没有了。
PegaDB 的 JSON 数据模型完全兼容 RedisJSON Module 的协议,同时支持 JSONPath 语法查询和更新文档中的元素,支持原子操作所有 JSON Value 类型,并且采用了紧凑型编码存储,天然支持热 Key 缓存,对于冷热区分明显的场景特别友好。
2.12 ZSET&HASH 命令增强
除了 JSON 等新增的数据类型,PegaDB 结合业务需求对现有数据类型也做了很多扩展,比如:ZSET 类型支持聚合、结果过滤操作,HASH 类型支持 Range 操作。
3. 开源社区协作
PegaDB 从设计之初,就坚定了深度参与社区,与社区共建的思路。截止到目前 PegaDB 已经持续向 Kvrocks 社区回馈了主从复制优化、事务、存储引擎优化、集群等多个重要 PR。并且与社区一起推进了 Kvrocks 成为 Apache 孵化项目,目前百度智能云 Redis 团队拥有 2 名 Kvrocks PPMC 成员(共 4 名),4 个 Commiter。
4. 未来规划
未来 PegaDB 会继续在以下几个方面继续提升:
- 借助云基础设施进一步提升弹性能力,发布 Serverless 产品
- 借鉴 Redis Module 生态,支持更丰富的数据模型
- 支持连接器,更方便集成大数据生态,简化业务开发
- 通过内核 io_uring 特性、线程模型优化等方案持续优化性能
广告时间:百度智能云 Redis 容量版(PegaDB)已经在百度智能云正式发布,欢迎大家使用!
相关文章推荐
发表评论
关于作者

- 被阅读数
- 被赞数
- 被收藏数
登录后可评论,请前往 登录 或 注册