redis 持久化有几种方式?
作者:笔耕不辍者2024.02.28 15:09浏览量:1964简介:Redis 作为“扛流量”和“性能加速”的利器,是业务架构中不可或缺的组成部分。
Redis 作为“扛流量”和“性能加速”的利器,是业务架构中不可或缺的组成部分。Redis 服务一旦出现问题,就可能会导致业务系统直接崩溃。想要打造稳定可靠的 Redis 服务,掌握 Redis 内核原理至关重要。
本专题会从内核设计视角出发,以 2.0 到 7.0 版本演进为主线,详细介绍 Redis 核心内核机制的设计与实现。同时还会分享百度智能云在 Redis 内核的优化经验,带你从理论和实践两个层面深入理解 Redis 内核机制。
我们相信,这将会是你看到过的最深入的 Redis 内核专题分享。
此次 Redis 专题共有 4 期内容。本文是第 2 期内容,整理自 QCon+ 案例研习社的演讲内容,视频链接见文尾。后续 2 期内容都将在“百度智能云技术站”公众号首发。
今天分享的主题是 Redis 持久化机制的演进与百度智能云的实践,我会从以下四个部分来分享:
- Redis 持久化机制简介
- RDB 机制的演进与百度智能云的实践
- AOF 机制的演进与百度智能云的实践
- Redis 未来的持久化
1. Redis 持久化机制
1.1 Redis 持久化机制简介
首先我们先来简单了解什么是持久化?在计算机科学中,持久化的定义是一个系统的状态特征比创造它的过程更持久,而一般普遍的方法是将系统状态作为数据存储在计算机的持久存储器中。
这是一个非常抽象的概念,那结合 Redis 来看,Redis 持久化就是将 Redis 内存中的数据写入持久存储器的过程,比如将内存中的数据写入 SSD。而 Redis 为我们提供了三种方法,第一是 RDB,第二是 AOF,第三则是 RDB 和 AOF 混合持久化。
在详细了解这三个持久化机制之前,我们先重点关注两个问题:1. Redis 持久化的方式。2. Redis 持久化的格式。
1.2 RDB(Redis Database)
RDB,它的全称是 Redis Database,它的定义是将数据集的快照以二进制格式保存在持久存储器中。从定义中可以找到刚才两个问题的答案:1. RDB 持久化的方式:快照。2. RDB 持久化的格式:二进制数据(压缩紧凑)。
RDB 持久化的方式决定了其触发的方式。Redis 提供了三种触发方式,分别是手动触发、自动触发以及被动触发。
1.3 AOF (Append Only File)
AOF 持久化的定义是将 Redis 内存中的更改以 RESP 的格式追加写到持久化的存储机制。从定义中我们可以找到刚才两个问题的答案:1. AOF 持久化的方式:追加写。2. AOF 持久化的格式:RESP 格式(文本协议,可读性高)。
AOF 持久化追加写的 RESP 格式是一种文本协议,虽然可读性高,但是导致 AOF 文件的大小是一个单调递增的过程,因此 Redis 提供了 AOF rewrite 机制,用来解决 AOF 文件大小膨胀的问题。
AOF rewrite 的定义是将 Redis 数据库的快照以 RESP 或者 RDB 的格式写到持久存储器,然后追加该时间点之后的所有 AOF 数据。从定义中我们也可以找到刚才两个问题的答案:1. AOF rewrite的方式:快照和追加写。2. AOF rewrite的格式:二进制或 RESP。
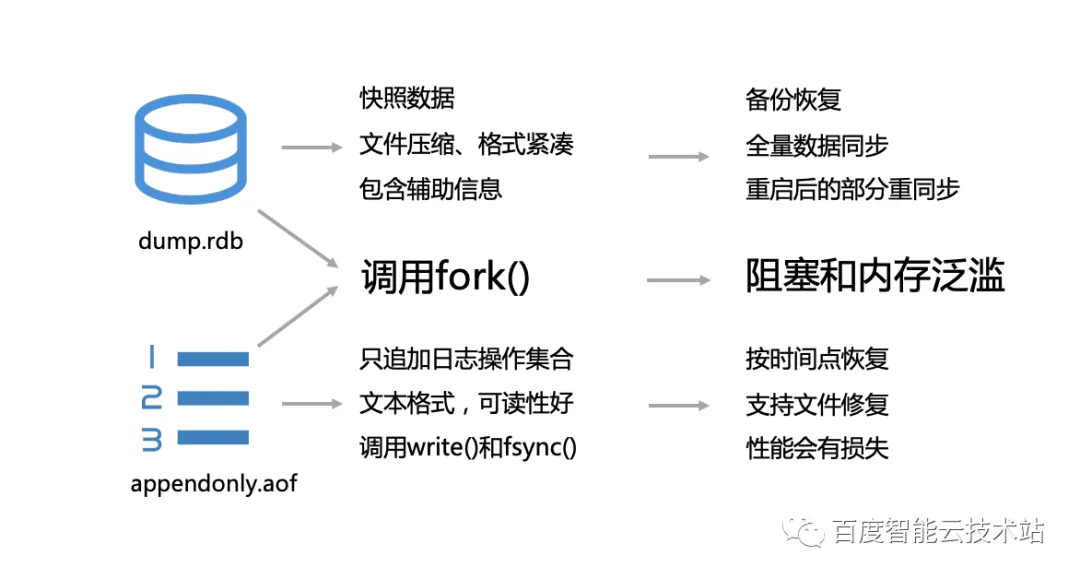
RDB 和 AOF 的性质决定了它们的特点以及应用场景,但是它们的共性是都会调用 fork() ,而 fork() 则会有阻塞和内存泛滥的问题。我们在下面会讲到百度智能云的解决方案。
2. RDB 机制的演进与百度智能云的实践
2.1 RDB 机制演进
RDB 持久化的演进已经发展到第十个版本。下图列举了 Redis RDB 持久化机制的所有版本。我们来重点看看这几个版本的变化。
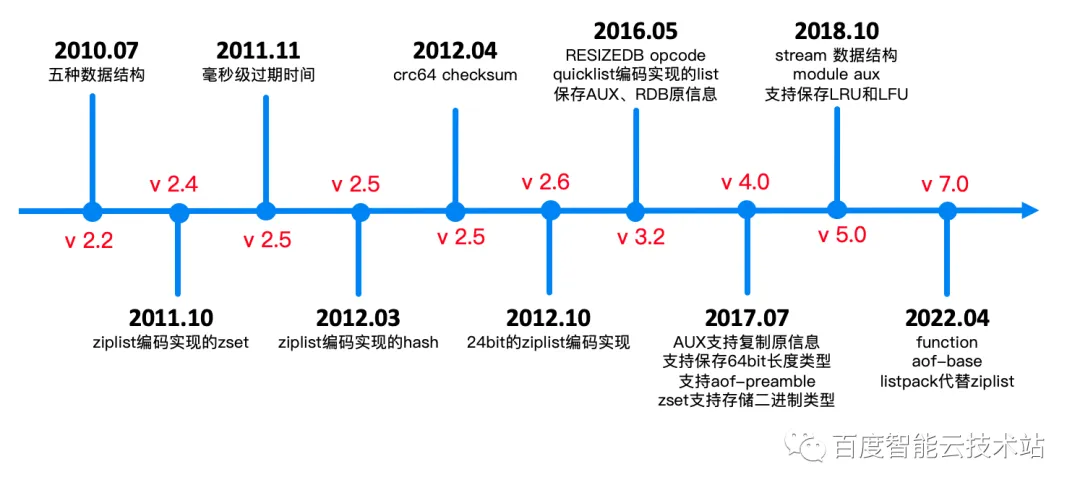
- 2011 年 Redis 2.5 版本支持了毫秒级的数据过期。
- 2012 年 Redis 2.5 支持了 crc64 校验的功能。
- 2017 年 Redis 4.0 支持了复制元信息并且支持保存 aof-preamble 信息。
- 2018 年 Redis 5.0 支持了 LRU 以及 LFU,这是非常重要的特性。
- 2022 年 Redis 7.0 支持了 function 以及 aof-base。
2.2 RDB 持久化流程
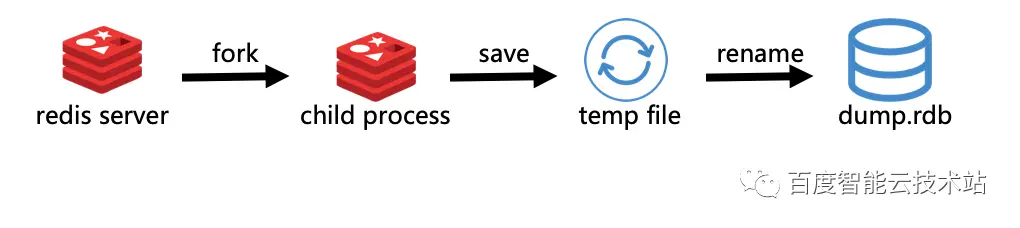
Redis 的主进程会 fork() 一个子进程。子进程来执行 save 操作,在 save 操作完成之后,它会将临时文件 rename 成一个正式文件 dump.rdb。Redis 社区的 RDB 持久化机制就是使用了 fork(),而 fork()是一把双刃剑。
fork() 帮助 Redis 非阻塞地执行 save,并且生成一个快照。但是 fork() 同样也有一些问题,首先它是一个阻塞性的系统调用,其次 COW 机制会导致内存过度使用。因此百度智能云设计并实现了 forkless 这个方案。
2.3 百度智能云 RDB 持久化优化:forkless
百度智能云从 Redis 4.0 开始探索 forkless 的方案,其设计思想如下:
- 分而治之:将阻塞式 save 设计为渐进式的 save ,主进程控制 save 的进度和处理请求,子线程来执行 save 以及处理 IO
- Redis 内核实现 COW 机制,解决多线程访问数据冲突的情况。
- RDB 和 AOF 有序混合的快照格式。
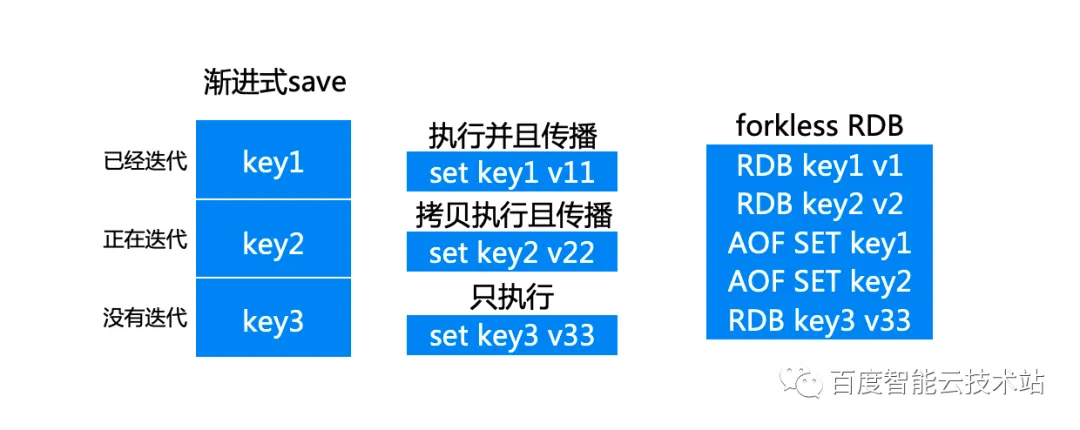
渐进式 save 将数据分为三种状态,已经迭代,正在迭代以及没有迭代,分别对应key1、key2 以及 key3,而此刻对应的 forkless RDB 格式 key1 和 key2 是 RDB 格式。
假如此时一个请求要访问 key1,key1 属于已经迭代过的数据,则在主进程执行,子线程做传播;假如此时请求要访问 key2 ,key2 属于正在迭代的数据,则进行冲突解决,主进程拷贝一份 key2 的 value,然后在主进程中执行,子线程中传播。如果请求要访问 key3,key3属于没有迭代的数据,那么则直接在主进程中执行即可。
3. AOF 机制的演进与实践
3.1 AOF 机制演进
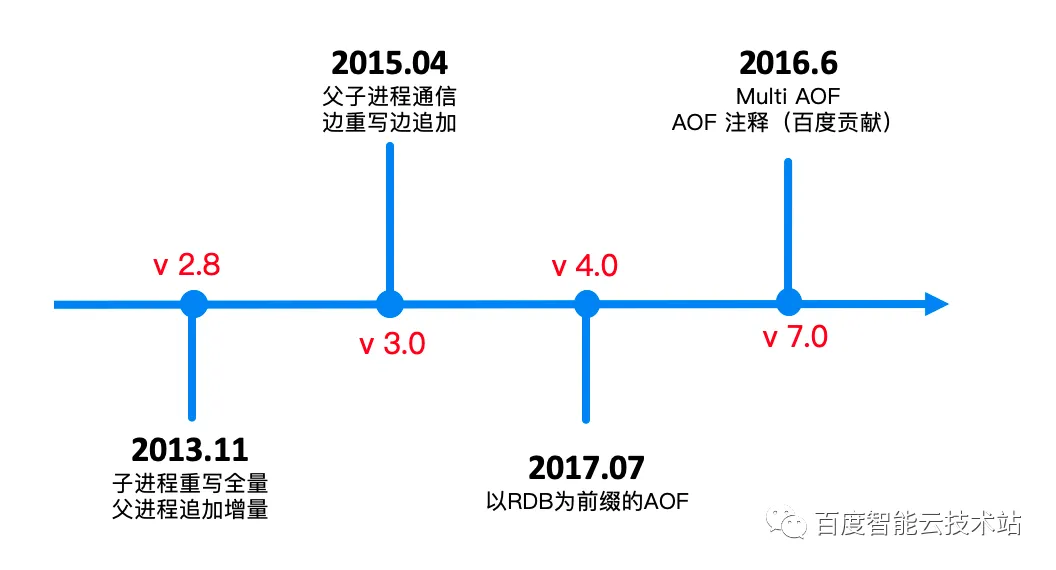
- 2013 年 Redis 实现了第一版的 aof-rewrite 机制,它有追加增量数据导致阻塞的问题
- 2015 年 Redis 3.0 的时候进行了优化,采用了父子进程之间通信的方式。
- 2017 年 Redis 实现了以 RDB 为前缀的 AOF,就是我们刚才所提到的 RDB 和 AOF 混合持久化,它是以 RDB 为前缀。
- 2022年 Redis 7.0,Redis 实现了Multi AOF 的架构,并且在 AOF 命令中添加了扩展注释功能。扩展注释可以帮助 AOF 实现更多功能,我们后面会讲到,并且这个 Feature 是百度智能云贡献给社区的。
3.2 AOF 重写
3.2.1 Redis 2.8 及以前
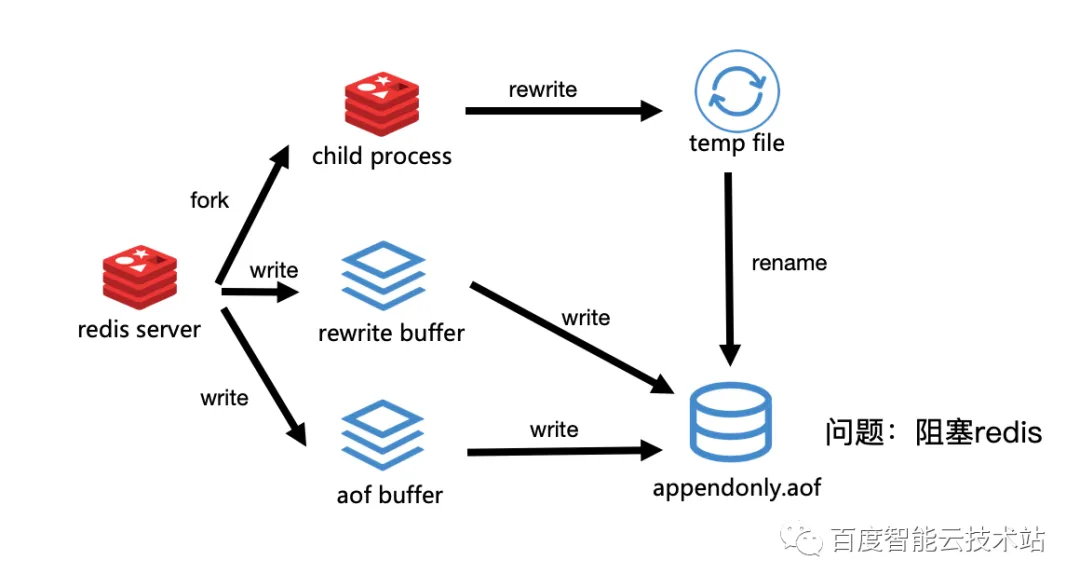
在 Redis 2.8 之前,Redis Server 会 fork() 一个子进程,子进程会进行重写操作。在重写操作的期间,Redis 会将它重写期间数据库的更改存在两个地方,第一个是 rewrite buffer,第二个是 aof buffer。rewrite buffer 是为了保存 rewrite 期间的变更,而 aof buffer 是为了进行 AOF 持久化。当子进程完成重写之后,它会将临时文件 rename 成 AOF 文件。此时如果将 rewrite buffer 一次性地全部写给 AOF 文件,就会导致阻塞 Redis。因此在 Redis 3.0 时候,优化了该问题。
3.2.2 Redis 3.0
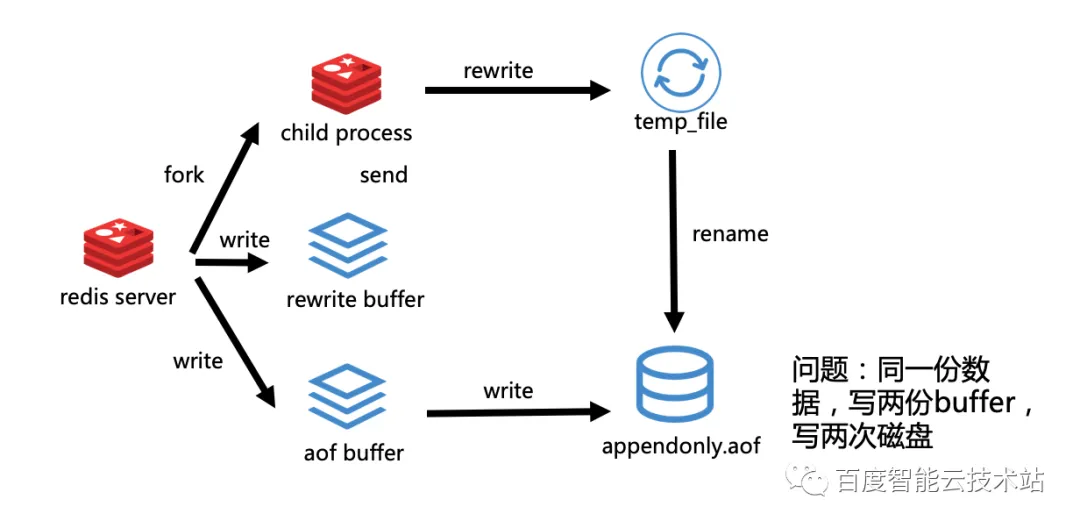
从 Redis 3.0 开始, 首先还是 fork() 一个子进程,子进程来做一个 rewrite 操作。与刚才 Redis 2.8 不同的是,它会在重写期间将 rewrite buffer 内容分多次由主进程发给子进程,子进程来将这部分数据刷到 AOF 文件中。这样一来就解决了当子进程完成 AOF 重写之后,一次性发送 rewrite buffer 阻塞的问题。
这似乎是一个不错的方案,但是也有一些问题。我们可以看到 Redis 在重写期间,会将更改分别写到 rewrite buffer 和 aof buffer,而这两次 buffer 会由主进程和子进程分别刷到磁盘。问题就是同一份数据写两份 buffer 并且刷两份磁盘,这是很严重的资源浪费。
因此在 Redis 7.0 的时候,Redis 社区设计了 Multi Part AOF 的架构。它的方式就是将原来的一个 AOF 文件拆为多个 AOF 文件,分别包括一个 base.aof 和多个 incr.aof。base.aof 实际上就是一个全量数据,而 incr.aof 文件则是一些增量数据。
3.2.3 Redis 7.0 的 Multi Part AOF
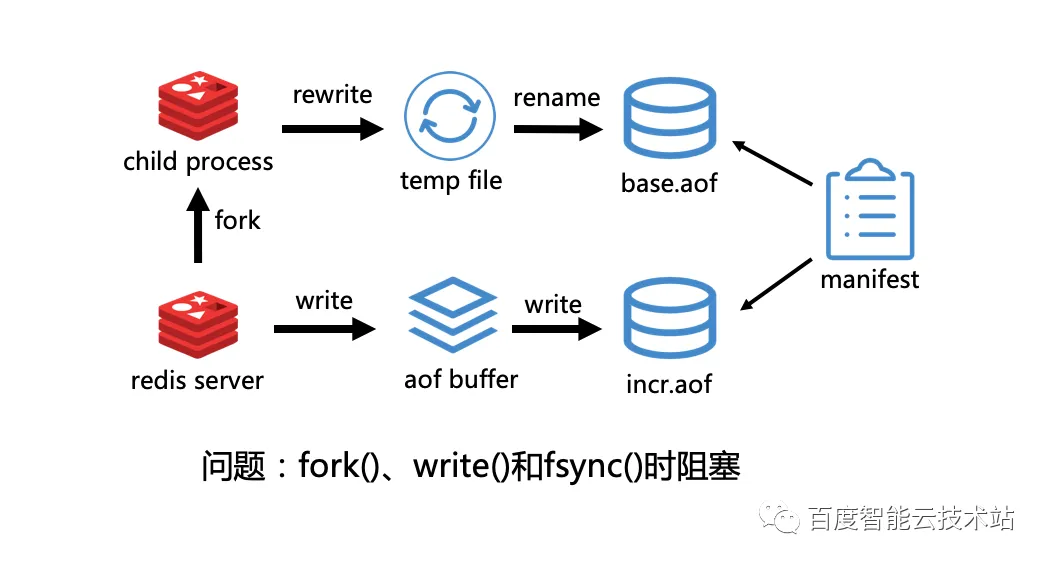
同样,Redis 主进程会 fork() 一个子进程,子进程来进行重写操作。而与之前版本不同的是,子进程只关心它的重写,不需要关心增量,因此它将全部重写的数据写完之后会生成一个 base.aof 文件,这部分数据代表它这个时刻的全量数据。在重写期间 Redis 会有许多更改,这些更改则由主进程递交给 aof buffer,进而由 buffer 主进程再刷到一个 incr.aof 增量文件中。然后 base.aof 和 incr.aof 由一个 manifest 的文件来维护它们的关系。
这看起来是一个比较完美的方案,但是该方案依然仍然会有问题:1. AOF 重写仍然需要调用 fork(),我们前面也分析过了,给出了相关的解决方案。2. Redis 进行 AOF 持久化的时候,会同步调用 write() 和 fsync(),可能会导致请求阻塞。
3.3 AOF 持久化的优化与实践:Multi AOF
百度智能云从 Redis 3.0 开始就实现了 Multi AOF 的架构,使用的是全量 RDB 加多个增量的 AOF 文件的方式,并且增量的 AOF 文件是以文件大小进行切割。并且 Redis 所有 AOF 命令都支持了扩展注释,这些注释会带有一些时间戳、命令属性以及地域属性。
基于 Multi AOF 进行了许多优化和实践,本次分享会介绍以下几个:异步 AOF、异地多活的实现、基于 AOF 文件的部分重同步 PSYNC-AOF 和按时间点恢复。
3.3.1 异步 AOF
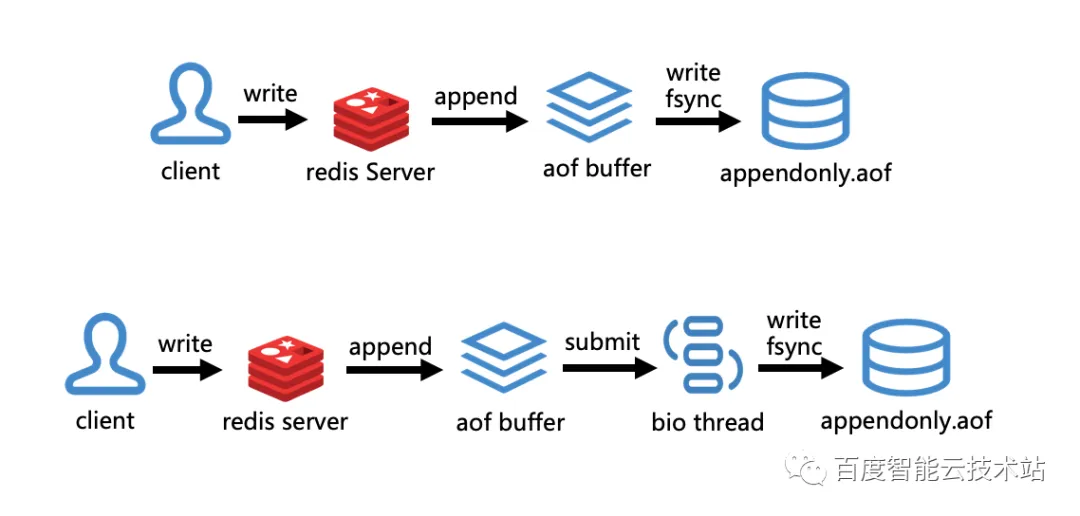
刚才提到了,Redis 的 AOF 持久化是一个同步的过程,由主进程执行写磁盘操作。而百度智能云的异步 AOF 则是主进程将写磁盘的操作递交给子线程,子线程来执行 fsync。这样的话就可以很好地解决同步 AOF 带来的阻塞问题。
3.3.2 基于AOF的部分重同步:PSYNC-AOF
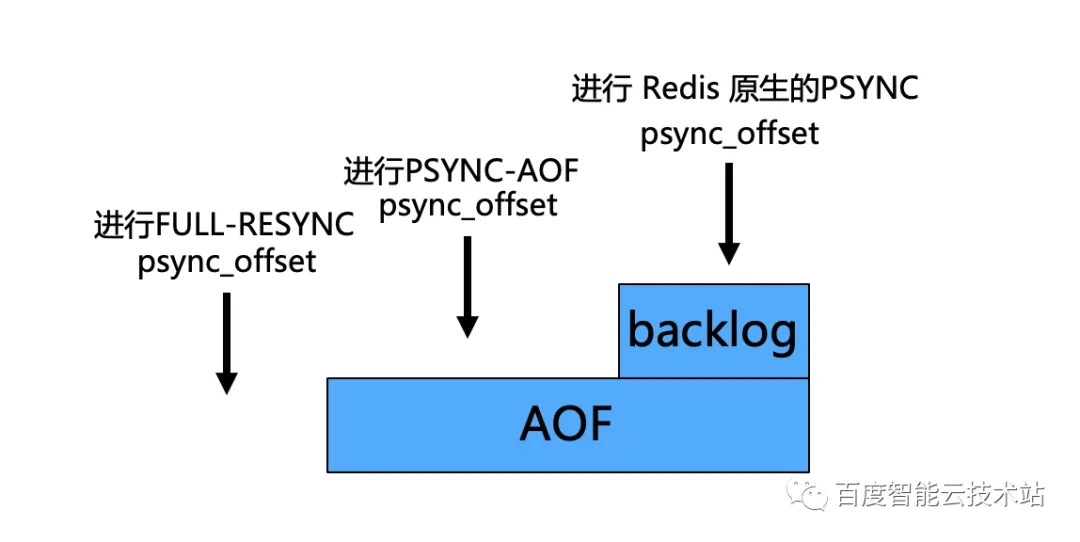
百度智能云基于 Multi AOF 实现了 PSYNC-AOF 这个功能。PSYNC-AOF 的全称是基于 AOF 文件的部分重同步。我们的目的是为了减少全量同步的次数,是因为社区的 Redis 部分重同步依赖于 backlog。backlog 是一个固定大小的内存,太大了会消耗内存,太小了则会容易触发全量同步,因此我们设计了 PSYNC-AOF 方案。
我们的思路就是将 AOF 作为一个更大的 backlog。当主从闪断时,从节点请求了 offset 落在了 backlog 数据范围之内,我们则进行一个原生的部分重同步;当 psync 落在了大于 backlog 而小于 AOF 文件的范围内,我们则基于 AOF 进行部分重同步;如果这个 psync 超过了 AOF 数据的大小范围,我们则进行一个全量同步。
3.3.3 异地多活
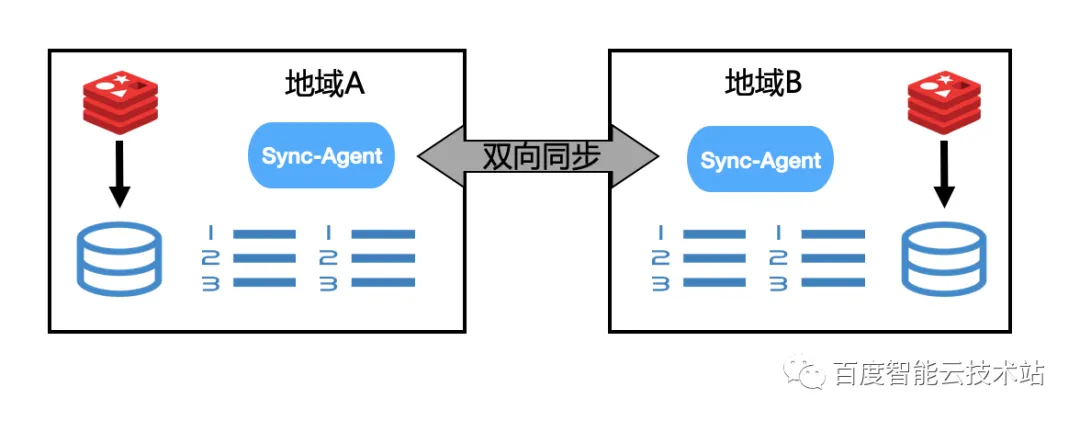
百度智能云自研了同步组件 sync-agent 支持异地多活,并且支持了冲突解决。Redis 会将所有更改数据持久化到 AOF 中,而所有持久化的 AOF 中的命令都会带有注释功能,在注释功能中会有一些地域分片信息,因此 sync-agent 解析 AOF 之后就会同步到其他地域。
在这个过程中,其他地域是如何区分到其他地域和本地域的请求,以防止写回环呢?就是通过其他地域转发过来的 AOF 中带有的地域信息来区分。
3.3.4 基于按时间点恢复
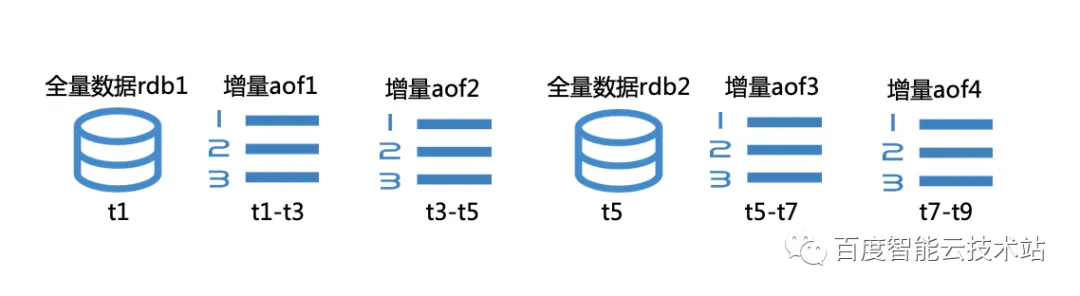
每个 rdb 文件表示一个时刻的实际,而 aof 文件表示一个时间段数据。假如要恢复到 t6 时刻,首先我们需要先加载距离 t6 时刻最近的起始时刻 rdb,然后在加载其后连续的 aof 文件,直到加载到包含 t6 时刻的 aof 文件。这样我们就可以实现按时间点恢复功能。
4. Redis 未来的持久化
了解完 Redis 持久化机制的演进和百度智能云的优化实践后,我们一起来畅想一下 Redis 未来的持久化。当前 Redis 的持久化都是从 DRAM 到 SSD ,而未来持久化的存储介质一定是新的存储介质:持久化内存,它具有高性能低延迟等特点,处于 DRAM 和 SSD 之间,目前在百度智能云已经有一些成功的实践,我们会在此方面继续探索。
最后,回顾一下,最开始我们了解了 Redis 持久化的定义,又分别介绍了 Redis 的两种持久化机制演进和百度智能云的优化实践,现在关于 Redis 持久化机制的 How 和 What 的两个问题,在你心中已经有了一些答案。
方案没有好坏,只有取舍。 是选择 RDB 还是选择 AOF,我相信大家心中自有答案。
相关文章推荐
发表评论
关于作者

- 被阅读数
- 被赞数
- 被收藏数
登录后可评论,请前往 登录 或 注册