打造高性能 IaaS 计算架构,百度智能云 DPU 落地实践
2023.05.23 16:54浏览量:1770简介:本次演讲分享了百度智能云如何利用 DPU 建设统一的高性能 IaaS 计算架构。
如今越来越多的企业将 IT 基础设施搬到了云上,算力需求的迅猛增长对云服务商带来了诸多挑战。以 AI 训练这种计算负载为例,目前约每 3.5 个月 AI 算力的需求就会翻倍一次,算力需求的迅猛增长对云上的计算和网络都提出了更高的要求。当前百度智能云最新的云服务器产品支持 200Gbps 的网络带宽,以满足持续增长的用户算力对于网络 I/O 的高要求。
随着算力需求的迅猛增长,一些问题也日益严重:
算力和网络带宽的发展增速之间存在 GAP,并且这个 GAP 还会逐年增大。比如在高性能计算的场景下,1.6T 的 RDMA 互联带宽开始逐渐成为头部客户选择的网络配置,但是 CPU 算力性能的增速比不上 I/O 带宽的增速,算力反而会成为整体提效的瓶颈。
另外在云管一体的架构下,普通网卡只具备将服务器接入网络的能力,并不具备任何硬件加速能力,像网络的虚拟化、存储的虚拟化、I/O 的虚拟化等能力都需要 CPU 来支持。由于 I/O 带宽的提高,CPU 需要分担更加繁重的数据处理任务。比如百度智能云一些老套餐没有采用 DPU,需要给网络存储虚拟化还有基础服务预留出一些超线程核,最多的时候预留会占我们宿主机所有超线程核的大概 17% ,这部分的占用会严重的影响到我们整体资源的效能。
随着云上计算产品品类的增多,配置也越来越复杂,综合管理成本也会快速上升。以百度智能云常见的云服务器类型为例,虚拟机实例的宿主机会搭载普通网卡,需要为数据处理预留一些核心,在配置和运维等方面也有额外要求。裸金属服务器实例一般会用到智能网卡,能够实现对网络虚拟化的卸载,但是由于智能网卡能够实现的网络虚拟化能力有限,在整体性能、弹性上仍然存在大幅优化空间。另外,传统的智能网卡对 RoCE 协议的支持能力有限,缺少协议方面的优化。
这些差异导致了不同类型的实例需要不同的软硬件配置以及不同的运维手段。首先资源的弹性会受到影响,基础架构越统一,在大规模资源下的弹性才越有保障;其次随着节点规模增大,综合管理成本也逐步升高,这种管理难度的提升最终会影响到产品的 SLA 稳定性保障;此外对于用户不够友好,产品功能和特性上的差异会带来更多的学习和使用成本。
随着算力需求的多样化,客户的使用场景日趋复杂,对于计算产品底层开发实现难度也会越来越大。比如现在更多的用户会通过容器来调用资源,并且在容器之上去实现业务分时混部和多业务的资源抢占,这种更细粒度的算力切分和更加灵活的调度会对我们的产品能力有更高要求;其次在安全方面,用户对网络安全隔离、流量管理、流量加密等方面也都有较高的要求;还有像 AI、在线服务集群等场景对于云存储的访问希望能达到本地盘级别的性能表现,对 GPU 的通信性能也有较高要求。面对如上用户场景,云服务商的底层架构必须要做到软硬结合才能够最大程度降低各种硬件和软件的适配成本,降低产品底层实现难度。
针对如上几个问题,引入 DPU 是一个很好的解决方案,云服务商可以通过 DPU 来卸载 CPU 数据处理压力、打平资源的软硬件差异、在功能和性能上灵活满足客户使用场景。
综合来看, DPU 可以承担计算、网络、存储的虚拟化,以及安全和管理控制等方面的数据处理任务,能够释放宿主机 CPU 上的资源消耗。CPU 的算力能够百分之百地应用到客户实际工作负载当中,不仅提升了资源整体利用率,更可以打平软硬件差异,降低开发和管理成本,提升整体资源规模和弹性。
DPU 专用的硬件架构也可以对一些特殊计算负载进行加速,比如 DPU 可以去做数据的加解密工作,让数据加解密环节前置到网络与主机交换数据时来进行,从而简化数据传输流程。DPU 也可以实现硬件级别的加解密算法支持,进一步加快数据处理速度。

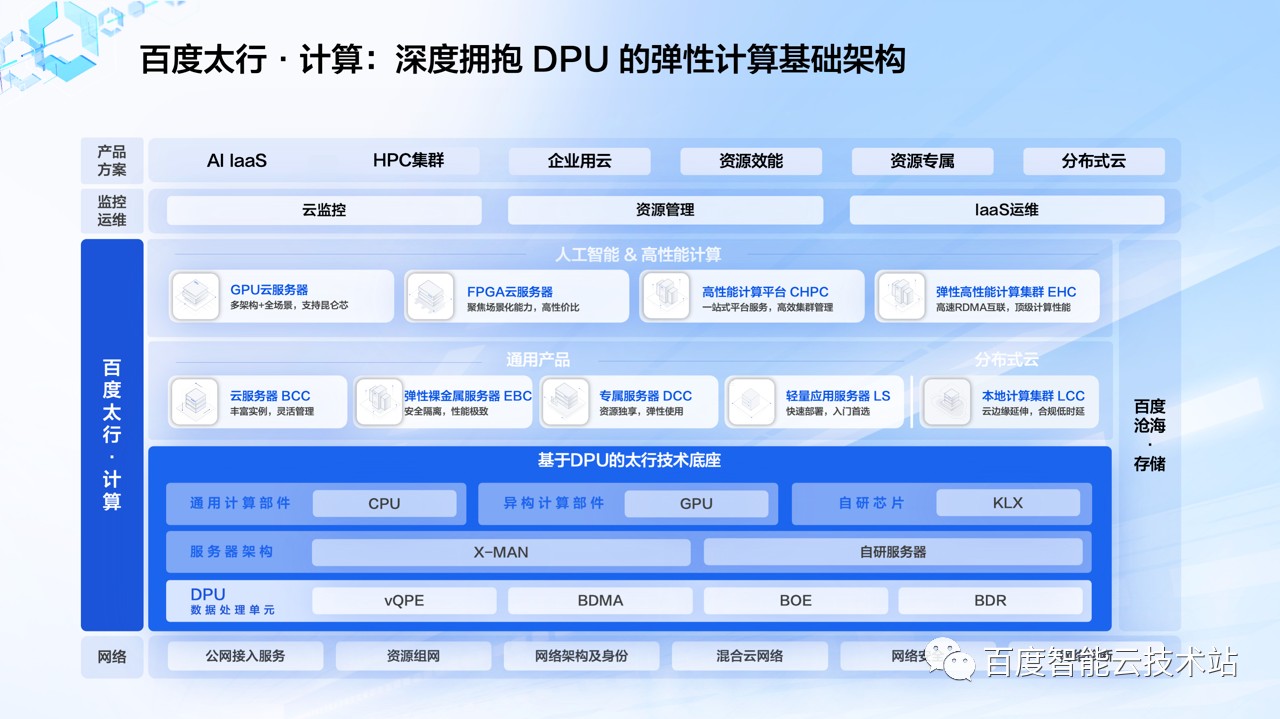
下图是百度智能云公有云 IaaS 产品「百度太行·计算」的概览图,从计算、网络、到监控运维以及相关产品方案,我们为客户提供了丰富的产品和解决方案支持。
「百度太行·计算」是百度智能云公有云的计算技术品牌。基于 DPU 的百度太行的计算的技术架构,融合了百度自研的服务器架构、核心的计算部件和核心的技术引擎。
从轻量应用服务器产品,到虚拟机形态的云服务器产品 BCC,再到弹性裸金属服务器产品等,从通用计算到传统 HPC、AI 异构计算等,我们为客户打造了多形态、多元算力的产品布局。「百度太行·计算」产品具备高性能、高弹性、高可用的强大的算力底座,充分满足 AI 原生时代的海量算力需求。
在整个「百度太行·计算」的技术底座里 DPU 是一个非常核心的组成部分,我们在 DPU 中集成了多个自研的硬件引擎:
vQPE 硬件引擎,能够提升宿主机单机资源利用率,管理宿主机设备增删改配和数据交互,屏蔽硬件多样性与复杂性,实现多元算力的云化部署;
BDMA 硬件引擎,面向不同业务流量分发定义了一套白盒化的软硬件交互的编程接口,实现高性能、高可用、高扩展的架构设计,使上层软件可以享受最优的 I/O 体验;
BOE 硬件引擎,将网络任务中负责流表匹配的逻辑从 CPU 中分离出来,下沉到 FPGA 去做加速处理,通过快速路径(Fast-Path)和慢速路径(Slow-Path)进行分离;
BDR 协议卸载引擎,将百度自研高性能网络的软件堆栈从 CPU 中分离了出来,下沉到 FPGA 中加速处理,构建了数管分离的架构,为用户提供了超大带宽、超密连接和超低时延的 RDMA 网络连接能力,能够以更低的成本来支持更大规模 RDMA 组网。
我们展开来看「百度太行·计算」如何利用 DPU 打造计算产品。
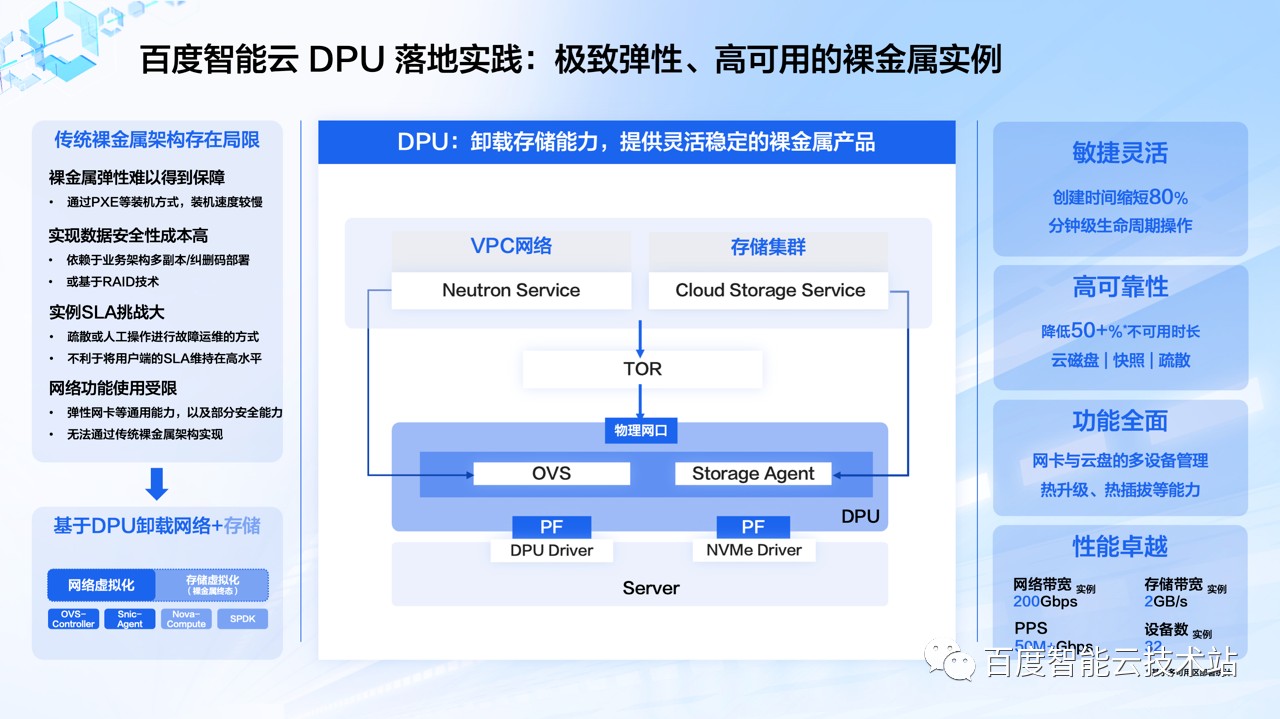
首先在裸金属服务器产品上,最开始在没有使用 DPU 或者智能网卡的时候,我们的裸金服务器产品在网络和存储等方面的弹性和能力都是比较弱的。
网络方面,我们的第一代裸金属服务器实例实现了接入 VPC 并和用户的虚拟机实例在虚拟网络中打通互联,但是网络虚拟化的卸载是做在了 TOR 交换机里边,通过 TOR 交换机去做 overlay 网络的终结。这种方式可以支持虚拟网络打通,但是灵活性是非常差的,没办法做到灵活调整,而且虚拟网络上的一些特性,比如说安全组、弹性网卡等也是没有办法支持的。
存储方面,在没有采用 DPU 的阶段块存储是直接使用物理服务器上的本地磁盘。这里会有两方面的问题:第一方面是我们在创建裸金属服务器时,服务器实例装机和启动的过程必须要通过 PXE 等装机方式,镜像也需要从远程拷贝到本地磁盘上,整体装机和启动速度非常缓慢,一般会在这个二十多分钟;另一方面是裸金属服务的数据盘也会用到本地盘,在空间和性能上都会受限于服务器的机型配置,可用性和扩展性都比较弱。
基于 DPU 我们实现了网络和存储虚拟化的卸载并大幅度提升了裸金属服务器在弹性、可靠性、功能等方面的表现。「百度太行·计算」通过 DPU 使得裸金属服务器获得了虚拟网卡与云盘等多设备管理能力,以及具备热升级、热插拔等特性,裸金属服务器在弹性以及功能特性等方面和虚拟机打平。这让裸金属服务器实例在算力上达到和物理服务器一样的性能,在弹性灵活性等方面等同于虚拟机,做到鱼和熊掌可以兼得。
在实例创建时间上,搭载了 DPU 的新一代裸金属服务器实例创建周期较之前缩短 80%,实现了分钟级开启裸金属服务器实例的能力。虚拟机镜像、迁移等相关特性在裸金属服务器上的支持,使裸金属服务器的可用性有了进一步提高,平均不可用时长可以降低 50% 以上。此外 DPU 具备强大的性能,让裸金属服务器能够很好地满足绝大多数场景的工作负载。
我们再来看看 DPU 在虚拟机实例方面的落地实践。
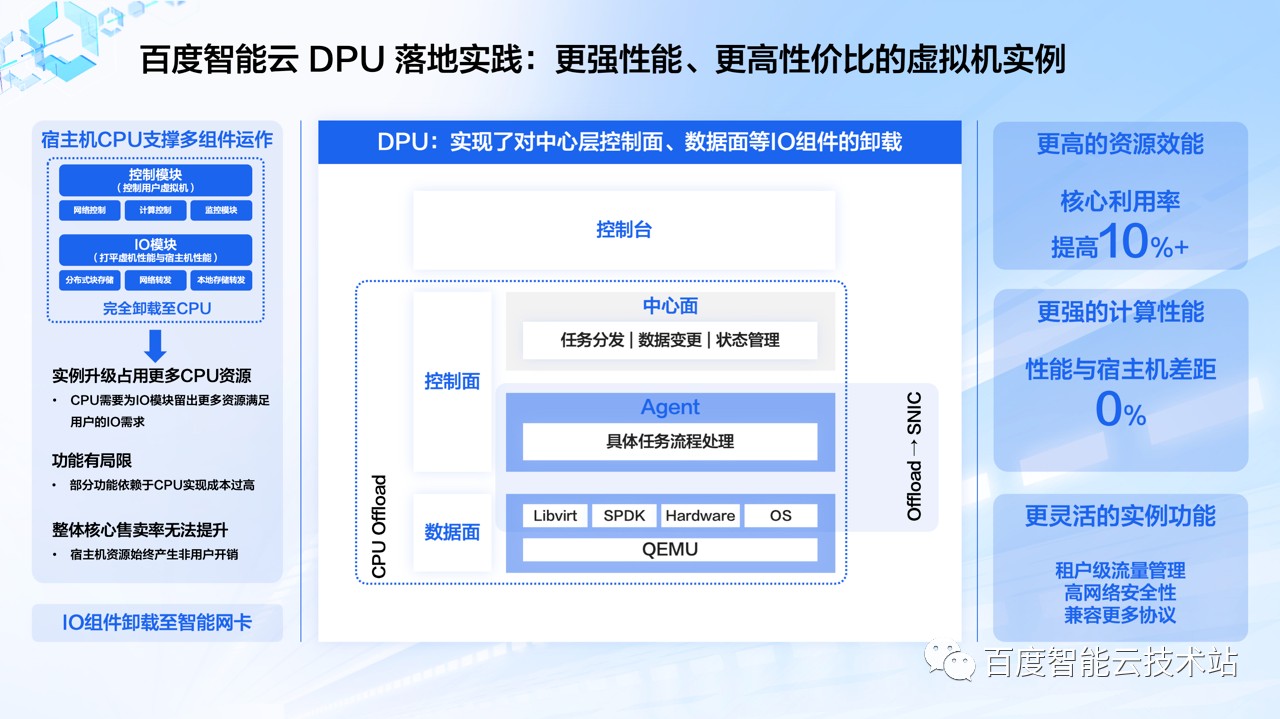
在过去,云服务器产品 BCC 宿主机的 CPU 承载了全部的管理以及数据处理工作,宿主机上可以真正用于用户业务负载的核心数还是非常有限的,就像我们最开始提到的,用户对于 I/O 性能要求的增速要逐步高于 CPU 核密度的增速。此外这种性能要求越高,有效核心数就越有限,无形中也增加了更多的 CPU 核心占用成本,同时限制了产品能力的提升。
目前,「百度太行·计算」将控制面的一些 Agent,还有数据面的相关组件卸载到 DPU 上面,这样云服务器 BCC 可以将宿主机所有的 CPU 核心都用在用户业务负载,BCC 最大规格虚拟机的能力可以和裸金属形态打平。这么做可以带来很多好处:
我们整个资源效能有所提升,综合提升 10% 到 20%,反馈到虚机实例的综合性价比也会有所提升;
在计算性能方面,虚拟机可以做到无损耗,性能强劲,改变了大家心目中通过计算性能来界定虚拟机和裸金属的习惯,很多场景也不需要去购买裸金属形态并自建虚拟化层;
在功能层面,借助 DPU 我们能够支持如租户级的存储带宽和网络带宽管理,且能具备更多特性,比如计算增强、安全增强相关的能力。
在 DPU 的加持下,「百度太行·计算」推出了多款虚拟机和裸金属服务器的相关规格套餐。
在云服务器 BCC 里我们通过 DPU 实现了计算虚拟化的卸载并实现了实例级 QoS,推出了第六代的 BCC 实例。同时在第五代的本地盘实例中,我们通过 SRIOV 技术将本地盘做更细粒度的切分,从而做出规格更小本地盘云服务器实例。
在裸金属服务器中,我们通过 DPU 完整地支撑了裸金属服务器实例的相关的功能特性,真正的做到弹性的裸金属服务器。我们推出的 L5 和 LA2 裸金属服务器实例能够做到 32GBps 的 I/O 带宽,另外也有高主频的裸金属实例 HCL5。
在异构计算方面我们有配置 NVIDIA 英伟达安培 GPU 卡的裸金属服务器,同样加载了DPU。在裸金属服务器以及虚拟机云服务器 BCC 之上,依托于 DPU 的支持,「百度太行·计算」 产品大幅提升了对云原生场景的支持能力。

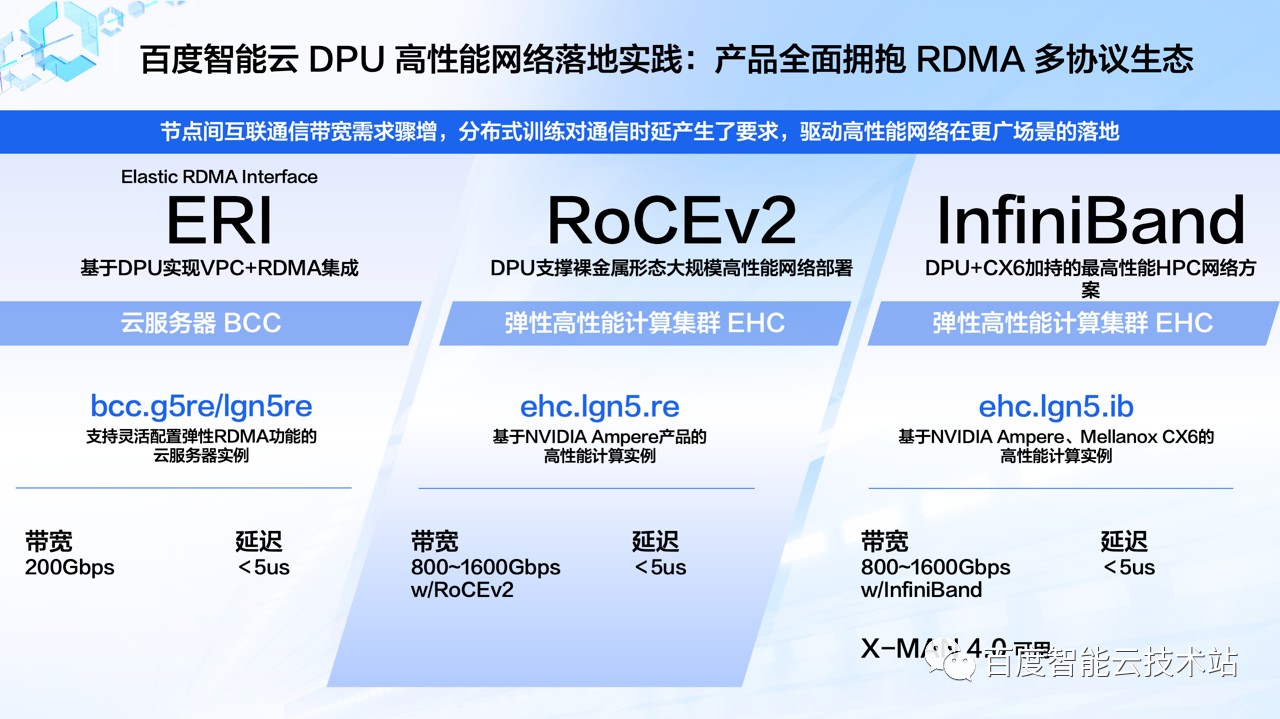
DPU 在高性能网络上的支持帮助百度智能云落地了弹性 RDMA 网络实例,以及支持 RoCEv2 和 InfiniBand 协议的专有 RDMA 网络实例。
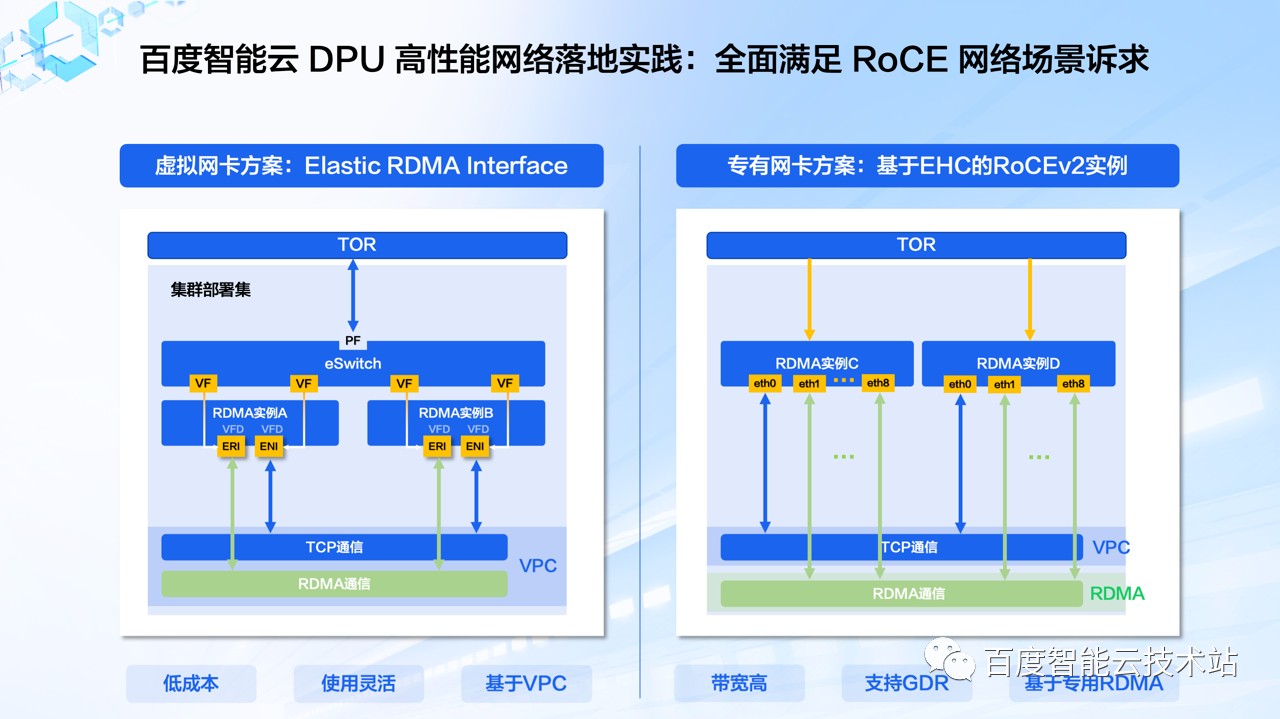
「百度太行·计算」提供两种类型的产品方案给到客户:
首先是虚拟网卡方案,也就是弹性 RDMA 网络实例。基于虚拟网卡方案的 ERI(Elastic RDMA Interface) 实例,这类实例的网卡来自于 DPU 上的 VF 设备,用户可以通过控制台来按需配置和定义弹性网卡和弹性 RDMA 网卡,灵活地满足了业务对网络的要求。
DPU 同时实现了对 TCP 和 RDMA 协议网络流量的处理能力,让用户可以在 VPC 的网络架构上获得对 RDMA 网络支持。我们在虚拟机和裸金属实例上都实现了对弹性 RDMA 网卡的支持,帮助用户灵活应对 HPC、并行文件存储、大数据、数据库等场景下对于高速网络的需求。
第二个方案是专用 RDMA 网卡方案。基于 DPU 和 Mellanox Connect-X 系列设备,实现单实例同时具备百 Gbps 级别的 VPC 网络以及高速 RDMA 网络,可以让 CPU 和 GPU 分别走不同的网络通道,具备更大的网络吞吐和更强隔离性,在支持高速网络的同时用户也能够通过 GDR 技术加速 GPU 卡间通信,进一步地提高集群计算效率。
针对 AI 计算,尤其是大模型训练场景,涉及多机多卡通信以及对并行文件存储的高速读写,这些操作对 GPU 卡间通信和高性能存储访问都有较高性能要求。我们的专有 RDMA 网卡实例支持同时挂载弹性 RDMA 网卡,让专有 RDMA 网卡负责 GPU 卡间通信,弹性 RDMA 网卡负责高性能存储的通信,同时保证两种流量的高吞吐和相互隔离,让整个计算过程不出现网络性能瓶颈。
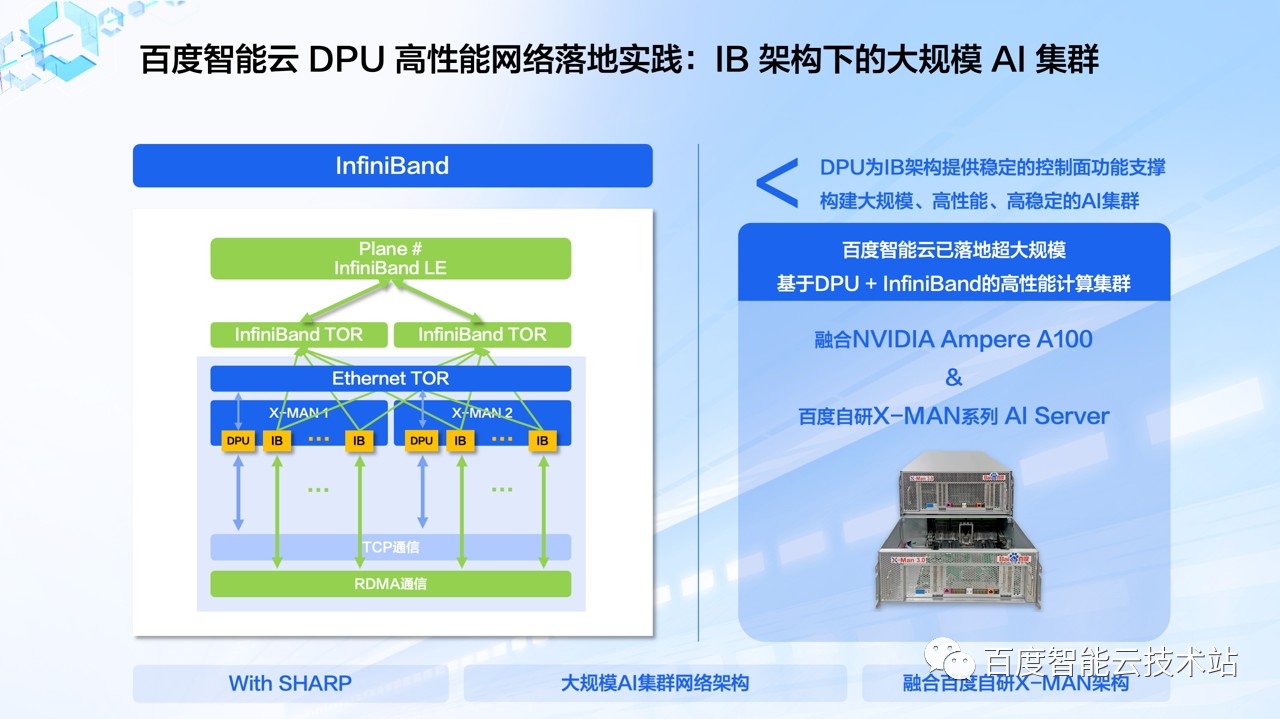
除了对 RoCEv2 协议的 RDMA 网络支持之外,百度智能云也推出了支持 IB 协议 RDMA 网络的 AI 集群实例,支持 800Gbps 的 RDMA 网络带宽和 200Gbps 的 VPC 网络带宽接入,满足 AI 和 HPC 大规模集群运算的场景。
基于 IB 协议的高性能计算集群,在超大规模的计算集群场景下能够实现更好网络性能保障,独有的 SHARP 等技术也让 IB 架构在高性能计算场景优势得到进一步发挥。
结合了百度自研的 X-MAN 超级 AI 计算机、DPU 和 IB 高速网络的计算实例在百度内部的文心大模型训练中都已经有大规模应用。
对于 RDMA 多协议生态的全面拥抱,让百度智能云在高性能计算和高性能网络方面有着非常丰富的产品布局。
基于弹性 RDMA 网卡方案的云服务器 BCC 已经支持了 200Gbps 网络带宽和 5 微秒级通信时延的 RDMA 网络增强型实例和 AI 训练型实例;专用 RDMA 网卡方案方面,在弹性高性能计算集群 EHC 上提供了加载 NVIDIA 英伟达安培架构 GPU 卡的高性能计算实例,支持 RoCEv2 和 IB 两种网络协议类型。
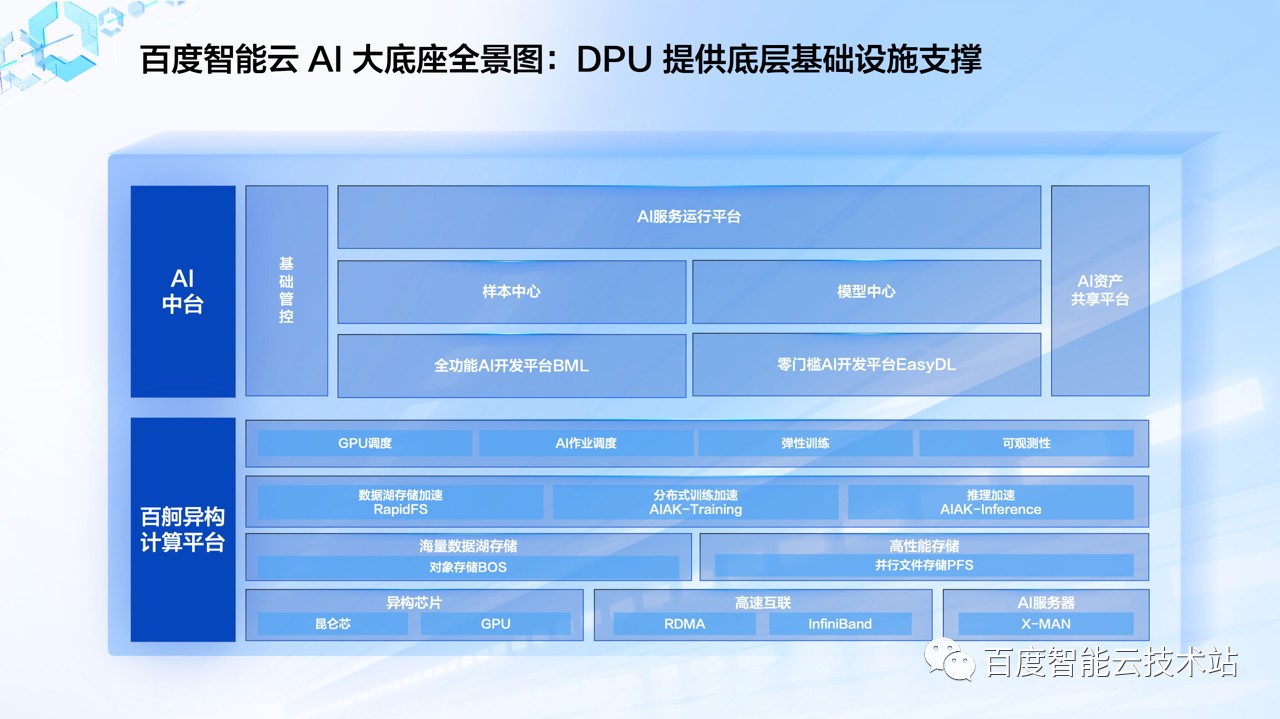
基于百度在 AI 领域的多年项目积累和技术沉淀,百度智能云在 22 年底推出了 AI 大底座,满足大模型时代社会和产业对于智能服务的需求。
AI 大底座包含了两大 AI 工程平台:「AI 中台」和「百度百舸· AI 异构计算平台」,分别在开发和资源层面进行提效。「AI 大底座」对各层的技术栈进行了全栈融合、系统优化,完成了云和智的技术一体化建设,可以实现对大模型训练的端到端优化和加速。
百度太行·计算基于 DPU 构建的高性能IaaS 计算架构,以及推出的高性能计算实例为 AI 大底座提供了大规模、高弹性、高稳定的算力支撑。
展望未来,我们将同 NVIDIA 英伟达携手持续在包括 DPU 以及 Connect-X 系列的产品上做出更多的探索,丰富百度智能云产品能力,增强对于新算力要求下客户工作负载的满足程度。
在网络方面,不管是 NVIDIA 英伟达的 BF3,还是百度智能云的自研太行 DPU,未来都会进一步优化网络吞吐性能,提升数据处理能力,并且融合计算、网络等方面的可编程性;
在存储方面,对于块存储、文件存储、对象存储及 NVMe 存储的仿真,在数据落盘时对加解密操作的硬件卸载,包括签名操作等都可以去分流到 DPU 上去支持;
在安全方面,我们希望帮助客户构建零信任的安全环境,包括 TLS、IPSec 等协议都需要在 DPU 中支持;
在管理层面,我们会支持 Hierarchy QoS,增加多层调度,实现流量更精细化的管理。除了 DPU,在普通网卡例如 CX7 等,我们也将具备更高速率、更大规模的 RoCE 或者 IB 网络支持能力。


发表评论
登录后可评论,请前往 登录 或 注册