Doris 实现原理之高效存取 varchar 字符串
2024.05.21 20:08浏览量:885简介:Doris 存储层设计有点复杂,怎么存数据,怎么建索引,索引怎么生效的,本文告诉您解决方案!
Doris 存储层设计有点复杂,怎么存数据,怎么建索引,索引怎么生效的,直接看代码有点废脑,笔者花了不少时间看这部分的代码,为了便于理解, 本文尝试一个案例尽可能的把相关知识点串起来,选择字符串来作为切入点去了解存储引擎主要是字符串涉及的内容比较多,比较复杂,也比较全面。万丈高楼平地起,复杂的事情往往要从简单东西开始分析,我们先建一个表,同时为理解索引怎么存储的,添加 2 个索引布隆过滤器索引和 bitmap 索引,建表语句如下:
# 一个user表,包含2个字段名称和年龄
CREATE TABLE t_user (
username varchar(20) NULL,
age int
) ENGINE=OLAP
# 指定排序的key
DUPLICATE KEY(username)
COMMENT 'OLAP'
DISTRIBUTED BY HASH(username) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1",
"bloom_filter_columns"="username" # 添加布隆过滤索引
);
# 添加
CREATE INDEX bitmap_index ON t_user (username) USING BITMAP COMMENT 'test for bitmap';`
随后我们插入 6 条数据:
MySQL [test_db]> insert into t_user values(“u2”,10),(“u4”,20),(“u1”,30),(“u3”,13),(NULL,0),(“u4”,”12”)
MySQL [test_db]> select * from t_user;
+----------+------+
| username | age |
+----------+------+
| NULL | 0 |
| u1 | 30 |
| u2 | 10 |
| u3 | 13 |
| u4 | 12 |
| u4 | 20 |
+----------+------+
6 rows in set (0.17 sec)
可以看到我们的插入的 username 无序的,但查出来是有序,因为在 Doris 中同一批数据导入时会自动按照我们定义的 key 排序。
实现行号读取我们知道 Doris 是列存结构,因为分析场景主要是对某列进行聚合操作,按列加载数据可以降低 io 计算效率更高,所谓列存就是把同一列的数据存储拼在一起存储在文件中,所以上面 username 字段列存格式如下:
但是直接存起来显然还不行因为没法读取,不知道有多少行,每行从那里读,读多少长度,经过思考你想到了在后面追加一些额外的信息,增加了每个元素的 offset、总个数、总长度,我们把这种编方式称为 plain 编码,意思是直接打平。
其中每个红色数字占 4 个字节,对应的含义是:
- 14:表示数据部分占有 14 个字节
- 6 :表示有 6 个元素
- 12:表示第 6 个 value 的 offset 的是 12
- 10:表示第 5 个 value 的 offset 的是 10
- 8 :表示第 4 个 value 的 offset 是 8
- 6 :表示第 3 个 value 的 offset 是 6
- 4 :表示第 2 个 value 的 offset 是 4
- 0 :表示第 1 个 value 的 offset 是 0
然后每个 value 的长度 = 下一个 value 的 offset- 当前 value 的 offset,所以得到每个 value 的在文件位置信息 offset 和 len。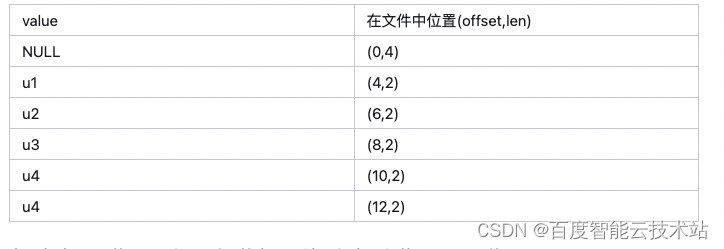
有了每个 value 的 offset 和 len 后,就实现了读取任意一行的 username 值 。
NULL 值存储上面一列中有 NULL 值,这个 NULL 是以字符串的方式存储下来,占比 4 个字节,这种设计并不是合理,空间浪费而且如果要真存 “NULL” 字符串时会有冲突, 所以业内标准的做法是采用标记法,不存储,具体的实现就是通过维护一个 nullbitmap 来标记哪个值为空哪个值不为空,用 body 来表示存储的数据,引入 nullbitmap 后存储结构变为: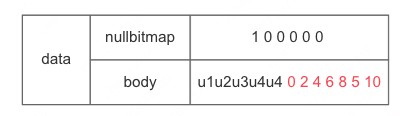
其中:
nullbitmap:占用 1 个字节,因为只有 6 个元素,6 个 bit 就够了,第一个元素值为 null,所以第一个 bit 为 1
body:只存储 5 个元素,还是沿用打平编码,红色部分每个值占 4 个字节
引入 nullbitmap 后我们会发现一个问题,由于 null 值不存储后, body 元素的所在的位置跟行号对不上了,比如 body 的元素值 u1 对应是应该是第二行,但在 body 中位置第 1 个,为了还是能实现根据进行号读取值,需要对行号跟元素的 offset 关系进行修正。
offset = 行号 - skipnullbits (前面有几个 null 值)
比如要读第 2 行的值,首先定位到 nullbitmap 第 2 个 bit,统计前面有几个 1,这里为 1 个 1,那么对应 body 中的元素位置为 2-1=1,即 body 中的第一个元素, offset = 0, len=2。
空值存储
上面讲了 null 值,那么空值怎么处理呢,其实空值可以看做是一个长度为 0 的值,前面提到字符串的长度=后一个元素 offset- 前一个元素的 offset,如果前后两个 offset 一样得到的长度就是 0,从而实现空值的存储,比如:插入 1 个空值后 insert into t_user values(“”,15),存储结构:
读取第 2 行过程:
- 定位到 nullbitmap 第 2 个 bit,统计前面有 1 个 1,即有 1 个 null 值,对应 body 中第一个元素
- 计算 body 中第一个元素的 len=offset[1]-offset[0]=0-0,判断为空值。
拆分
为了提升读取的效率, 读取的时候需要把文件中全部数据加载到内存,然后把每个 value 的 offset 还原出来,现在只存了 7 个值,如果有 70 亿个,这种处理方式是不行的, 本质问题还是存储的粒度过粗,不能把一列的所有数据放一起直接存储,这样没办法按需加载,所以自然想到进行拆分,拆分为多组,我们把每一组称为一页
为了叙述方便,假设后每一页的大小仅能容纳 3 个值(实际 1 页大小默认 64KB ),则上面数据需要分 2 组,页作为基本单位存放内容,每页存储数据如下: page1 存放 NULLu1u2 page2 存放 u3u4u4。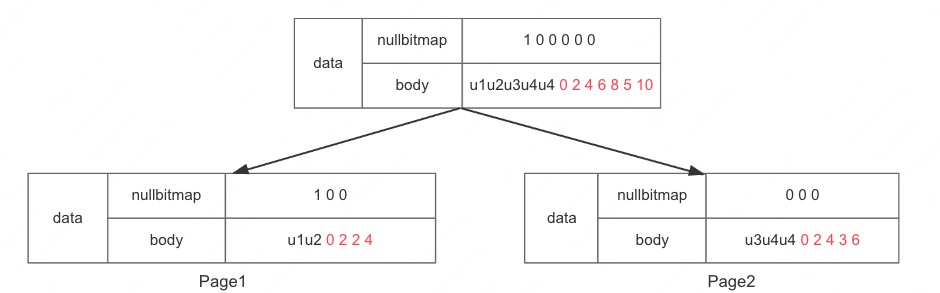
当然还需要知道每个 value 对应原来是第几行,所以每页还需要保存第一个值的行号(行号从 0 开始),当然除了行号还有额外的信息需要保存,关于页的描述信息我们统称为 Pagefooter,加上 footer 后结构如下: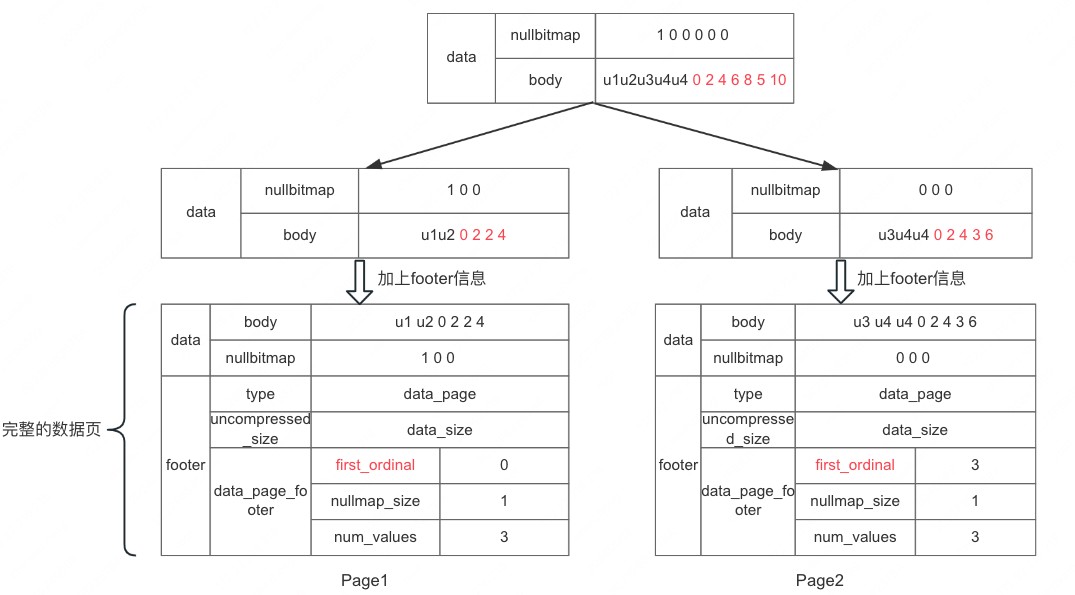
footer 字段说明:
- type:页类型,包括数据页和索引页,不同的页类型的有不同的 footer 信息
- uncompressed_size: 记录 data 写盘前未压缩的大小,读时候如果从磁盘读取的 data 大小和这个值不一样则说明进行了压缩,读取时需要进行解压
- data_page_footer: 对应 type 为数据页
- first_ordinal: 当前页第一个元素开始的行号(从 0 开始算)
- num_values: 元素个数
页地址
page1,page2 写到磁盘文件后会记录一个位置,这个位置在 Doris 中称为 PagePointer,读取的时候需要拿到 pointer 就可以读取整个 page,PagePointer 有 2 个属性:
struct PagePointer {
// 在文件的offset
uint64_t offset;
// page大小
uint32_t size;
}
序号索引到这里实现了分页存储,要找某一个值首先需要找到 page,然后在 page 中进一步读取,那么怎么知道每一行在哪个 page 呢?
为了实现行号能快速定位到 page,需要保存行号跟 PagePointer 的对应关系,这种关系称为序号索引,在 Doris 中叫做 OrdinalIndex,OrdinalIndex 只有 1 页: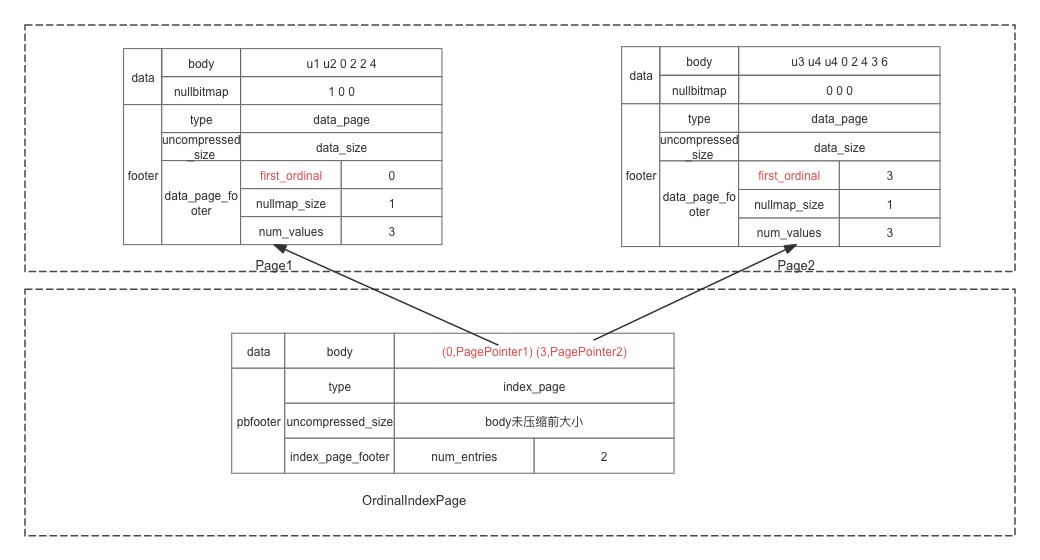
ordinalindexpage 页的 footer 字段说明:
- type: index_page 表示这是索引页;
- uncompressed_size: body 为压缩前的大小,如果读取后的大小跟这个值不一样则说明写时进行了压缩,需要解压;
- index_page_footer: 索引页对应的 footer 信息;
- num_entries: 记录了多少个 page。
有了 OrdinalIndex 后假设找 4 行的过程是怎么样的? 主要经过以下 4 个步骤:
- 行号定位 page:在 ordinalindexpage 中通过二分查找,找到 PagePointer2 ;
- 计算 page 中行号:page2 的 first_ordernal 为 3,第 4 行对应 page2 中的第一个元素;
- page 行号得到 offset 和 len:跟进 body 的 offset 信息,得到第一个元素的 offset 和 length;读
- 取内容:跟进 offset 和 length 从 body 中读取内容。
到此我们了解了分页后怎么根据行号找到任意一个值,OrdinalIndex 是一个非常重要的索引,提供任意行号定位到 page 能力,读取列数据都要经过 Ordinalindex 索引。
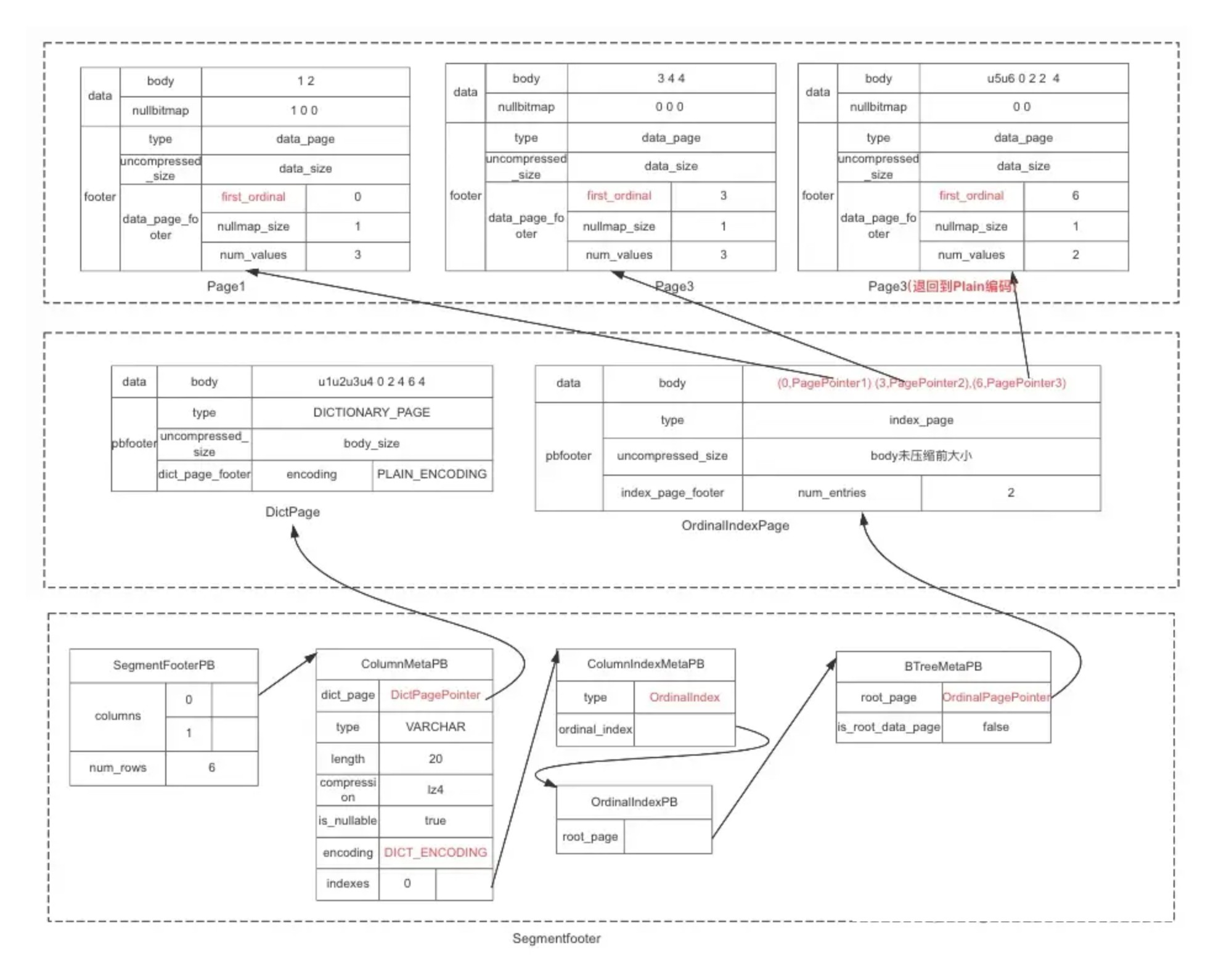
SegmentFooter
那么怎么找到每一列的 OrdinalIndex 呢? OrdinalIndex 也是需要存到数据文件中的,OrdinalIndex 写到文件后,也会有一个 pagepointer,需要把 pagepointer 保存起来,这个信息会保存在会数据文件的 SegmentFooter 信息里面,通过 SegmentFoote 可以找到每个字段 meta 信息,包括类型、编码、索引等等, footer 数据结构有点复杂,如图所示: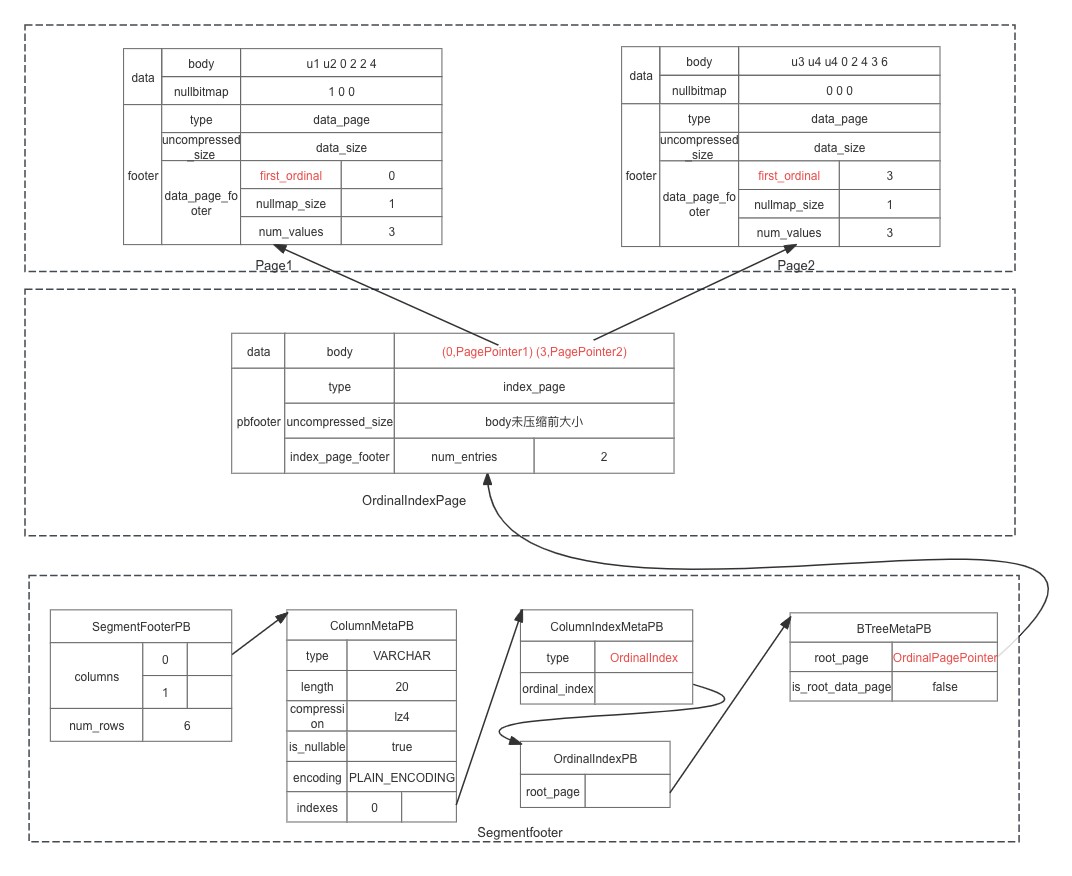
图中有 3 个虚线表示的框,代表一个数据文件的 3 个不同的区域, 从上到下,分别是数据区、索引区、footer 区。下面区域生成时字段的信息依赖上面区域的数据, 位置不能反,footer 区的结构都是 PB 的格式,索引区和数据区的 footer 部分也是 PB 格式,body 部分和 nullbitmap 部分有自己的编码和解码格式
SegmentFooterPB 最终会序列化后保存在数据文件的末尾格式如下,格式如下:
其中 magiccode 为一个固定字符串,用来标记是一个 Doris 是数据文件,字符串默认是” D0R1 “,占 4 个字节
到此我们再总结下 Doris 从文件中读根据某个字段过程
- 读取文件尾部 4 个字节,识别是 Segment 文件;
- 读取 4 个字节的 pbchecksum;
- 读取 4 个字节的 PBlength,得到 Segmentfooter 序列化的长度;
- 读取 serializeedSegmentFooterPB 内容,checksum 校验通过后,反序列化得到 SegmentFooterPB;
- 根据 SegmentFooterPB 得到对应字段的 ColumnMetaPB;
- 根据 ColumnMetaPB 进一步得到 ordinalindex,有了 ordinalindex,进而可以读取任意一行数据。
为了加深理解,可以思考下假设读取第 3 行的需要几次 io 操作?
字典编码
上面数据中我们注意到了字符串 u4 有 2 行的,在 page2 中存了两份,如果有 100w 行都是相同的,那么按照目前这种打平编码存储,就得存 100w 个相同值,存储利用率不高, 为了解决这个问题,引入了字典编码,通过给字符串指定编号,这个编号是一个 int 类型,从 0 开始自增,0 表示空字符串,数据页只需要存储对应的编号,来减少存储的空间,这个字典存在单独存在字典页中,字典页在存储的时候用的页是 plain 编码。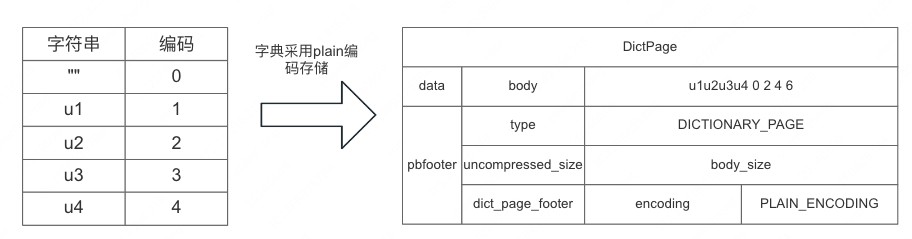
有了字典编码后,Page1、Page2 中存储的内容实际是编码后的结果,字段的 meta 信息 columMetaPB 里面指定了编码格式,同时也记录了字典编码页保存的位置。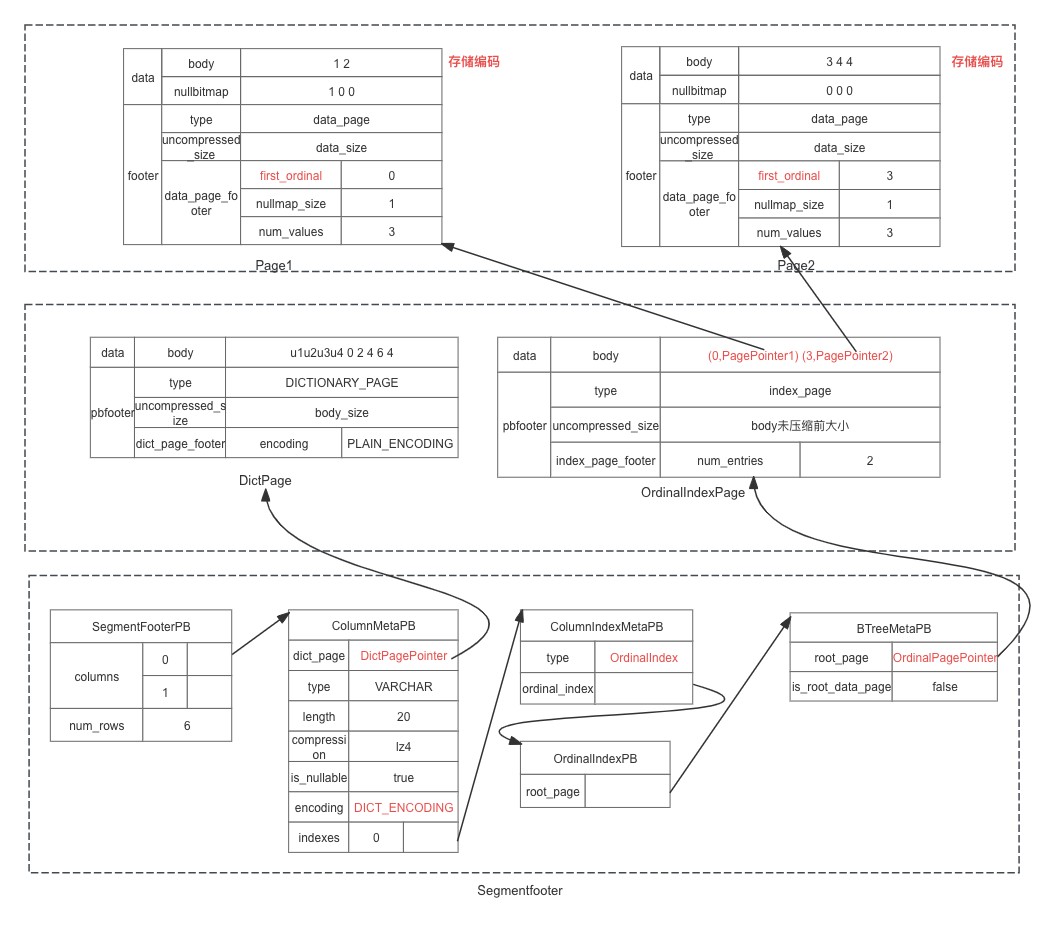
到这里解决了重复字符串的优化存储,但同时引入了一个新问题,字典编码只适合重复度比较高的,如果字符串本身无重复或者重复度很低,就达不到减少存储空间的目的,因为字典本身也是要存到磁盘,而且可能会影响性能 , 因为打平编码的时候只需要读取一页,字典编码则需要读取两页才能获取到值,所以怎么到底如何选择用哪种编码就称成为了不得不思考的问题?
Doris 采用的是试探法,优先先采用字典编码,随着数据增加, 如果字典大小超过一定的阈值退回 plan 编码,目前这个阈值是 dict_page 大小超过 64KB,我们看看有了这个退回机制后,数据是怎么存储的, 假设我们开始开插入的是 6 行数据,一开始采用字典编码,插入到第 6 行的时候字典满了,则 7、8 两行退回采用 plain 编码,之后也采用 plain 编码,如:
-> insert into t_user values("u5",15),("u6",20)
压缩 &bitshuffle
到这里我们知道了字符串在 Doris 内部是怎么存储的,先优先走字典编码,如果字典满了就回退了为 plain 编码,自适应比较完美了解决高基数和低基数场景下的存储效率问题,接下来讨论下怎么能高效的压缩进一步降低存储的空间。
高效压缩、进一步降低存储空间这个问题没有什么悬念,上压缩,直接将每个 Page 的 body 数据部分进行压缩然后再存储,Doris 支持的压缩算法有 5 种,lz4/lz4F/zlib/zstd/snppy,默认为 lz4,可以在建表的时候指定。
如果对 lz4 算法熟悉就清楚该算法原理是判断当前的字段与之前是否重复,如果有,则保存重复字段之间的距离(offset)和重复长度(length),以此替代重复字段,从而达到压缩数据的效果,也就是相邻的字符串重复度越高压缩效率越好。
简单举例如下(详细的压缩流程和数据结构可以自行搜索):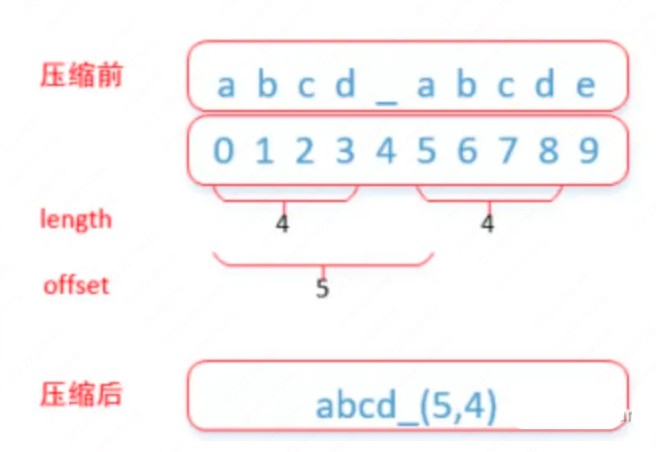
对于数字怎么进一步优化呢?数字前后可能都较少重复,直接使用 lz4 可能效果不太好。Doris 引入 Bitshuffle 算法来对数字按照 bit 重新进行打散排序,该算法的原理是: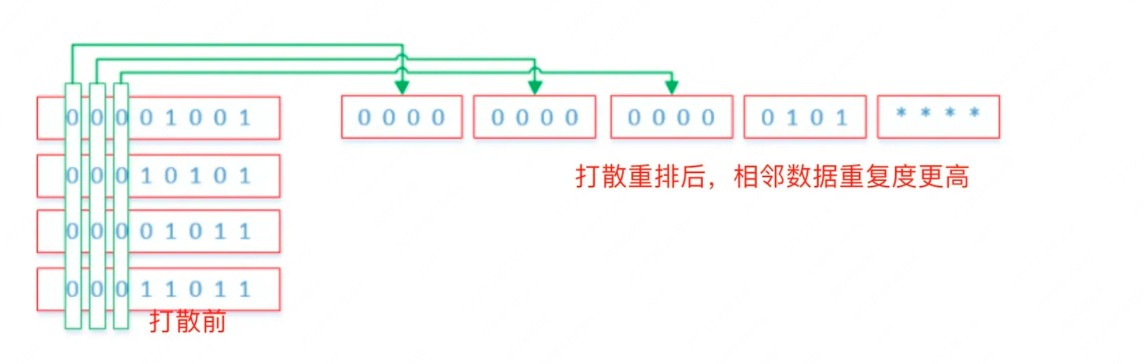
Bitshuffle 重新排列一组值以存储每个值的最高有效位,其次是每个值的第二个最高有效位,依此类推。
Bitshuffle 本身并不压缩数据,而只是重新排列以提高压缩效率,实际的压缩是通过另外的压缩算法来执行的,由于 Bitshuffle 的设计与 lz4 压缩算法匹配,因此,在使用 Bitshuffle 后,用 lz4 对每个数据块进行压缩,加上压缩后存储意图。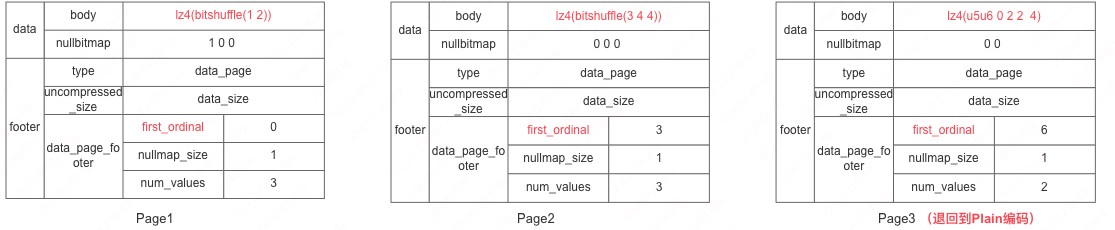
到此 Doris 怎么存储字符串,怎么高效的压缩介绍就结束了,我们来总结下:
- 列式分页存储,NULL 值用 Bitmap 来标记
- OrdinalIndex 记录每个分页的位置
- 页内采用 plain 编码或者字典编码
- 字典编码时,会结合 Bitsshuffle 来提升压缩效率
接下来会重点介绍下怎么提升查询效率,也就是怎么实现各种类型的索引。
读数据流程
从上面介绍,我们知道 Doris 内部维护了一个行号,这个行号对用户是不可见的,主要用于读数据方便,每个独立存储的列可以用行号串起来,读取的时候,首先生成会生成一个 row_bitmap,代表本次要读取的行集合,有了这个集合就可以根据 OrdinalIndex 把数据读上来
row_bitmap 初始大小为 SegmentFooterPB.num_rows, 前面 num_rows 为 8,则 row_bitmap 为 8 个 bit,1 表示对应位置要读取,为 0 表示不读取 ,初始时都为 1,表示都要读取。
索引过滤
索引目的就是根据条件快速找到需要读取行或者过滤掉不需要读取的行,然后不需要行读取在 row_bitmap 对应的位置设置为 0。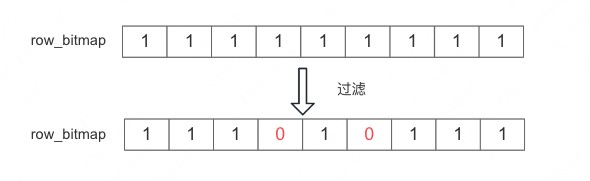
前缀索引
前面我们看到 Doris 在存储时会先把所有行按照指定 key 字段进行排序,然后存储、 key 字段可以是 1 个字段或者多个字段,前缀索引在实现上就是基于排序的行,每间隔固定行记录下 key 和行号的对应关系,假设固定行数为 3,则前缀索引结构如下图: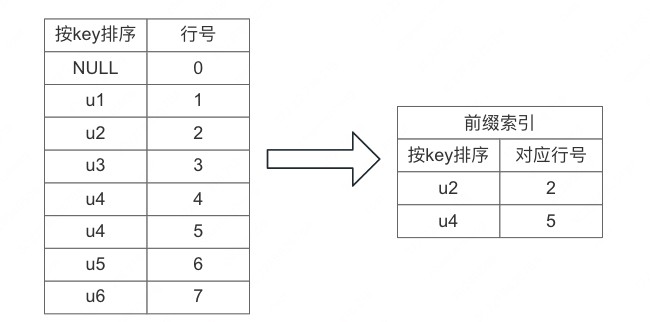
可以看到前缀索引相比原来减少了很多行数,变得更为稀疏,所以前缀索引也可以叫稀疏索引。
那么,索引怎么存储呢? Doris 有一个单独页来保存前缀索引,页 footer 记录了间隔的行数,结构如下图: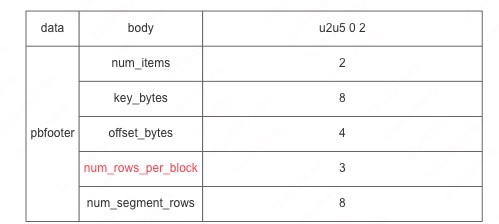
前缀索引不是某个字段独有,作用范围是整个 Segment,所以页的地址记录在 Segmentfooter 里面,如下图: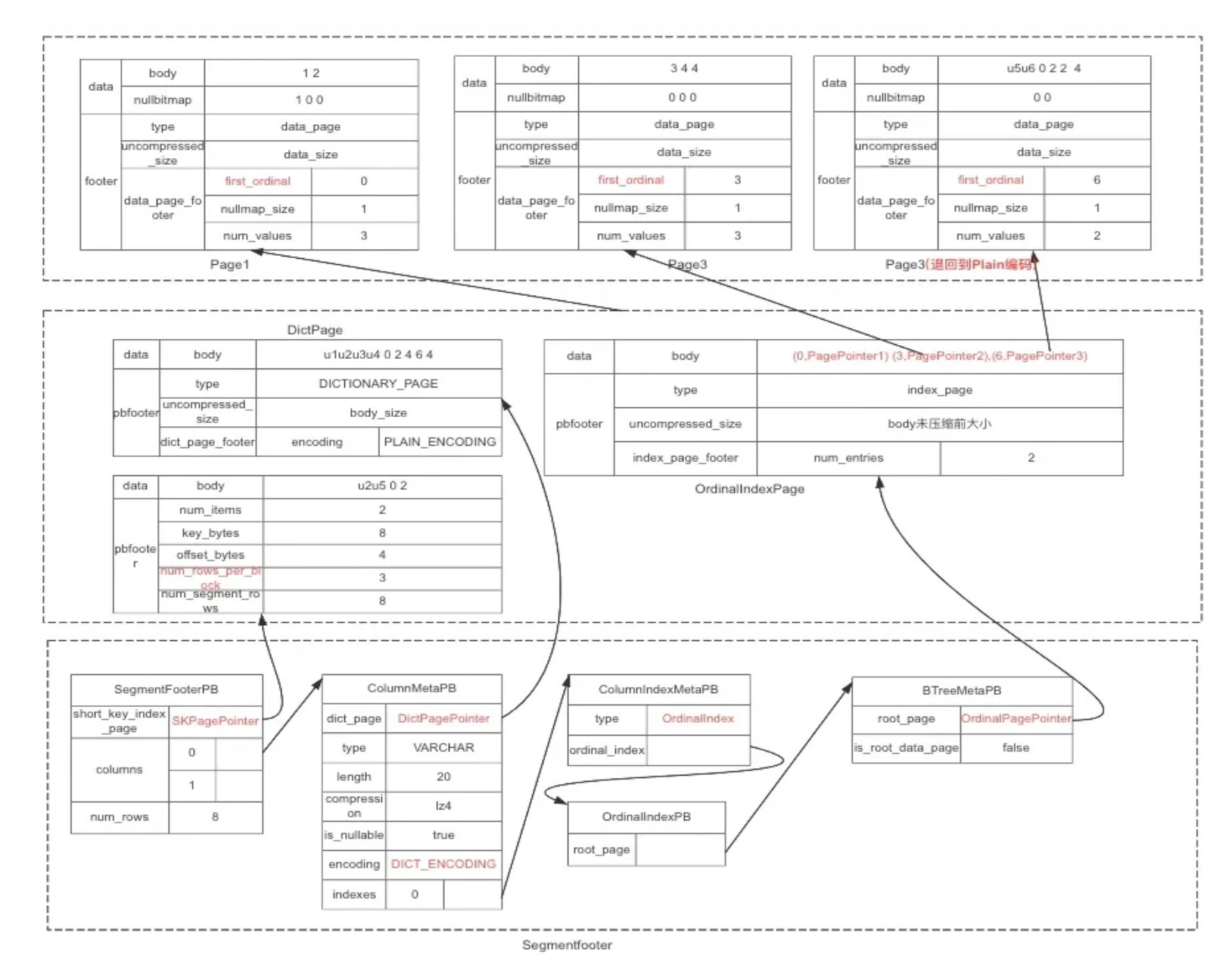
有了前缀索引后,我们看下是怎么过滤的,假设有条 SQL:
select username from t_user where username="u3"
首先发现 username 是 key 列,先查询前缀索引 (SegmentFooterPB->short_key_index_page->body),通过二分查找发现 u3 在 u2 与 u4 之间,通过 num_rows_per_block 计算出 u2 对应的行号是 3,u4 对应的行号是 5,那么 u3 对应的行号范围应该在 [3-5],把这个范围合并到 row_bitmap 中,原来要查 8 行的,现在查 3 行就可以完成。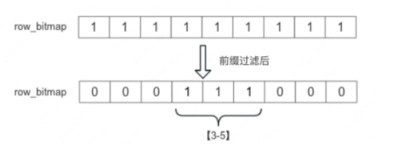
当然前缀索引不仅仅能进行等值过滤,非等于过滤也是支持,原理跟等值的一样,都是基于 key 有序来缩小查找范围。
前缀索引虽然过滤效果不错,但是只能用于有 key 列作为查询条件且顺序符合匹配要求时才能生效,如果查询条件是非 key 列怎么加速呢?
ZoneMap 索引
为了加速在页内的查找效率, 写入时会收集每个页的关键信息,比如是否有 NULL 值,最大值和最小值分别是什么,基于这些信息起到快速过滤页的作用,关键信息称为 zonemap 索引,除了每个页会有一个 zonemap 索引,同时也会维护每个列的 segment 粒度 zonemap 索引,起到快速过滤 segment 文件的作用。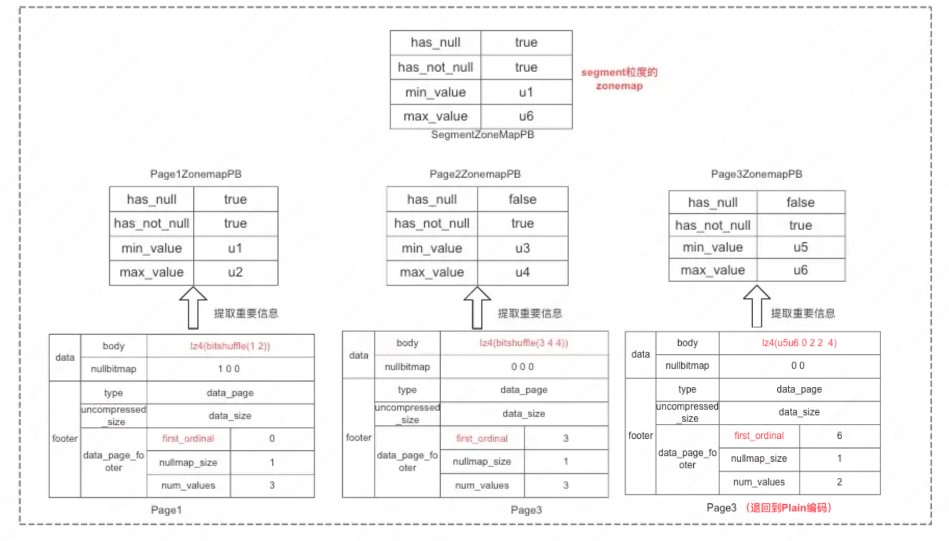
zonemap 信息怎么存储的,每一个 zonemap 是 pb 格式,序列化后作为字符串存储,页级别 zonemap 信息存储复用了字符串分页存储的逻辑,采用 plain 编码,segment 的 zonemap 信息直接保存在 segmentfooter 的元信息里。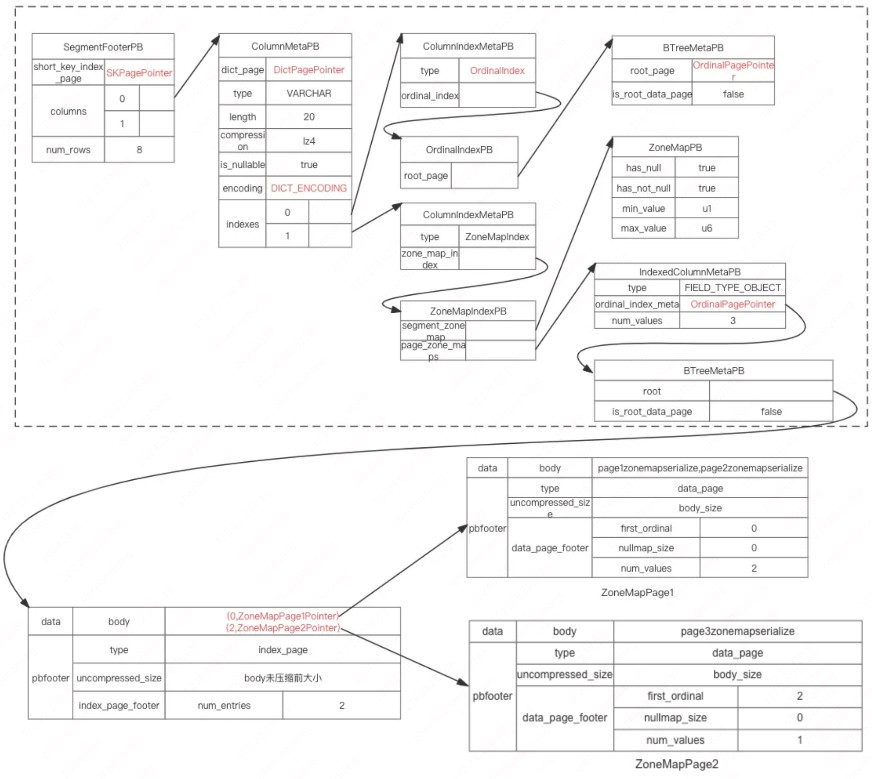
有了 zonemap,我们再看下过滤的过程是怎么样的,假设有如下 SQL:
1、select * from username where username is null
2、select * from username wehre username="u4"
3、select * from username wehre username="u8"
对于 SQL1,首先拿到 segment 粒度的 zonemap (路径: ColumnMetaPB.indexs[1].zone_map_index.segment_zonemap),取 has_null 字段,为 true 说明这个 segment 的 username 字段存在为 null 的行,需要进行读取, 然后进一步确定哪些 page 存在 null,根据 page_zone_maps.ordinal_index_meta 找到并遍历所有 zonemappages 里的每个元素,反序列化,找 hash_null=true 的元素,发现只有元素 page1zonemapseralize 结果符合要求,这个元素对应 zonemappages 编号为 0,也就是数据页第一页,然后计算得到第一页的行范围,怎么找到页对应的行的范围呢? 利用 ordinalindex,回顾下 ordinalindex 的内容:
里面记录了每个页的开始行号 first_ordinal,那么每页的行范围就是 =(当前页的 first_ordinal,下页的 first_ordinal-1)=(0,2) 把这个范围合并到 row_bitmap 中,最终读取 0、1、2 行,读上来之后再进行进一步过滤。
对于 SQL2,流程跟上面一样,不同的是根据 min、max 判断是否要读取 segment 或页,username=”u4” 确定只需要读取 page2,page2 对应的行范围是 (3,5),最终读取 3、4、5 行,读上来之后再进行进一步过滤;
对于 SQL3,流程跟上面一样,不同的是在 segment 粒度的 min、max 判断后发现 ma<u8,索引不需要读 segment,直接忽略,返回空。></u8,索引不需要读>
Bloom 过滤器
实际上 zonemap 索引的过滤效果对于字符串还是比较有限,不同的内容,min/max 的范围可能会比较大,导致能过滤的页有限,比如:就算是页内只有 a、z 两个元素,zonemap 的 min=a,max=z,那么查询 b、c、d、e、f 等时都不能过滤这个页,如果一个索引能直接告诉我们,这个值在不在该页内,不在则直接过滤,那么查询的效果会显著提升。bloom 过滤器就是来这个实现需求的。
doris 会为每个数据页生成 bloom 过滤器,当有等值的查询条件,可以快速过滤掉不需要的页,bloom 过滤器的原理网上比较多,这里就不做介绍。大家可以记住一个结论:给定输入 bloom 过滤器判断不存在那就肯定不存在,直接跳过这页; 如果判断存在那有可能存在,则这页需要保留。
bloomfilter 信息怎么存储的,序列化后作为字符串存储,跟 zonemap 一样存储复用了字符串分页存储的逻辑,采用 plain 编码,结构如下图: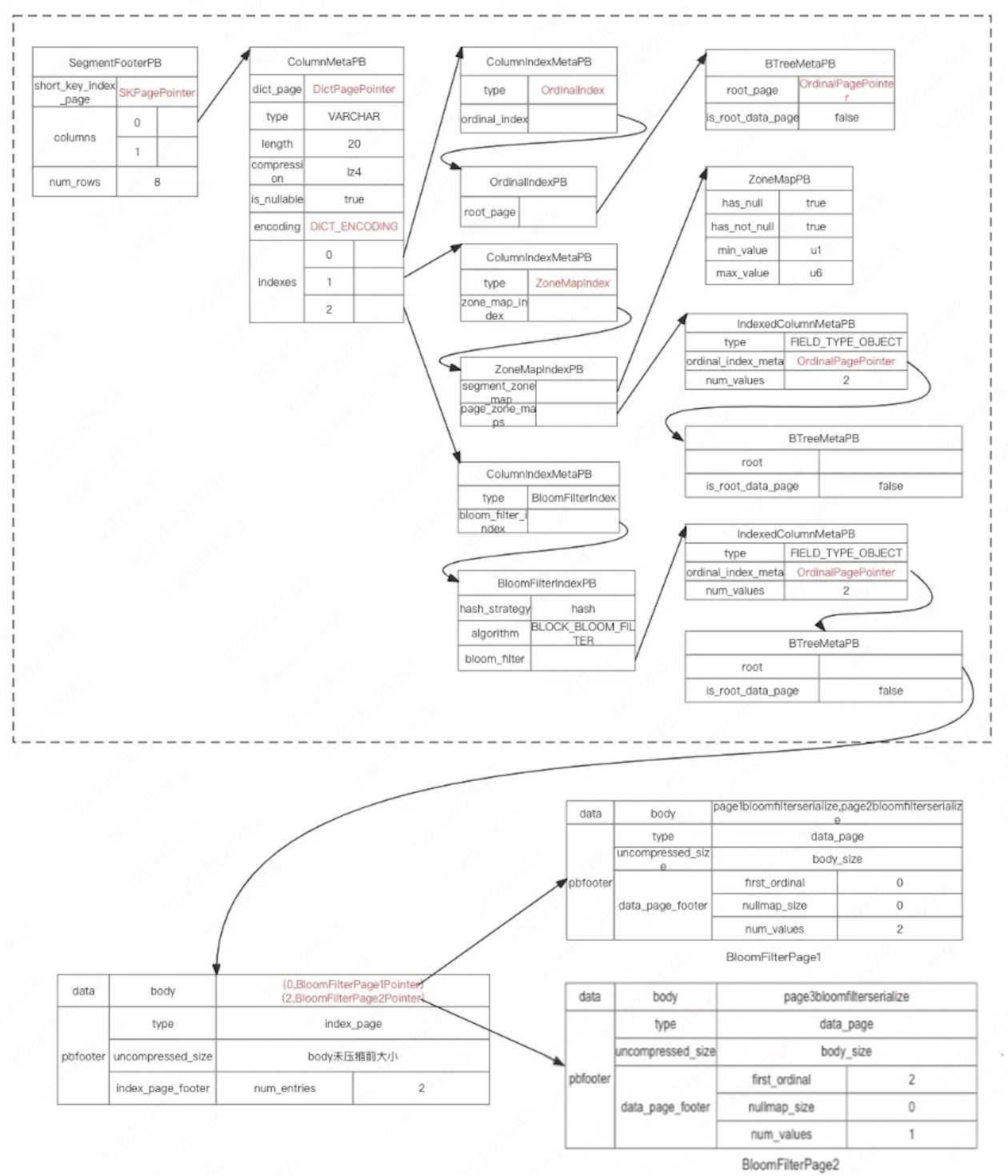
过滤流程跟 zonemap 差不多,这里就不在重复了, 遍历每个 pagebloomfilterserialze,反序列化后,进行判断过滤,如果判断不在,则跳过对应的页,判断在则把相关的页的编号转成对应的行号范围合并到 row_bitmap 中。
Bitmap 索引
不管是 zonemap,还是 bloomfilter 索引都是研究怎么更快的过滤不需要页的,不是精确到某一行,而 bitmap 索引是直接定位到行的索引,相比 zonemap、bloomfilter 效果会更好,bitmap 索引有个 map 表会记录每个 value 的对应的行号集合,行号集合是以 bitmap 方式存储的,这大概是叫 bitmap 索引原因,结构如下: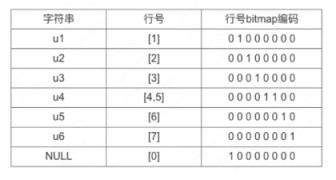
value 在 map 中是排好序的,这样做的目的是可以根据某个 value 可以通过二分法快速找到,实现索引从磁盘按需加载,map 表在存储的时候分 2 部分(字典部分和行号部分)。
字典部分和行号部分是分开存储的且都复用了前面的分页存储方式,区别是字典部分在保存页地址的时候记录是 page 的首个 value 和 pagepointer,行号部分用的记录是 first_oridnal 和 pagepointer。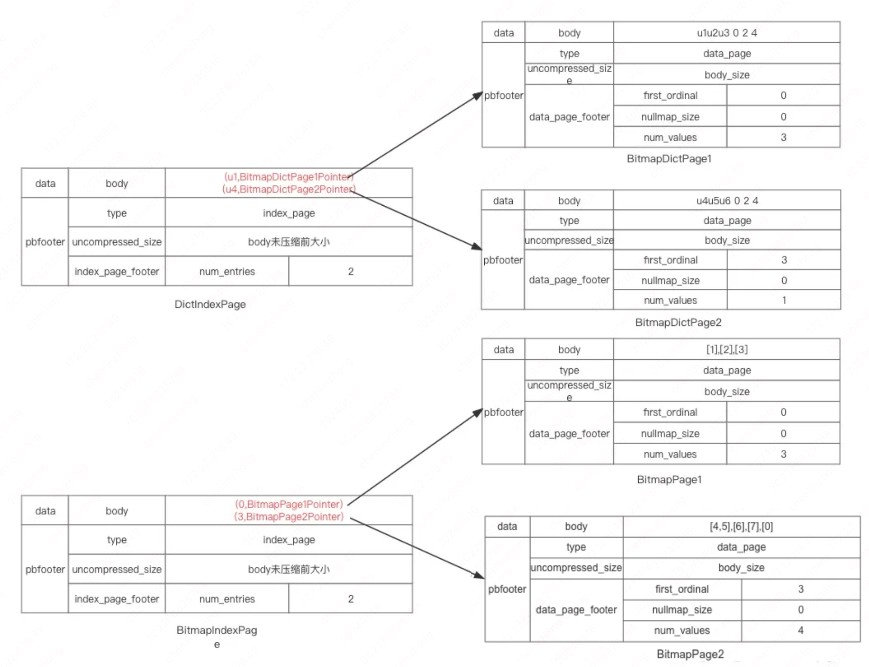
上面存的是 value, 下面存储的行号,NULL 对应的行号集合固定存储在末尾。假设有条 sql: select username from t_user where username=”u3” bitmap 索引过滤过程是怎么样?
- 在 DictIndexPage 中根据二分查找,发现 u3 在第 1 页 BitpageDictPage1 中
- 在 BitpageDictPage1 中再通过二分查找,发现是第 3 个元素,对应 BitmapIndexPage 第 3 个值
- 然后在 BitmapIndexPage 中根据二分查找第三个值,发现在第 1 页 BitmapPage1 中,取最后一个值[3]
- 然后把这个行号集合[3]合并到 row_bitmap 中
主键索引
开始给的例子,表 t_user 的模型是明细表,如果是 uniq 表,Doris 1.2 版本后,会根据主键建立主键索引,通过主键直接一步导致找到行号,这个主键索引主要用于实现 mow 功能,其存储结构跟前面 bitmap 索引的字典部分实现差不多,这里不在过多介绍。
全景图
为了有个更直观的认识,我们将上面提到存储结构整理成全景图,如果您对 Doris 的存储部分的源码感兴趣,按图索骥看代码会丝滑些。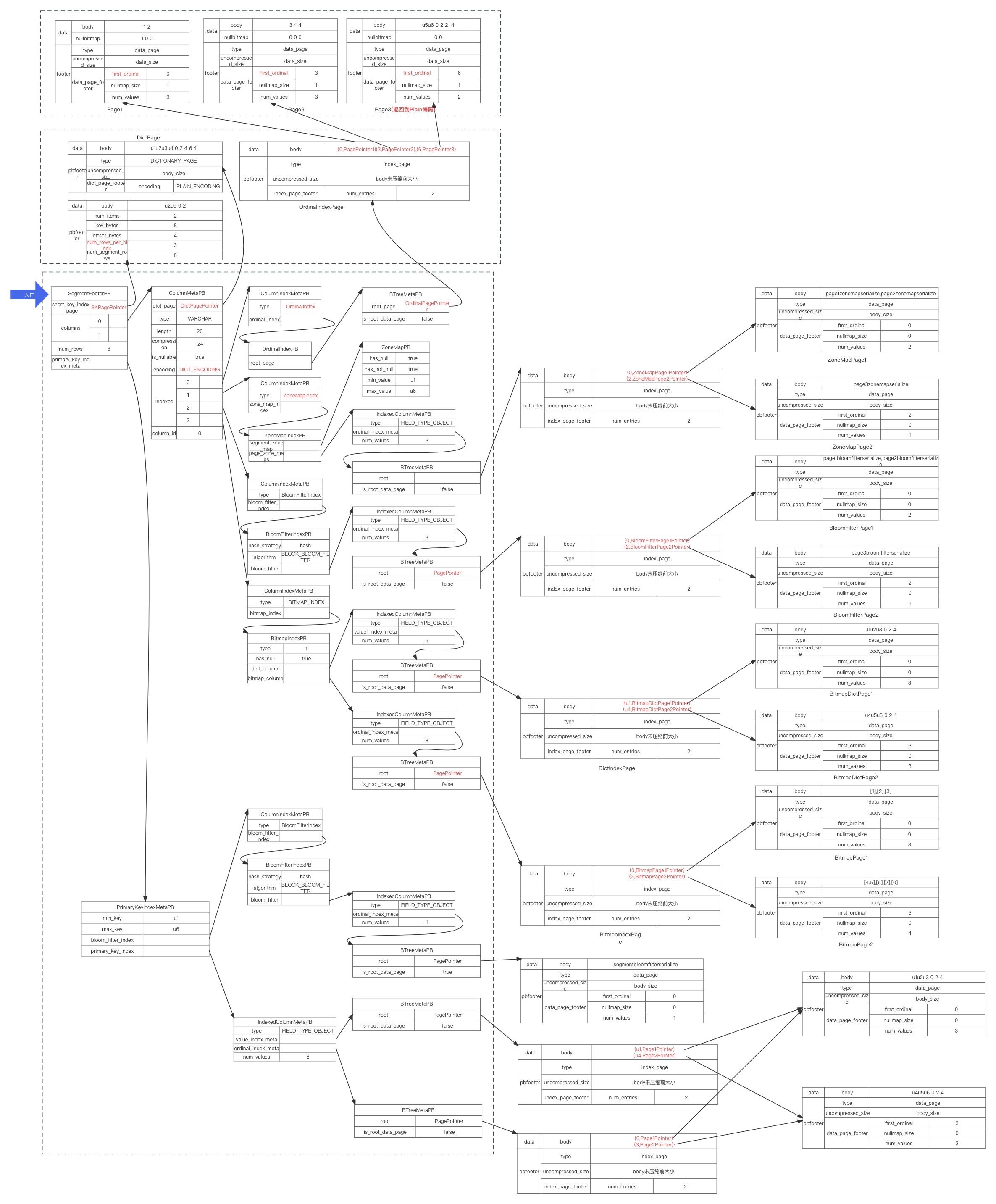
图有点模糊,上传后被压缩了,为了看得清晰,把原图上传一份了到了百度网盘,需要自取。
链接: https://pan.baidu.com/s/1-PlNo7I0sAY6u2aaSPmAQA
提取码: 2024
行读效率问题
笔者在看代码的时候一直有个疑问,Doris 的是根据行号读取的,感觉有些场景、效率会上不去,索引过滤后,中间存在空洞的,效率怎么保证的。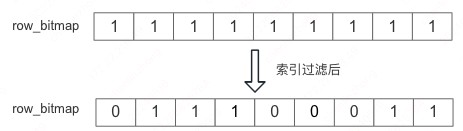
Doris 对应空洞情况做了优化,会进行分段读,每一段内的行是连续的,这样可以进行批量读取,从而提升效率。当然对于极端情况,每段只有 1 行,效率确实会不行,比如过滤后 row_bitmap 是如下图所示: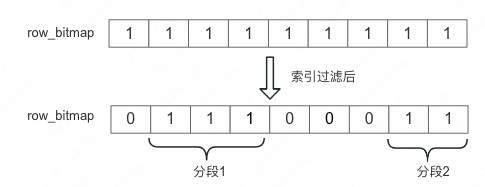
从实际的情况看,分段优化后 ,读取的效率性能较好。
总结
- 字符串采用列存,切分为不同的 page,page 是存储和读取的最小单位。
- 自适应识别高基数列和低基数列,低基数列采用字典编码,高基数列采用 plain 编码。
- 当采用字典编码,会结合 bitshuffle 算法来提升 lz4 压缩效率。
- segment 内部维护了一个行号,OrdinalIndex 记录了行号与 page 位置的关。
- segment 内部自动维护 2 个索引,前缀索引和 zonemap 索引。
- 用户可以额外的创建 bloomfilter 索引和 bitmap 索引,来加速查询。
以上内容基于 Doris-2.0 版本(commit-id:767b5a1770e33cf) 整理。

发表评论
登录后可评论,请前往 登录 或 注册