数据仓库 Palo 2.0 for Apache Doris 冷热分离原理分析
2024.10.12 11:01浏览量:8202简介:百度智能云数据仓库 Palo 是基于业内领先的 OLAP 数据库 Apache Doris 构建的
在数据分析的实际场景中,冷热数据往往面临着不同的查询频次及响应速度要求。例如在日志分析场景中,历史数据的访问频次很低,但需长时间备份以保证后续的审计和回溯的工作;在行为分析场景中,需支持近期流量数据的高频查询且时效性要求高,但为了保证历史数据随时可查,往往要求数据保存周期更为久远。
通常来说,历史数据的应用价值会随着时间推移而降低,且需要应对的查询需求也会随之锐减。而随着历史数据的不断增多,如果我们将所有数据存储在本地,将造成大量的资源浪费。
为了解决以上问题,冷热数据分层技术应运而生。顾名思义,冷热分离是将冷热数据分别存储在成本不同的存储介质上,这项技术目前被广泛用于各个数仓产品。百度智能云数据仓库 Palo 2.0 for Apache Doris 版本提供了冷热分层的功能,把部分冷数据放到对象存储中,以此实现成本效益的最大化。
百度智能云数据仓库 Palo 是基于业内领先的 OLAP 数据库 Apache Doris 构建的 MPP 架构云数据仓库,本文也将围绕「冷热分离功能的使用及实现原理」重点介绍。
1.如何使用冷热分离功能
1.1 主要步骤
添加远端存储:创建转冷策略表和绑定转冷策略。
#添加远端存储,使用对象存储的 Bucket 以及 AK/SK 创建 Resource。
CREATE EXTERNAL RESOURCE "baidu_bos_s3"
PROPERTIES
(
"type" = "s3",
"AWS_ENDPOINT" = "s3.bj.bcebos.com",
"AWS_REGION" = "bj",
"AWS_BUCKET" = "${BUCKET}",
"AWS_ROOT_PATH" = "/palo/storage",
"AWS_ACCESS_KEY" = "${AWS_ACCESS_KEY}",
"AWS_SECRET_KEY" = "${AWS_SECRET_KEY}",
"AWS_MAX_CONNECTIONS" = "50",
"AWS_REQUEST_TIMEOUT_MS" = "3000",
"AWS_CONNECTION_TIMEOUT_MS" = "3000"
);
#创建转冷策略
方式1:设置ttl时间 (推荐采用)
CREATE STORAGE POLICY testPolicy
PROPERTIES(
"storage_resource" = "baidu_bos_s3",
"cooldown_ttl" = "5"
);
方式2:设置固定的转冷时间
CREATE STORAGE POLICY testPolicy
PROPERTIES(
"storage_resource" = "baidu_bos_s3",
"cooldown_datetime" = "2023-06-07 21:00:00"
);
#策略绑定
方式1:整表绑定
CREATE TABLE TestTbl
(
aa BIGINT
)
ENGINE=olap
DISTRIBUTED BY HASH (aa) BUCKETS 1
PROPERTIES(
"replication_num" = "1",
"storage_policy" = "testPolicy"
);
方式2:指定分区绑定(推荐采用,每个分区可以采用不同的策略,控制更为灵活)
ALTER TABLE create_table_partition MODIFY PARTITION (*) SET("storage_policy"="test_policy");
插入数据:
insert into TestTbl values(1);
insert into TestTbl values(2);
insert into TestTbl values(3);
insert into TestTbl values(4);
insert into TestTbl values(5);
插入数据后在 BE 中产生 6 个数据文件:
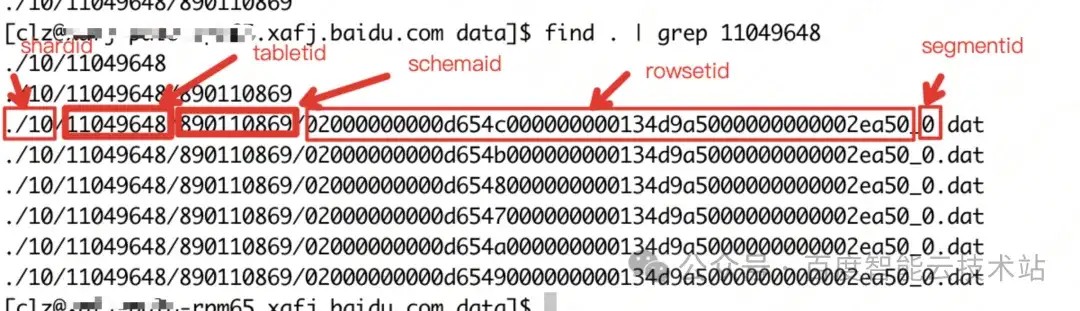
超过 ttl 时间数据会进行转冷,转冷时的关键日志:
执行:grep “Upload rowset” http://be.INFO

1.2 查看转冷情况
通过 show tablets from xxx 查看每个 tablet 的转冷大小:
- LocalDataSize: be 本地数据文件大小
- RemoteDataSize: 远端存储上数据文件大小
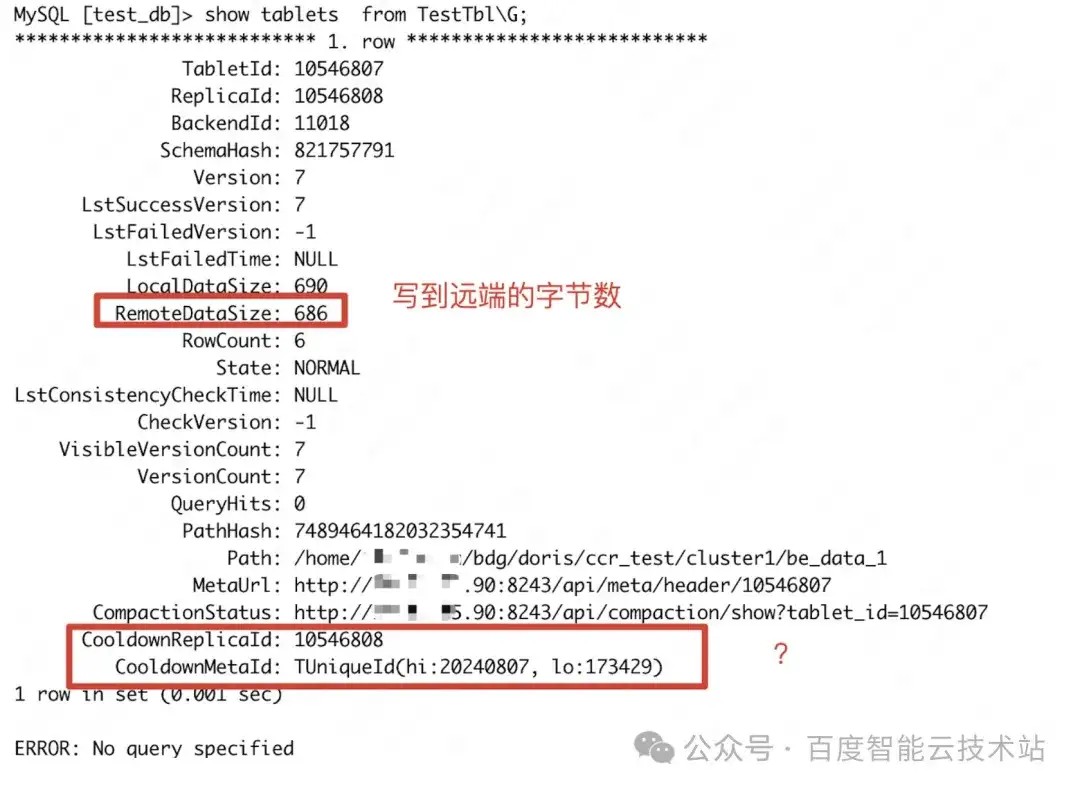
转冷后可以看到本地文件的数据被删除。
在对象存储 BOS 中的数据文件:
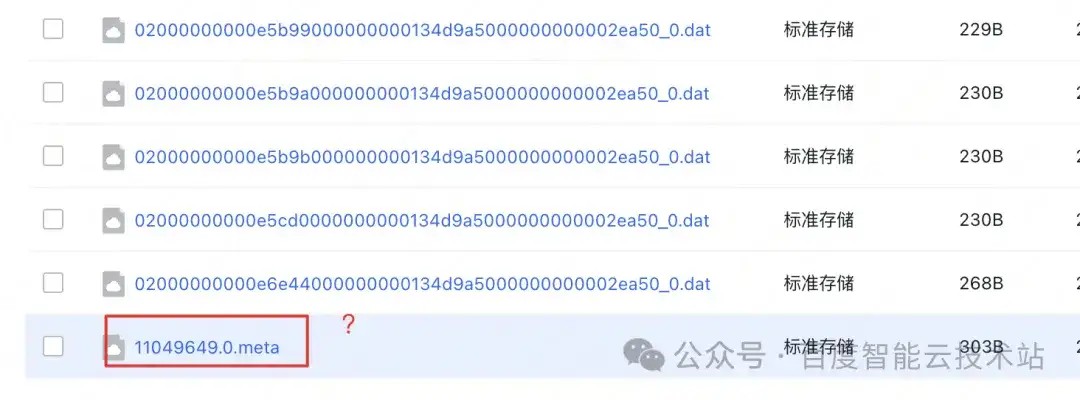
我们可以看到,当前增加了新的 meta 文件,这部分我们将在下文 4.3 小节详细介绍。
1.3 监控相关
为了更直观地观测冷热的有关行为、便于运维监控。Doris 提供了冷热 4 个监控指标,监控指标支持在 grafana 中配置。

1.4 开启 cache
添加参数到 BE 节点的配置文件 conf/be.conf 中,并重启 BE 节点让配置生效。

查看 BE 上所有的配置项: http://Host:HttpPort/varz
开启 File Cache 后,在 query profile 可以查看缓存的命中情况:
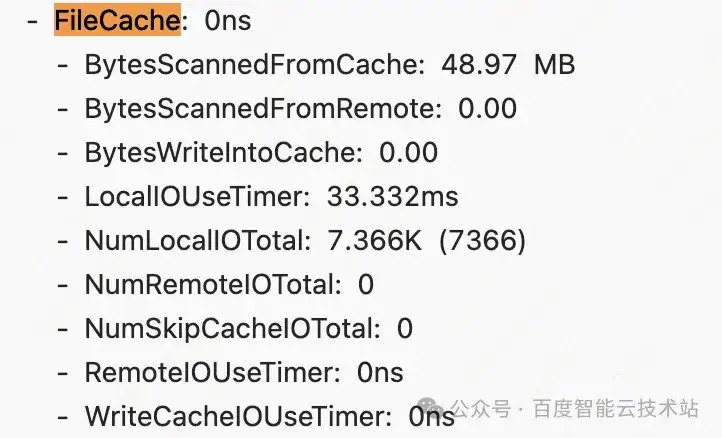
冷热分离功能在实现上主要涉及到 FE 和 BE 元数据的操作。为了更深入地理解冷热分离的原理,首先需要了解 FE 元数据和 BE 元数据之间的组织关系及相关概念。
2 FE 元数据
2.1 层级关系
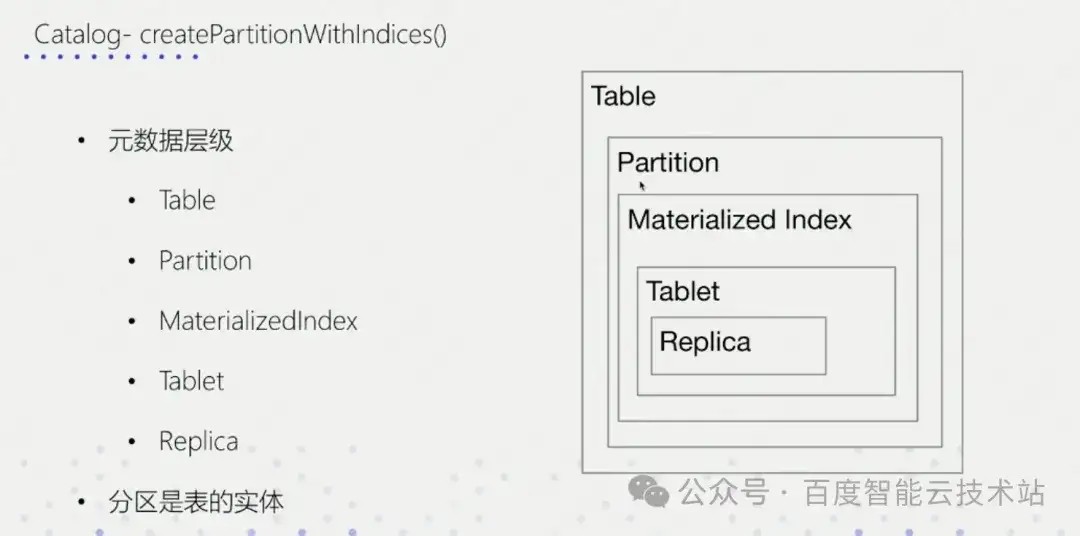
说明:
- Partition:分区,Doris 支持分区表,需要 partition;
- MaterializedIndex:物化索引,简单理解为 1 个 schema。比如一个 rollup 就是一个 MaterializedIndex;
- Tablet:数据分片,表数据的一部分;
- Replica:副本,分片所在的 BE。
为便于大家理解,下面将以简单表举例:
CREATE TABLE `TestTbl` (
`aa` BIGINT NULL,
`b` int
) ENGINE=OLAP
DUPLICATE KEY(`aa`)
PARTITION BY RANGE(`aa`)
(PARTITION p1 VALUES [("-9223372036854775808"), ("10")),
PARTITION p2 VALUES [("10"), ("20")),
DISTRIBUTED BY HASH(`aa`) BUCKETS 1
//创建1个上卷表,就会生一个MaterializedIndex
create materialized view mv_max as select aa, max(bb) from TestTbl group by aa;
MySQL [test_db]> show tables;
+-------------------+
| Tables_in_test_db |
+-------------------+
| TestTbl |
+-------------------+
2 rows in set (0.001 sec)
#层级关系
TestTbl
|--P1
|-TestTbl
|-Tablet1
|-Replica1
|-Replica2
|-Replica3
|-mv_max
|-Tablet2
|-Replica1
|-Replica2
|-Replica3
|--P2
|-TestTbl
|-Tablet2
|-Replica1
|-Replica2
|-Replica2
|-mv_max
|-Tablet3
|-Replica1
2.2 层级信息查看
通过 show proc 命令查看:
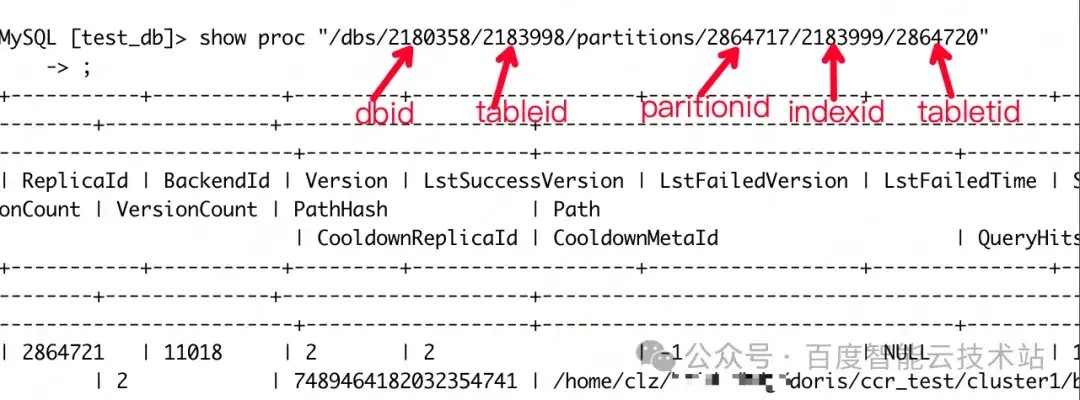
下面为大家介绍 show proc 的灵感来源。
Linux 中的 proc 系统类似,Doris 中的 proc 系统也被组织成一个类似目录的结构,根据用户指定的「目录路径(proc 路径)」,用来查看不同的系统信息。
proc 系统主要面向系统管理人员,方便系统管理人员查看系统内部的运行状态。如表 tablet 状态、集群均衡状态、各种作业的状态等。
一般查 FE 的元数据,只要记住上述这一个命令就够了。
3 BE 的元数据
3.1 层级结构
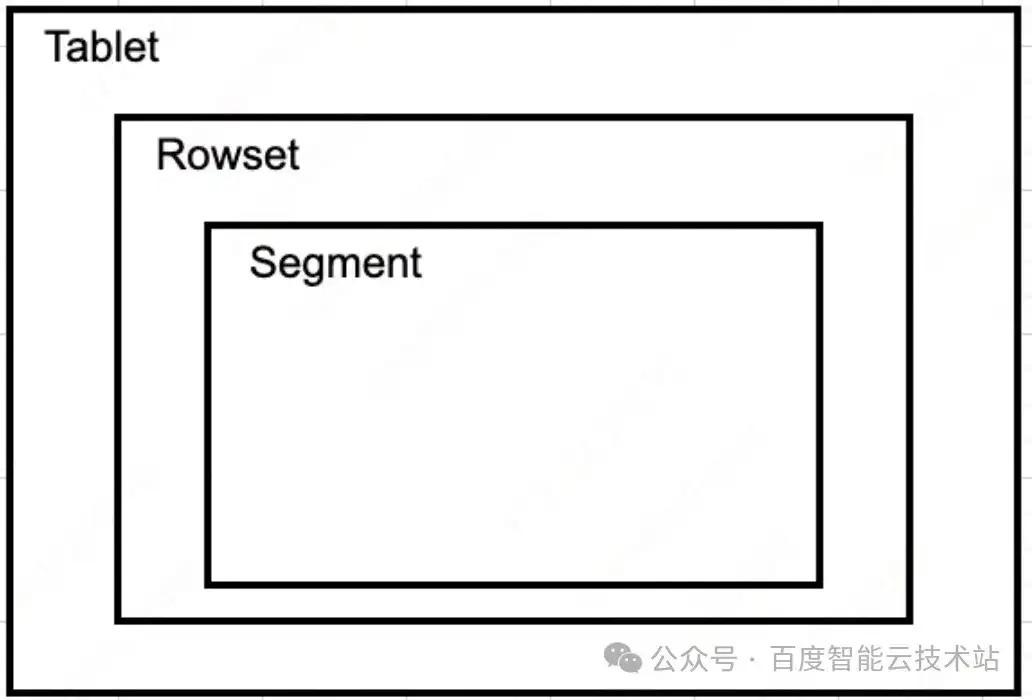
- Tablet:数据的 1 个分片;
- Rowset:数据版本,1 次成功的导入对应 1 个 rowset,比如 insert into 后就会对应生成 1 个 rowset;
- Segment:数据文件,1 次成功的导入可能生成 1 个或多个 segment,1 个segment 文件最大为 256M。
比如用 stream load 导入 10G 的文件,会生成 1 个 rowset、40 个 segment 文件。
3.2 层级结构查看
show tablet 命令:
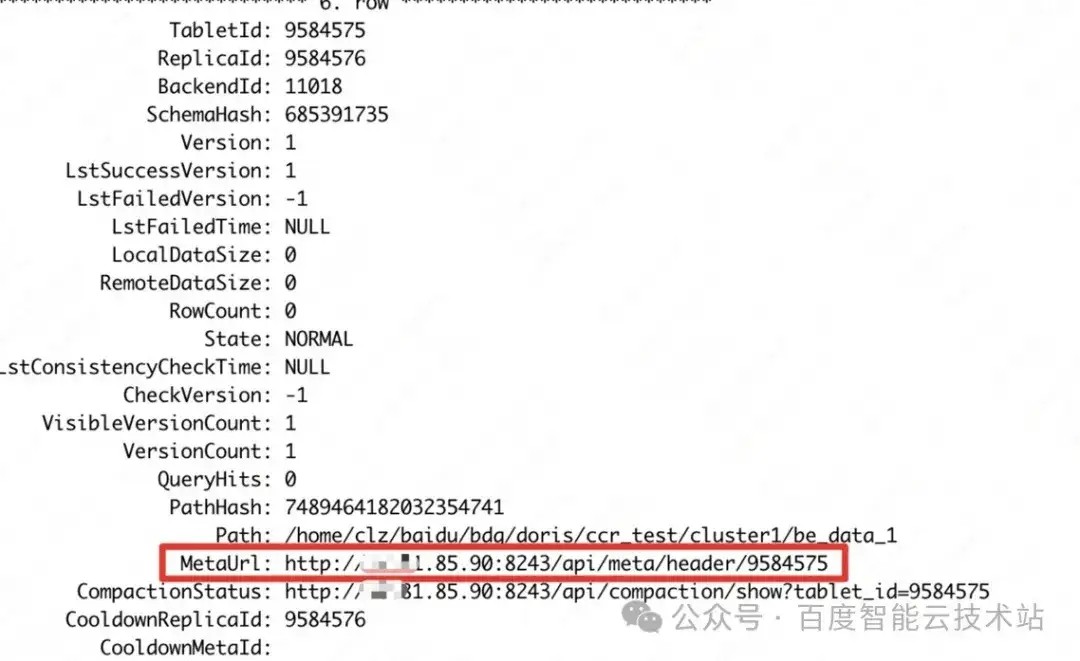
直接在浏览器中打开 MetaUrl ,即可获得 tablet 在 BE 的层级信息。
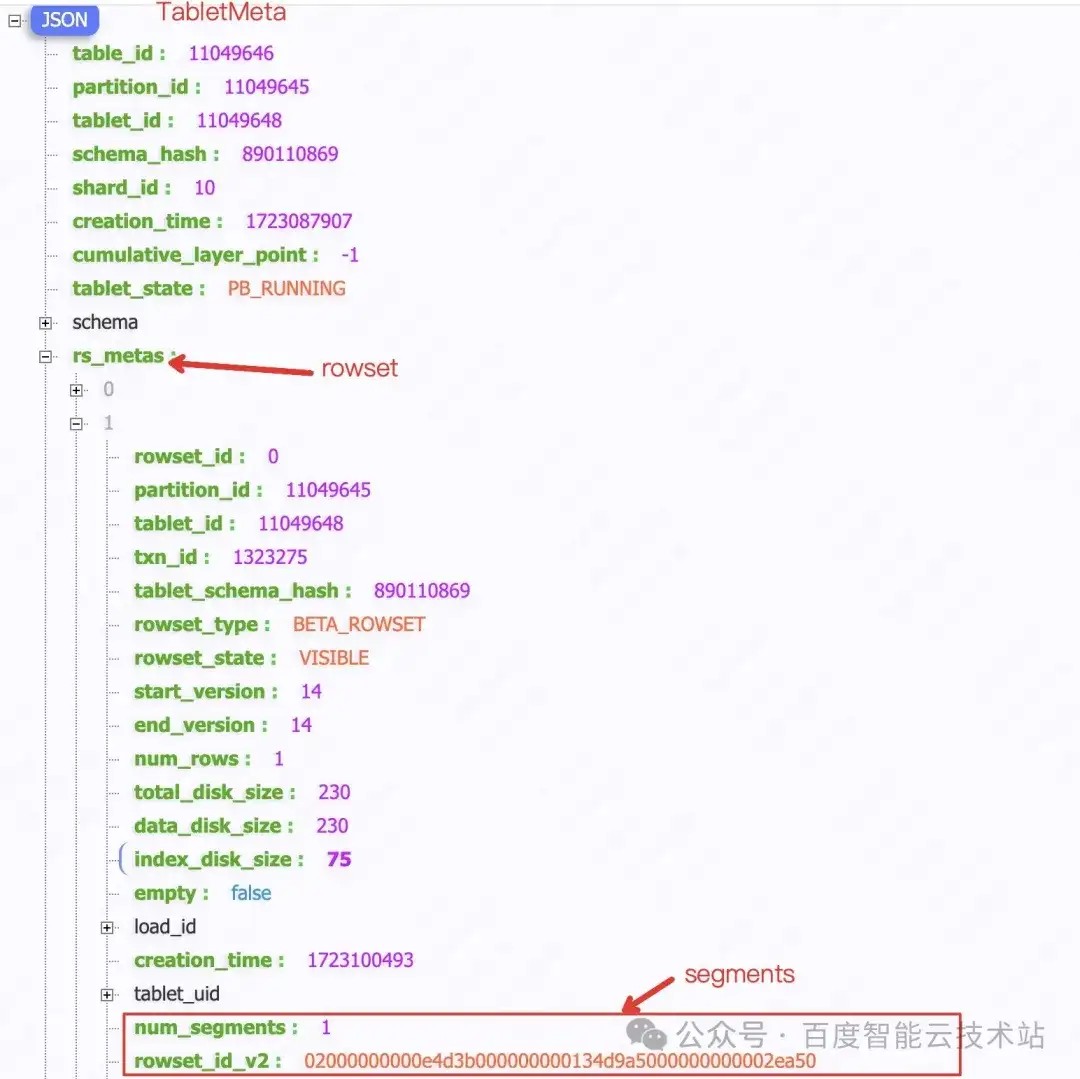
4 原理分析
在了解 FE 和 BE 的元数据组织方法后,我们将详细为大家介绍如何实现冷热分离。Doris 的每个表的每个分片默认有 3 个副本,转冷本质就是把冷数据挪到远端存储上,需要考虑下面 3 件事:
- 谁来负责挪数据?
- 以什么粒度来挪动数据?
- 挪完之后其他副本怎么处理,怎么同步转冷结果?
Doris 会副本中选择 1 个作为 leader 来负责转冷相关操作(包括数据上传/元数据上传/冷数据 Compaction /无效数据删除),其他的副本作为作为 follower,负责同步 leader 的转冷信息,包括数据和元数据。
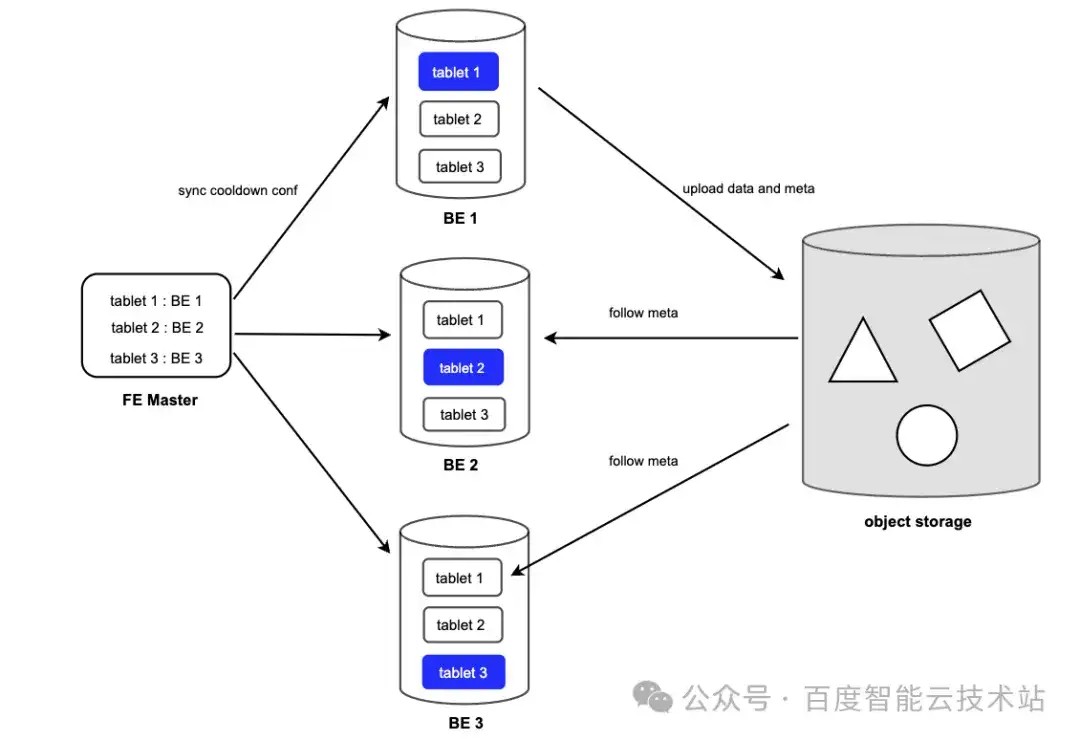
4.1 Leader 选择
问题来了,如何选择到合适的 replica 作为 leader ,目前有 2 种方式:
- 方式 1 :选择合并进度快,版本少,需要上传的数据就少;
- 方案 2 :随机选择 1 个。
Doris 采用的是方案 2,随机选一个。因为方式 1 需要 FE 保存每个 replica 的 compaction 的进度。版本、复杂度提高,并且合并进度时刻动态变化。如当前时刻某个节点比较快,下一刻速度变慢,总体达不到少上传数据的目的,所以采用随机方案。
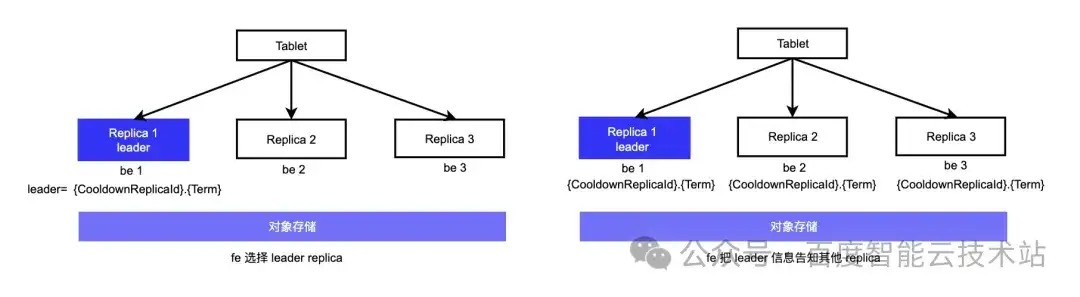
选择出 leader 后,FE 会把 leader 信息同步给每个 replica,并保存在 BE 的meta 信息里,leader 由 Cooldownreplicaid 和 term 来表示。term 是个自增的,表示第几个任期,BE 拿到 Cooldownreplicaid 后与自己的 replicaid 比较,如果一致说明是 leader ,从而进行下一步的相关数据操作。
4.2 转冷粒度
控制 leader 对数据进行转冷粒度,有两种方案:
- 第一种方案是按 segment:segment 是最终保存数据的地方,在磁盘上是 1 个文件,默认大小 256M;
- 第二种方案是按 rowset:1 次成功导入数据对应 1 个 rowset。Doris 选择的是以 rowset 为转冷粒度,原因是 segment 如果到期转冷,意味着该 segment 对应的 rowset 都到期了需要转冷,单独对 1 个 segment 转冷意义不大;而 rowset 为基本单元对数据进行冷热转换,可以更容易的解决冷热数据迁移过程中有新数据写入的问题。
4.3 转冷过程
leader 进行转冷过程本身并不复杂,到期后把 rowset 上传、并更新 meta 即可。复杂一点是 follower 节点对数据进行同步,因为每个 follower 本身有自己的 compaction 逻辑,进度与同步的过程会有差异。整体主要分为 2 种情况:
- leader 转冷后的 rowset,follower 无重叠;
- leader 转冷后的 rowset,follower 有重叠。
接下来举例子来说明,假设有 1 个 TestTbl 表、3 个副本
CREATE TABLETestTbl(bint ) ENGINE=OLAP
先后插入 5 条数据:
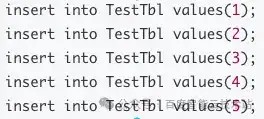
4.3.1 情况 1 :leader 转冷后的 rowset,follower 无重叠
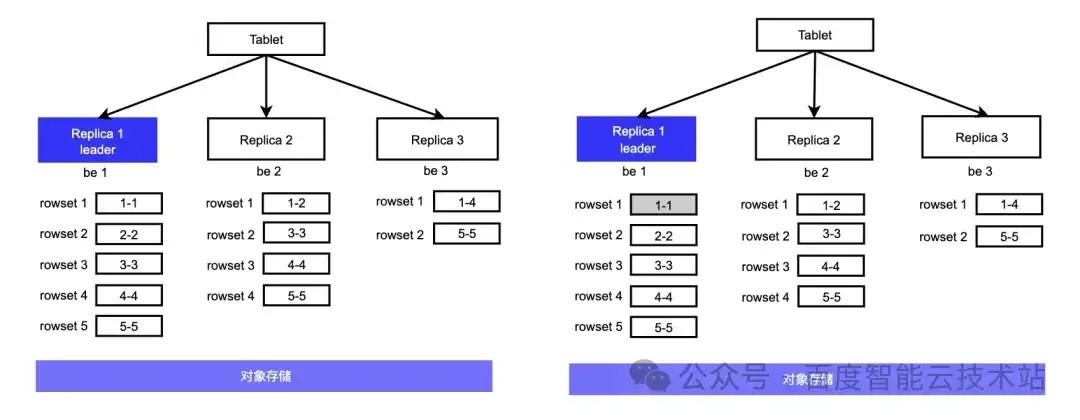
R1、R2、R3 的 compaction 的进度上左图所示,其中 R1 为 leader 未进行 compaction,版本最多有 5 个,R2 版本 [1-1][2-2] 合并为了 [1-2],只有 4 个 R3 合并的最快只剩 2 个 rowset,R1 中的 rowset 1 到期后,转冷过程就 2 个步骤:
- 首先会把 rowset[1-1] 数据文件(segment)上传到对象存储;
- 把已经转冷的 rowset meta 信息生成 1 个 meta 文件上传到对象存储,meta 文件名为 {LeaderReplicaId}.{Term}.meta 记录 2 个核心字段, cooldownrowset 和 cooldown_meta_id,其他 cooldownrowset 记录的是 R1 所有已经转冷的 rowset,cooldown_meta_id 是一个 uuid,每次转冷操作都会重新生成,主要用于判断 follower 同步进度用途,如果 follower 同步完成会把这个值记录在本地,FE 通过 cooldown_meta_id 来判断 3 个副本转冷操作是否完成同步,所以也可以通过 CoolDownMetaId 的值是否更新来判断是否进行了转冷。
注:leader 每次只会对 1 个 rowset 进行转冷,默认间隔 20s。
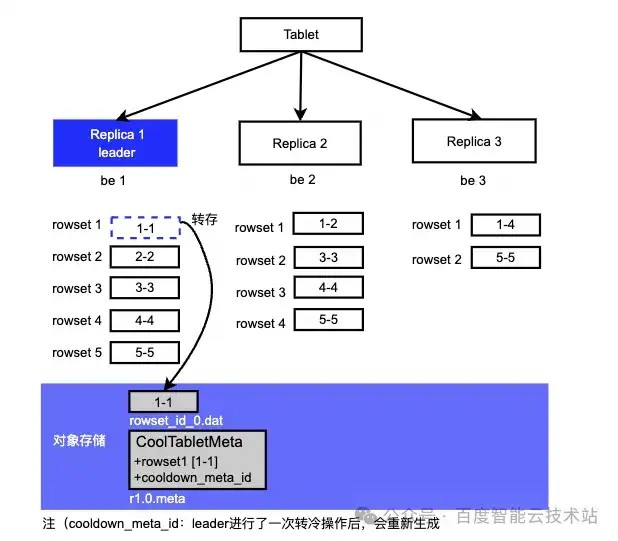
Follower 节点同步过程:
- 读取 meta 文件,获取已经转冷的 rowset meta 信息;
- 跟本地的 rowset meta 信息进行对比,看看已经转冷的 rowset 是否能够覆盖本地。
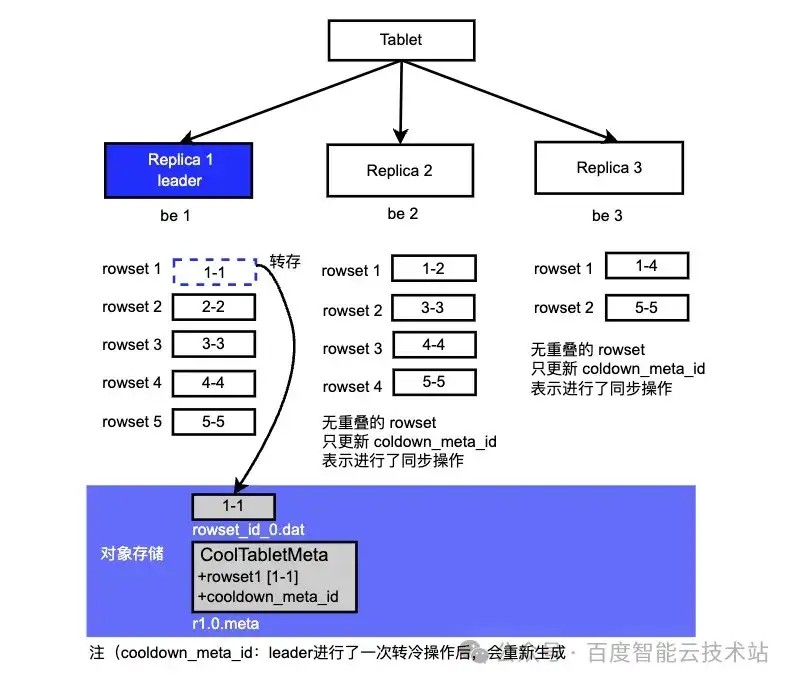
注:虚框表示数据在远端存储上。
R2、R3 从 meta 读取 rowset 后,发现转冷的 rowset 只有 1-1 版本,本地最低的版本是1-2、1-4、1-1,无重叠,无法覆盖本地。所以本次同步不更新 rowset 的信息,只更新 cooldown_meta_id 。转冷整个过程持续进行,所以leader 只要有转冷操作,cooldown_meta_id 就会变,follower 需要同步 leader 的变动。这时如果用命令查看副本的冷数据时会看到某些副本的 remotedatasize 为 0,有些不为 0,也是符合预期的。
4.3.2 情况 2 :leader 转冷后的 rowset,follower 有重叠
假设先后插入上方 5 条数据后各副本的进度如下图所示,R1 没有进行过 merge,R2 版本 [2-2][3-3] merge 为了 [2-3]、R3[3-3][4-4] merge 为了 [3-4]。
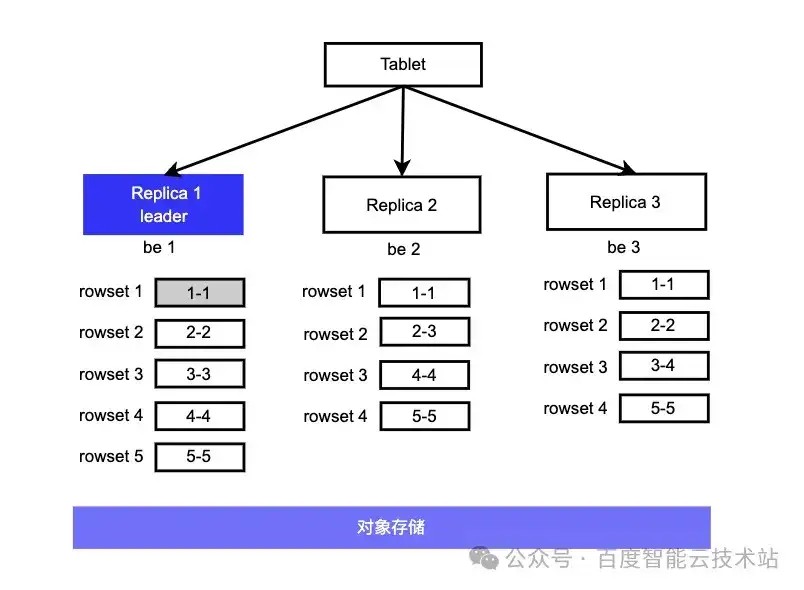
Leader 的 rowset [1-1] 到期转冷到对象存储。
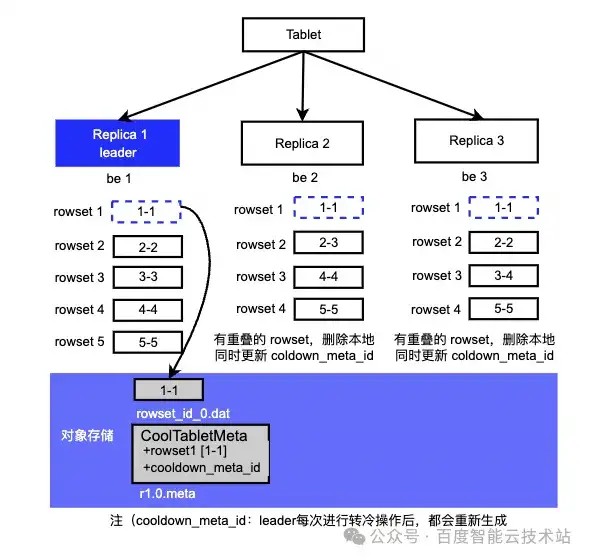
R2、R3 从 meta 读取 rowset 后,发现转冷的 rowset 1-1 与自己本地的 rowset 有重叠,则删除本地版本 1-1,拷贝远端 [1-1] 的 meta 信息, 并更新cooldown_meta_id,完成转冷同步。在这个过程中,您可以查看 rowset 中 meta 信息的 resource_id 字段是否为空来判断是本地 rowset /远端 rowset。
4.4 冷数据 Compaction
ttl 到期后, 最终 leader 节点上的所有 rowset 都会被转冷,同时 follower 会同步 leader 上的所有转冷的 rowset。
Doris 2.0 版本中支持了对冷却到对象存储的冷数据进行 Compaction(ColdDataCompaction)。通过冷数据 Compaction,将冷数据重新组织并压缩成更紧凑的格式,从而减少存储空间的占用,提高存储效率,整个过程如下图所示:
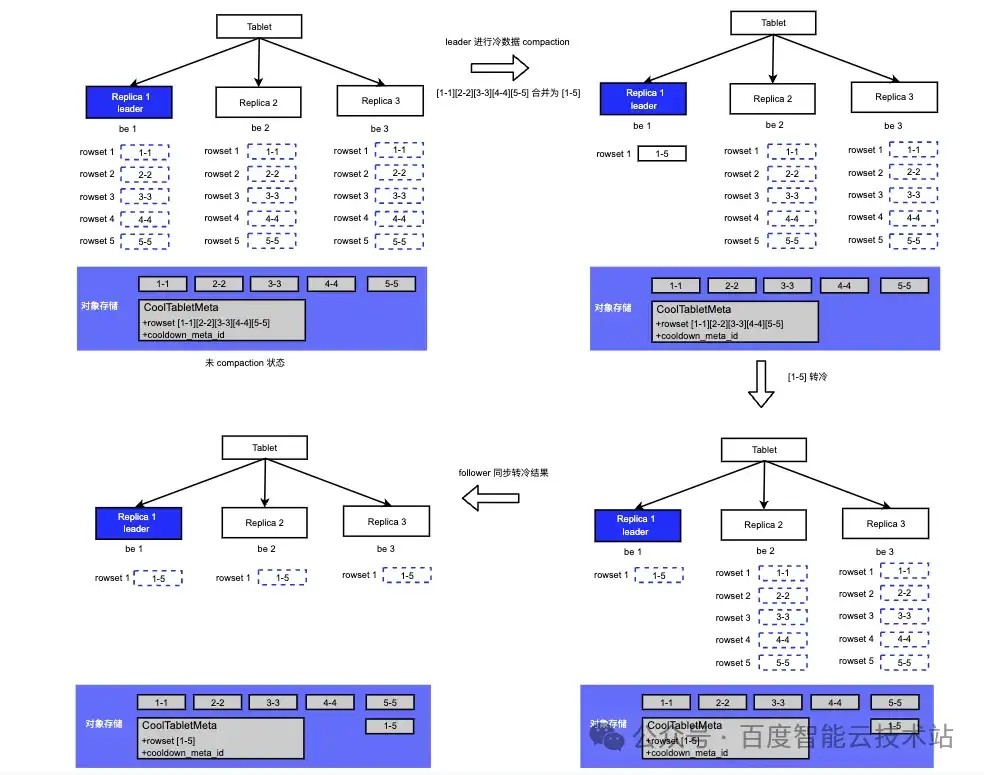
注:只有 leader 节点才会进行冷数据 Compaction。当前冷数据 Compaction 功能默认不打开。
4.5 无效数据清理
经过冷数据的 Compaction 或用户删除了某些分区后,对象存储会存在出现一些不再使用的无效数据。假设 Compaction 后, [1-1][2-2][3-3][4-4][5-5] 合并为了 [1-5],需要进行清理原来不再使用的数据。
远端存储的文件清理流程较为复杂,不能直接进行删除。因为需要保证所有的 follower 都同步 leader 最新的转冷结果,所有删除的时候需要有两次确认的过程。清理流程如下:
- leader 定期检查某个 tablet 下,为对象存储的所有 rowset 文件进行 list;
- 跟本地进行 rowset 进行对比,找出不需要的 rowset;
- 向 FE 发送确认请求,检查其他 replica 是否跟 leader 的转冷结果保持一致:
- 所有副本的 cool_replica_id & term 一致(同 leader )
- 所有副本的 cooldown_meta_id 一致 (表示 leader 的转冷,follower 都同步完成了)
- 如果一致则进行无效数据的删除,不一致则本次不进行操作,等待下一次检查。
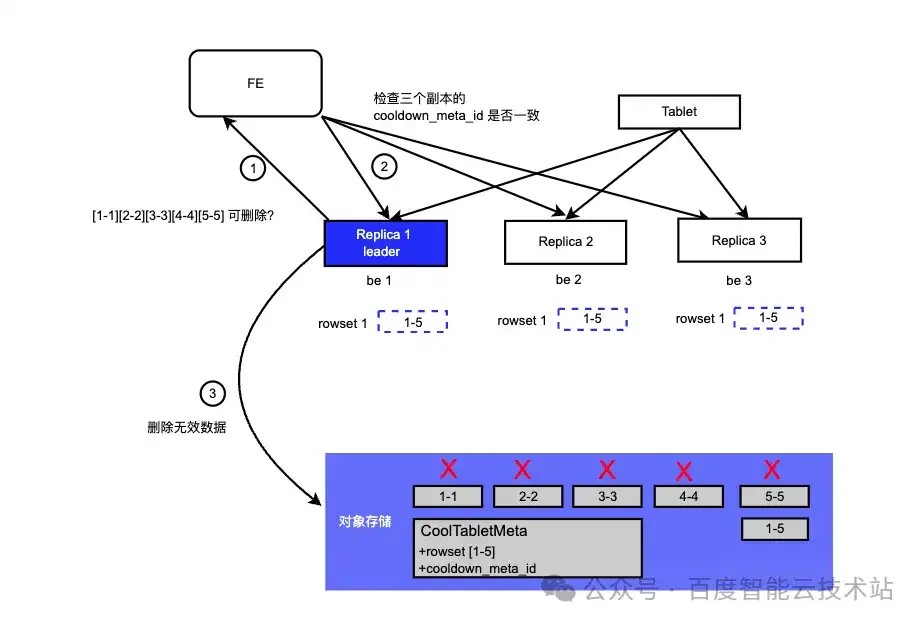
上图 [1-1][2-2][3-3][4-4][5-5] 属于不再使用的数据,leader 跟 FE 确认所有 replica 同步完成后,进行清理。
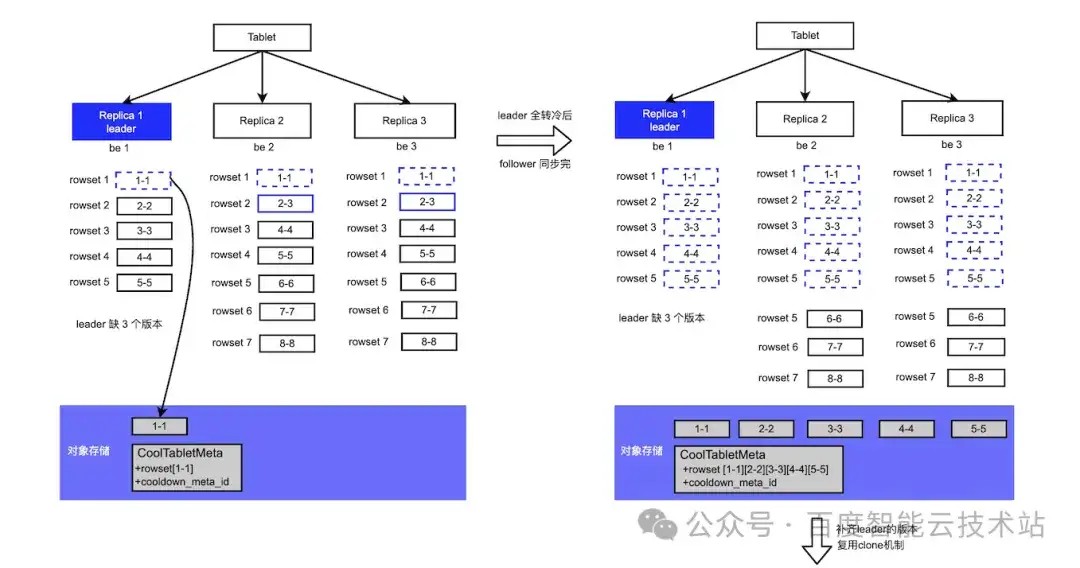
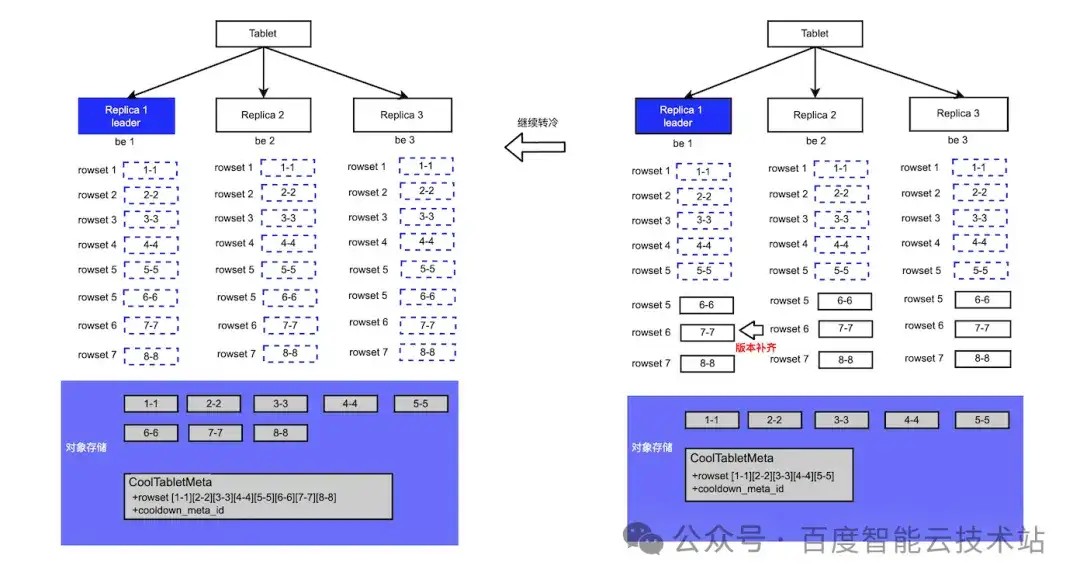
4.6 Leader版本落后情况
因为 leader 是随机选择的,所以有概率存在 leader 的版本落后于 follower 的问题。因为对于 Doris 的写入来说,超过半数节点写成功就能提交。比如我们再插入 3 条数据:

R1 由于某些原因以上 3 条数据插入失败了, R2、R3 插入成功,R1 是 leader,落后 R2、R3 3 个版本, 在经过一段时间 R1 上的数据全部转冷,缺失的 3 个版本如何转冷呢?
Doris 支持 clone 修复,当 FE 发现某个副本版本缺失后,会自动进行版本补齐。所以 leader 缺失的版本补齐后再进行转冷,从而保证随机选择的 leader 在版本缺失的场景下也能正常完成转冷。下图展示 leader 落后的转冷过程:
4.7 冷数据 Cache 机制
为了优化冷数据为了查询的性能,Doris 2.0 引入 Cache 的概念。在冷却后首次命中,Doris 会将已经冷却的数据又重新加载到 BE 的本地磁盘,Cache 有以下特性:
- Cache 实际存储于 BE 磁盘,不占用内存空间;
- Cache 可以限制膨胀,通过 LRU 进行数据的清理。
4.7.1 冷数据分层性能对比
为了解数据转冷后对性能的影响, 我们对 SSB-sf500 测试集进行了冷热测试,全部转冷后,相比本地性能下降 10 倍。
注:测试集群 3Fe+3BE, 8c*32G。
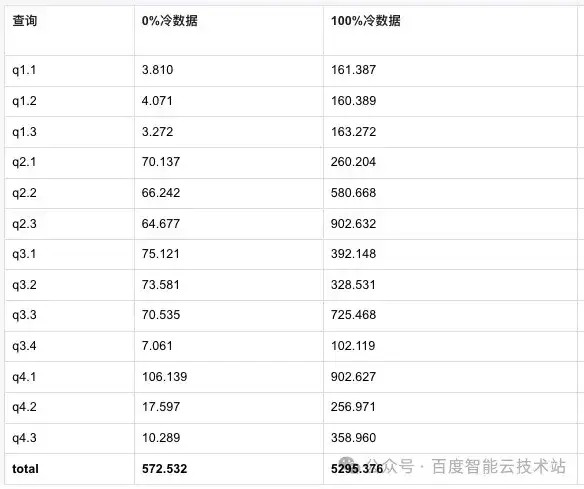
测试集数据:
https://github.com/apache/doris/tree/master/tools/ssb-tools/ssb-queries
4.7.2 数据缓存
为了提升冷数据的查询性能, 引入数据缓存 (File Cache) 通过缓存最近访问的远端存储系统 ( HDFS 或对象存储) 的数据文件,加速后续访问相同数据的查询速度。在频繁访问相同数据的查询场景中,File Cache 可以避免重复的远端数据访问开销,提升热点数据的查询分析性能和稳定性
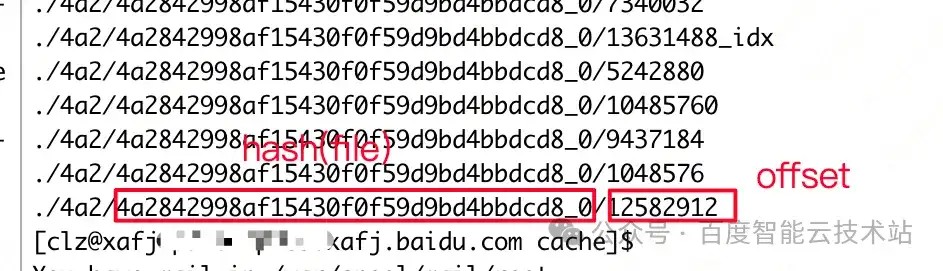
其实现原理是:File Cache 将访问的远程数据缓存到本地的 BE 节点。原始的数据文件会根据访问的 I/O 大小切分为 Block。Block 被存储到本地文件cache_path/hash(filepath).substr(0, 3)/hash(filepath)/offset 中,并在 BE 节点中保存 Block 的元信息。Block 的默认大小为 1M。
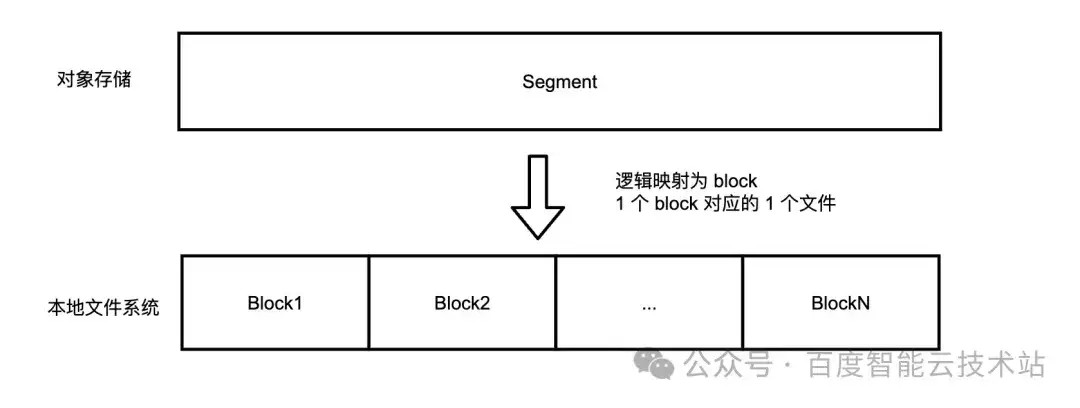
访问相同的远程文件时,Doris 会检查本地缓存中是否存在该文件的缓存数据,并根据 block 的 offset 和 size,确认哪些数据从本地 block 读取,哪些数据从远程拉起,缓存远程拉取的新数据。BE 节点重启的时候,扫描 cache_path 目录,恢复 block 的元信息。当缓存大小达到阈值上限的时候,按照 LRU 原则清理长久未访问的 block。
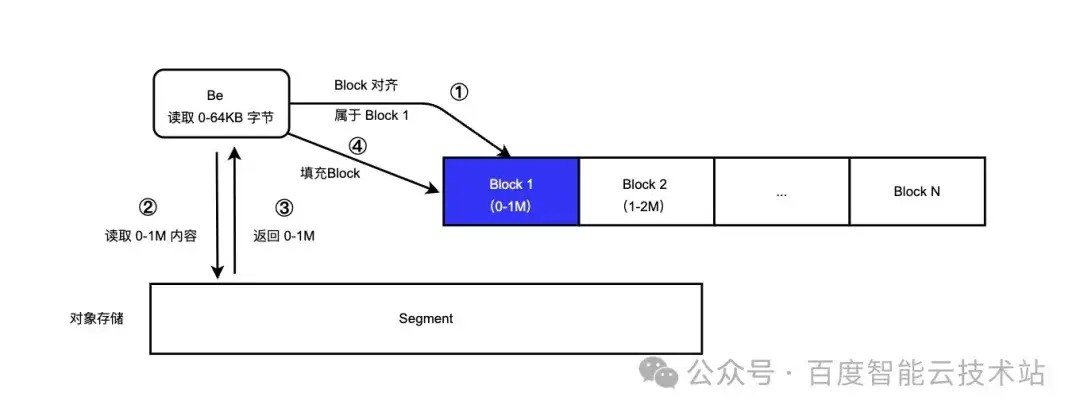
有了 File Cache 后,下面为大家进一步介绍读取过程。比如,我们需要读取远端存储中 0-64KB 范围的内容。
- 首先进行 block 对齐,计算 0-64KB 属于哪个 block,由于 block 1 的范围在 0-1M, 发现属于 block 1,随后检查 block 1 是否在磁盘上;
- 如果 block 1 不再磁盘上则从远端读取 0-1M 范围内容;
- 从 0-1M 内容中截取 0-64KB 返回 BE;
- 填充 block 1,写到本地文件。
磁盘上 blockcache 文件列表样例:
4.7.3 性能测试+数据缓存
我们在配置 10G 大小的 File Cache 后,再测试下 ssb-sf500 的性能表现:
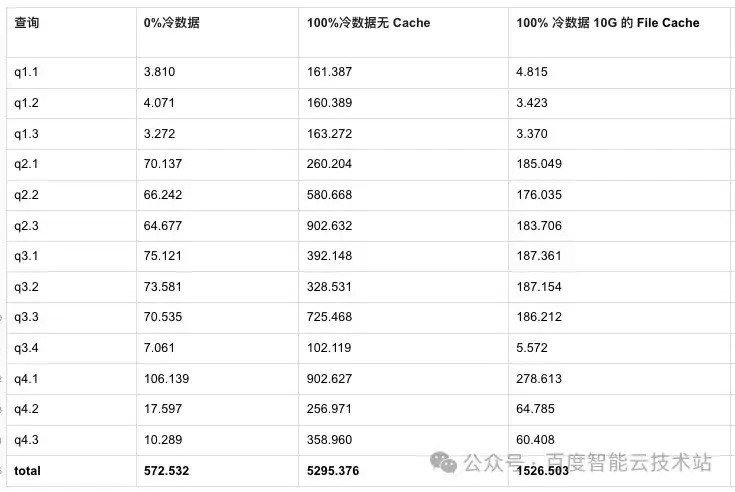
可以看到,相较没有 Cache 时,整体性能提升 3 倍。原因是通过 Cache 减少了网络的 I/O 同时由于 Doris 是列存预读效果好,比如 select sum(A) from xx 对 A 读取了 0-64KB 数据后,大概还会读取 64-128KB,而由于 64-128KB 的数据已经在 block 中了,缓存命中率高。

4.7.4 数据缓存大小如何配置
通过分析我们发现 Cache 的能发挥作用主要在于两点: 预读与减少网络 I/O。Cache 的大小似乎不太重要,因为只要能满足当次查询缓存的大小就能加速,为了验证这个结论,我们再做两组测试,
- 加大 Cache 的大小,把 Cache 的大小调整为 50G,观察对整体性能提升的效果;
- 调小 Cache 的大小,把 Cache 的大小调整为 1G,观察对整体性能提升的效果。
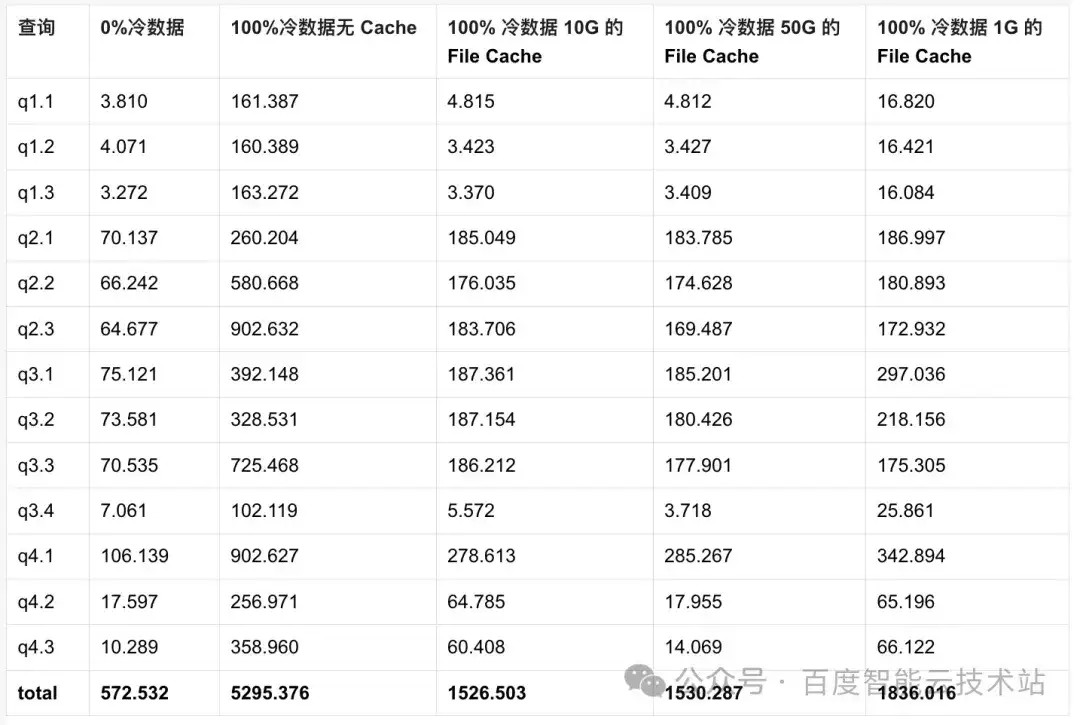
调整后,我们发现 Cache 加大后对性能的提升效果并不明显,这也符合我们的预期,同时 Cache 缩小 Cache 对性能也不会显著恶化,因此我们可以得出 1 个结论:有 Cache 很重要,但需要把握 Cache 调整的维度。比如:
- 测试中我们只配置了 1/50 冷数据大小的 File Cache 对性能就能明显提升,
- 配置 1/500 冷数据的大小的 Cache 与 1/50 冷数据大小的 Cache 性能差距也没有出现太大的差距。

发表评论
登录后可评论,请前往 登录 或 注册