智算基石全栈加速,百度百舸 4.0 的技术探索和创新
作者:xxinjiang2024.10.23 16:11浏览量:6288简介:百度百舸·AI 异构计算平台支持了百度文心系列大模型的落地和迭代升级,帮助客户训练了很多行业和多模态
本文整理自百度云智峰会 2024 —— AI 基础设施论坛的同名演讲。
插播一条百度百舸产研岗招聘信息:
加入百度智能云 AI 计算部,共同建设行业领先的 AI 基础设施。站在浪潮之巅,探索大模型时代基础设施的边界。(参考:大模型走进产业,生产力跃迁正当时)
百度百舸·AI 异构计算平台支持了百度文心系列大模型的落地和迭代升级,帮助客户训练了很多行业和多模态大模型, 包括国内首个专为数学打造的大模型 —— 九章大模型、国内首个对标 Sora 的视频大模型 —— Vidu、生成效果全球领先的 3D 大模型 —— Tripo 2.0 ……
新一代的百度百舸将支撑和加速更强大的大模型问世,这样的机会怎么可以轻易错过。先投递简历开始,加入顶尖技术团队,在大模型的发展潮流中画上自己的一笔。
目前,百度百舸开放以下职位:异构计算工程师 —— 加速方向、AI 计算通信加速研发工程师、云原生 AI 计算工程师、AI 算力平台资深产品经理。
请访问 talent.baidu.com 了解以上职位更详细信息。或者可以将简历直接发送至 wenxin09@baidu.com。
1 百度百舸 4.0 核心架构
过去一年大模型的浪潮,让我们深切感受到当前基础设施建设赶不上模型发展的需求。那 AI 基础设施要如何变革,如何提供更优质的算力,支持模型的探索和创新呢?今天我来分享一下百度智能云的技术探索和创新。
对比 CPU,以 GPU 代表的 AI 芯片最大的难题是充分发挥芯片性能。如果 CPU 是聪明的大脑,AI 芯片就是强壮的手和腿,需要一个很复杂的软件栈和配套设施,才能充分发挥出性能。我们常说,不经意间 50% 的 AI 算力就被浪费掉了。
百度百舸是专为 AI 计算设计的高性能算力平台,为用户解决掉软件栈的复杂度,充分把 AI 算力发挥出来。百度百舸 4.0 的技术架构可以分成 4 层:
硬件资源层,以高性能网络架构为核心,包括高密 AI 服务器,以及全液冷的数据中心;
集群组件层,包括百度集合通信库 BCCL,除了基础的通信能力,更重要的能支持集群的性能调优以及故障定位;以及 AI 编排和调度的组件,能实现任务混布,资源的充分利用,以及多维度的可观测能力;
- 训推加速层,针对大模型提供的算子库、并行策略、推理架构等,对长文本、MoE、多模态等实现全面加速;
- 最上面是平台工具层,实现训练任务的管理、自动容错;推理任务的不同 SLA、不同芯片的部署;以及各类应用的快速部署;为用户提供易用的使用界面。
接下来,我为大家逐一分享相关的技术。
2 AI 基础设施
我们说 AI 计算需要极致规模、极致高密和极致互联,这是指的硬件设计层面的要求。
XMAN 5.0 是我们最新推出的新一代 AI 计算机,通过异构多芯、兼容液冷、高可用性设计,应对当前 AI 计算中的多重技术挑战。
首先,是算力多元化,AI 芯片的选择必然更加多样。XMAN 5.0 通过模块化设计,支持多种芯片组合,既兼容 NVLink,也支持 OAM 模组,兼容 Intel、AMD 及国产芯片。
第二个挑战是芯片功耗的持续攀升。随着 AI 算力密度增加,AI 芯片的功耗也从几年前的 400W,迅速上升到 700W,下一代要到 1200W。XMAN 5.0 实现了液冷,相较于风冷方案,单机功耗下降 800W,同时运行温度降低 5-10℃,故障率降低 20%~30%。
此外,密度高,带来了故障域高,硬件故障对集群可用性的影响变大;XMAN 5.0通过模块化设计,实现灵活的组件替换,提升系统高可用性,降低了故障风险。
只有经过优秀设计的 AI 计算机还不够,XMAN 5.0 还配备了百度自研的「灵溪」液冷 IDC,专为高密度计算集群打造,使单机柜功率密度从传统的 30kW 提升到 100kW 以上,PUE 值从 1.3 降至 1.15,系统能效提升超过 10%。

HPN 网络是 AI 集群的核心,他既不同于为 HPC 设计的 IB 网络,他是以延迟为核心;也不同于传统 IaaS 的 RDMA 需求,他是以多租户共享为核心。
我们在 RDMA 的基础上,设计吞吐优先的 AI 网络。针对 AI 典型的场景,通信流少、通信路径可预期的情况下,最大化系统吞吐。
我们新一代的 HPN 网络,具有以下几个特性:
规模上支持到了 10 万卡。 基于 51.2T 交换芯片,采用多平面架构,单集群最大可支持 10 万卡。同时,这一代 HPN 对物理空间也实现大幅拓展,可支持 30km 内的跨地域组网;
通信上实现了完全无阻塞。 网络拥塞和多路径负载不均是 RDMA 的痛点问题,通过自适应路由技术,实现了通信带宽有效率超过 95%,通信性能提升 20%;
- 运维上实现了毫秒级的监控。通过 10ms 级别的高精度监控,以及主动 pingmesh 探测能力,对各类网络问题,实现了秒级定位和分钟级止损的能力。
3 高性能集群
第二层是管理集群需要的集群组件,包括 AI 资源和作业的调度编排组件,以及集合通信库组件。
AI 负载对资源的要求有以下几个特点:
能把异地、异网、异构的算力聚合起来,有算力就能用;
推理的波峰波谷明显,要提升利用率,需要多种负载的混部;
- 推理任务和训练任务的特点,推理需要单机多模型,训练需要任务弹性。
百度百舸 4.0 实现了一套以弹性队列为核心的资源池产品,帮助客户提升资源利用率:
对于异地、异网、异构的算力形态。百度百舸能构建统一的资源池,根据任务的需求和集群中的剩余资源,自动选择最具性价比的算力;
针对训推一体化的多种负载。提供了弹性队列机制,支持队列间实时的超发、抢占、隔离保障,没有任何负担的实现复杂混部策略;
- 面向训推任务的特点。 推理引擎支持单机冷热模型部署,训练任务支持资源量伸缩;
最终,体现在业务效果上,百舸多芯集群已支持 18 种以上的芯片类型,包括英伟达、昆仑芯和昇腾;资源分配率达 96%,集群利用率 95%。

另一方面,集群之所以难管理,在于有各种同步、异步的通信逻辑,同时性能还要求特别高。然而性能和可观测定位是有矛盾的,但是性能和故障定位又是同等重要。
百度百舸 4.0 基于专门针对大模型集群的容错能力和性能优化开发了百度集合通信库 BCCL:
在性能优化方面,提升高性能计算效率的方式就是通信与计算 overlap。然而,通信和计算同时进行会有资源争抢,各自的性能都有大幅下降,BCCL 通过支持多优先级队列和 channel tuning,提高了 overlap 的有效性。在 400G 大带宽网络下,进一步通过 chunk tuning 技术优化性能。最终整体实现了 5% 的性能提升。此外,对于 MoE 模型中的 alltoall 通信场景,BCCL 采用自定义的 alltoall 算子,实现了约 10% 的通信性能提升。
在稳定性和容错性方面,面对最难的 hang 以及慢节点发现,BCCL 实现了秒级的异常状态感知和故障节点锁定。这意味着在训练过程中,如果出现异常,BCCL 能够快速检测并定位问题节点。此外,网络的抖动也是不可避免的问题。BCCL 提供了秒级网络容错机制,确保在网络出现短暂故障时,训练任务能够保持持续稳定的运行,避免频繁中断。

4 大模型训练
基于集群的管理能力,我们进一步来看大模型训练。
大模型训练是一个庞大的单一任务,训练任务稳定性至关重要:
无效训练时间 = 故障次数 (定位恢复时长 + 重算时长)+ 写 checkpoint 总时长。*
从这个公式可以看到大模型训练的技术挑战:
首先是,一个卡出错,整个集群就得停下;
然后出错了不怕,怕的是找不到故障卡。GPU 经常会出现 hang、精度异常等静默故障频发;
- 完成定位后,万卡任务恢复过程中也会因为启动耗时、 checkpoint 重算带来小时级别的损失。
针对这些挑战,百度百舸 4.0 真正做到了万卡任务秒级的故障感知、分钟级的故障定位和恢复:
首先在故障感知层面,我们通过硬件全链路监控,硬件故障召回率达 95% 以上。除了硬件故障,对软件类的进程状态异常、I/O 异常、速度异常、流量异常都有全面监控,实现了任务异常秒级感知;
其次在故障定位阶段,面对最难的 hang 场景,通过 BCCL 实现了精准定位;面对最复杂的精度异常问题,通过精度异常检测定位故障卡;
- 最后在故障恢复阶段,有一个问题大家提到比较少,就是任务的重启时间,通过任务镜像加速分发和数据缓存加速,实现任务的快速启动恢复;还有 checkpoint 时间,通过触发式 checkpoint 技术,将故障重算损失几乎降低到 0。
整体来看,我们实现了万卡有效训练时长在 99.5%。
再来看 AIAK 对模型的加速能力,大模型算法在过去一段时间发生了较多的变化,包括:
万亿级模型转向 MoE 架构(mixtral、deepseek)
训练上下文窗口也从过去常见的 4K 开始增大到 128K、1M 长度等;
- 多模态模型也在成为主流。
为了更好的支持长序列、多模态、以及各类 MoE 架构,百度百舸 4.0 进行了如下升级:
首先是分布式并行**策略,除了常规 3D 并行,我们还引入专家并行来支持 MoE 训练,混合序列并行来支持超长上下文。但是,他们带来的问题,都是通信量会显著提升,尤其是 MoE 的 alltoall 通信。在这些策略的实现中,我们做了极致的计算与通信并行优化,减少通信的影响;
然后是显存优化策略,长上下文带来了更多的显存开销;为了节省显存,就需要有更多的重计算或 offload ,但是他们又会带来很大的开销。为此,百度百舸针对流水线显存不均衡、重计算冗余开销、offload 卸载效率等问题分别进行了策略优化,大幅降低了显存的需求;
当各种并行策略越来越复杂,不同的芯片的算力、显存指标差异也大,模型结构也更多。那针对不同的模型,在不同的芯片上,不同的网络拓扑上,百度百舸可以分钟级产出搜出最优的的并行策略,准确率超过 95%,全面优于专家手动调出来的并行策略。
能不能实现多芯混合训练,也是大家关注的热点。
从需求来看,多芯混训可以解决两个方面的问题, 一个是利旧,比如已经建设了 1 万卡的 A 集群,现在需要完成 2 万卡的任务,只需要再新采购 1 万卡新一代的 AI 芯片即可;一个是算力供给瓶颈,通过国产的这些算力芯片组合起来,提供一个整体的聚合算力。
从技术实现的角度,多芯混训主要有三大核心要素:
- 打通集群内的网络墙,实现异构芯片互联互通。百度百舸的 BCCL 可以实现不同芯片间零开销的数据收发;通过 CPU 转发的情况下,性能损失也在 5% 以内;
使能异构芯片充分发挥性能。通过 accelerator 抽象层,把各芯算子统一接入 AIAK 加速框架,充分发挥算力;
解决异构混训引入的负 载不均问题。由于不同芯片的算力、显存和通信能力各异,我们支持 PP 异构和 DP 异构两种模式,并采用自适应并行工具,10 分钟内即可找到最优的切分策略,确保多芯混合训练的效率最大化。
目前我们已经实现了几乎无损的混合训练能力,能充分利用好各种 AI 芯片。
5 大模型推理
推理作为构建 AI 业务的最后一环,目前的重要程度越来越高。
我们看到推理会有这么几个特点:
推理的输入部分是一次全部处理,是计算密集型的;但是输出部分是自回归的,一次出一个词,是访存密集型的,对芯片的要求不一样;
作为线上系统对 SLA 有比较严格的要求:首 token 出字时间,每秒出的字数等;但是各个请求的输入、输出长度又有很大的区别;
- 超长文本的支持,需要大量的 KV Cache,超出了一般芯片的显存的能力。
这几个特点都让单一芯片的推理系统遇到了比较大的挑战。
我们需要一个解耦的系统,一部分芯片来做输入计算、一部分芯片来做输出计算、一部分来管理 KV 的存储和传输,这几个部分都能独立的扩容。
这次百度百舸 4.0 的 AIAK 套件升级了分离式调度系统。这个概念并不新,业界也都在往这个方向做。AIAK 的这次升级会有以下几个特点:
支持多芯。AIAK 上实现了多芯的统一接入,可以更好的发挥不同芯片的特点,实现一个整体 TCO 更优的系统;
对前缀缓存的混合处理。对短上下文采用 Cache 速度快,长上下文用字典树,实现了高效的前缀管理;
- 请求级别的 SLA 定义。通过定义每个请求的 SLA 要求:首字时间和出字时间,自动选择系统的处理方式。
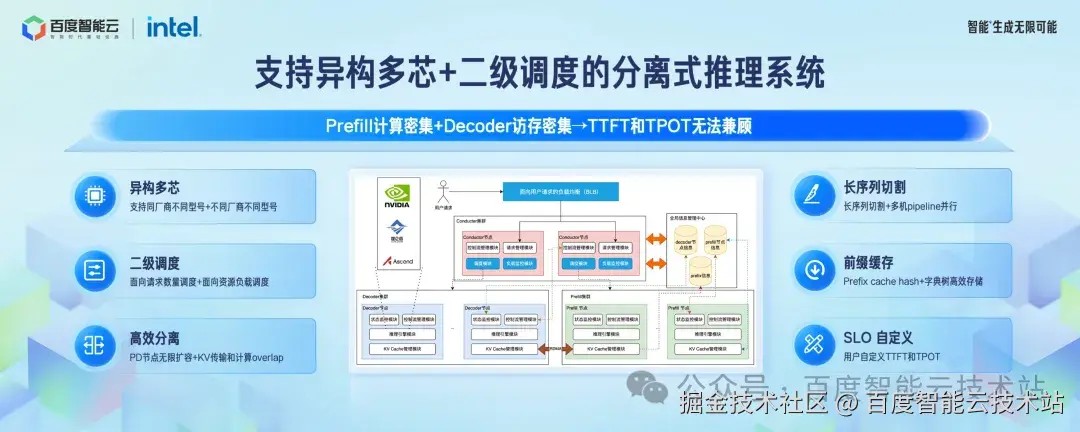
另外一个升级点是对连续 batch 的处理。
动态 batch 是大模型推理的必选技术,但是他会带来很大的调度开销,每次推理都要重新选择上下文调度,计算完成后还要更新信息做后处理。
AIAK 使用静态 slot 的方式管理请求,采用局部调度取代全局调度,充分利用两次迭代之间的缓存下来的元信息,极限压缩调度开销,同时采用高效的 GPU cuda kernel 优化后处理中的并发操作,避免 cpu 串行执行和 python 运行时带来的系统开销。
在典型的高并发和不定长的场景下,在保证首字延迟不变的情况下,token 间延迟缩短一半,端到端的吞吐在多个典型模型上提升 40%。这意味着在同等吞吐下,部署成本降低 40%,同时更短的 token 间隔带来了 20% 出字速度的提升。
在云上部署推理服务,需要依赖众多产品,整体复杂性很高。百度百舸推理平台面向推理服务这个场景,进行集成封装,整合了 10+ 云上产品,屏蔽众多云上产品对接的复杂性,为客户提供面向推理服务场景的集成产品能力。
客户可以通过自定义镜像部署推理服务,也可以通过预置的部署模板或者预置的推理镜像去快速部署。通过面向推理场景的集成产品和预置部署模板和推理镜像,让客户省去调研、调试成本,分钟级快速完成推理服务部署。
另一方面,GPU 价格比较贵,推理算力的成本高。百度百舸整合了中心云和边缘云算力,让客户可以按需选择低成本的推理算力;通过支持定时潮汐、按业务指标弹性扩缩等灵活的伸缩策略,灵活复用推理闲时算力,帮助客户进一步降低算力成本,在实践中可降低约 20% 算力成本。
AI 算力非常重要,但能够被高效地利用起来是一件困难的事情。百度百舸希望通过利用百度在这个长期的积累和经验,帮助大家扫除使用 AI 算力的重重障碍,让算力利用率最大,这是百度百舸坚持的使命。

相关文章推荐
发表评论
关于作者

- 被阅读数
- 被赞数
- 被收藏数
登录后可评论,请前往 登录 或 注册