大模型时代,云原生数据底座的创新和实践
作者:xxinjiang2024.10.23 16:16浏览量:6340简介:大模型毫无疑问是当前技术发展的热点,成为大家默认的提升生产力工具。
本文整理自百度云智峰会 2024 —— 云原生论坛的同名演讲。

大模型毫无疑问是当前技术发展的热点,成为大家默认的提升生产力工具。
但是,大模型训练主要使用互联网上的公开数据为主,没有企业内部的数据,所以大模型本质上自带的都是一些通用智能。
缺乏行业知识,以及没有实际企业内部的数据,导致大模型也就无法处理真正的企业业务问题,也没有办法作为生产力工具。
要解决这个问题,业界主要有两种方法,一种是通过精调的方法,一种是通过企业 RAG 的方式;让大模型使用企业的数据,再加上通用模型,从而拥有了企业智能。
要想拥有好的企业智能,会有几个方面的挑战:
大模型要的企业的数据,包括结构化和非结构的数据都在原来的各种存储,数据库里面。需要经过一系列加工,包括采集,清洗,转换,标注等等才能转换成大模型或者向量数据库可以处理的数据,从而支撑后面的各种业务。因此需要有很好的平台和能力可以支撑这些数据的处理、存储、以及查询。
企业业务持续经营,数据规模会同步增长。同时,大模型进一步促进更多的数据增加。这对数据平台的性能,性价比要求进一步提高。
- 对于企业来说,先人一步构建好的应用,是非常关键的。所以大模型业务天然是敏捷性要求高的业务。那为了更容易的构建业务,平台本身的易用性是非常关键的。
所以,在大模型时代,企业原来生产系统,以及新智能的应用对平台的挑战是越来越大的。更快,更好,更易用的一站式平台作用也更凸显。
接下来我给大家介绍一下在过去一年时间,百度智能云在数据库和大数据领域的重要更新,以便更好地帮助企业更好的在大模型时代迎接数据处理和存储的挑战。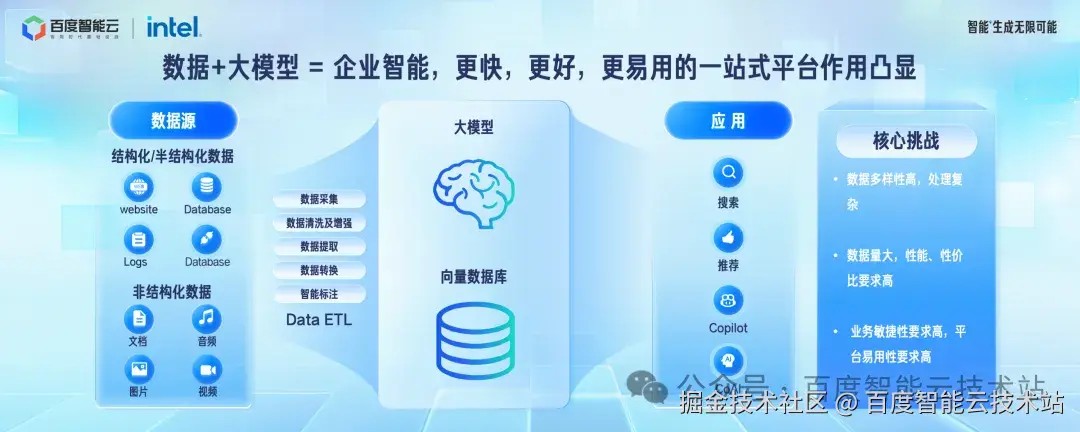
我将从内核和平台两个维度展开介绍。
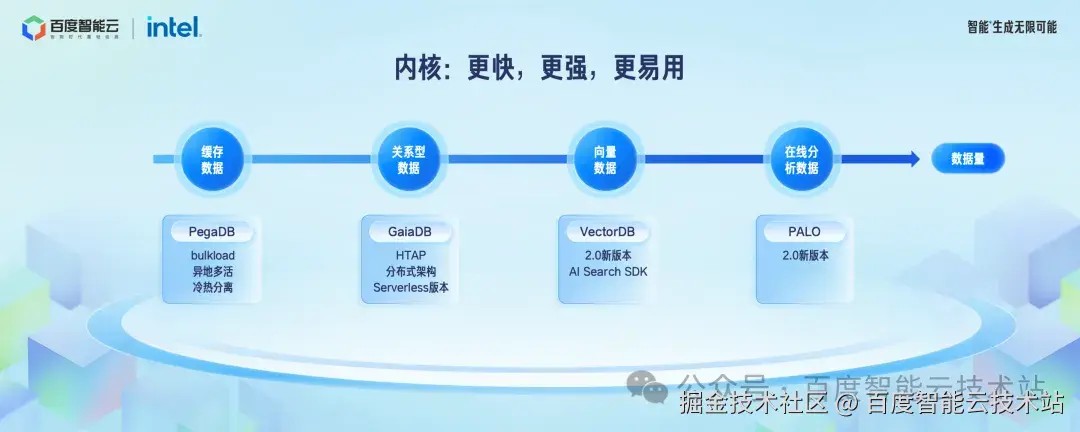
首先是内核维度。如果我们从企业数据量大小来分,通常也可以认为,越是在线数据,数据量相对较少,价值也相对较高。
通常可以分为缓存数据、关系型数据、文档数据、向量数据、在线分析数据、离线分析数据。企业的数据有不同的类型,所以需要不同能力的引擎才能处理好这些数据。
首先看缓存数据。百度智能云有自研的 KV 数据库 PegaDB,对标开源 Redis 等产品,除了传统的互联网场景,KV 数据库在 AI 场景也有很广泛的应用。缓存数据库核心挑战还是在性能、成本、高可用方面,在过去一年里面,我们核心优化了这些方面,性能上支持批量加载,高用上支持异地多活的能力,成本上支持冷热分离,通过把相对较冷的数据自动迁移到 SSD 上显著降低成本。
在 KV 数据库这个领域, PegaDB 处在业界领先的位置,体现在几个方面:
首先是性价比上,我们通过领先的价格,价格比竞品低 30%~50%。性能上支持超高的内存使用率,单集群超过 100 万 QPS,p999延迟低于 10ms。
产品在头部互联网视频网站、国内快递龙头企业等大规模落地,得到了客户的广泛认可。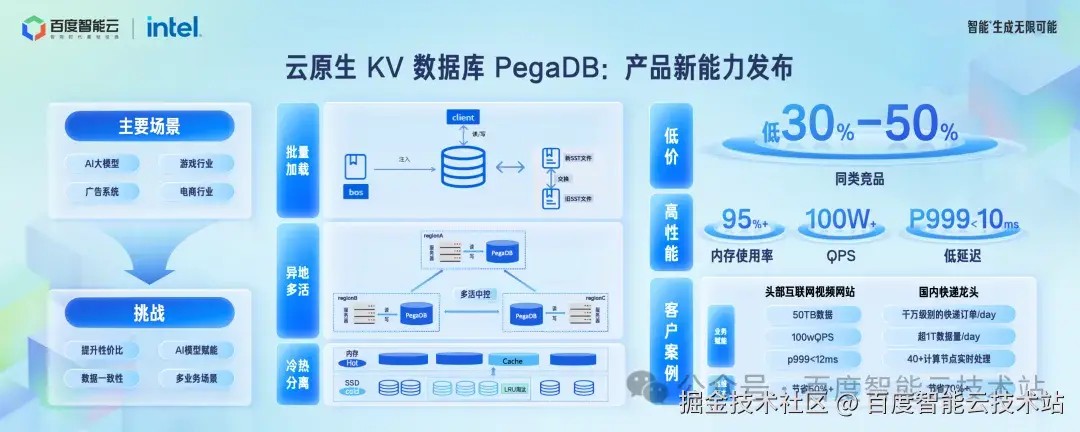
第二个就是云原生数据库 GaiaDB。
关系型数据库经过 50 多年的发展,仍能是数据库行业最核心,最重要的细分领域。其中云原生数据库经过各家厂商的努力,取得了相对的共识,那就是云原生数据库是未来的趋势和当前发展的重点。
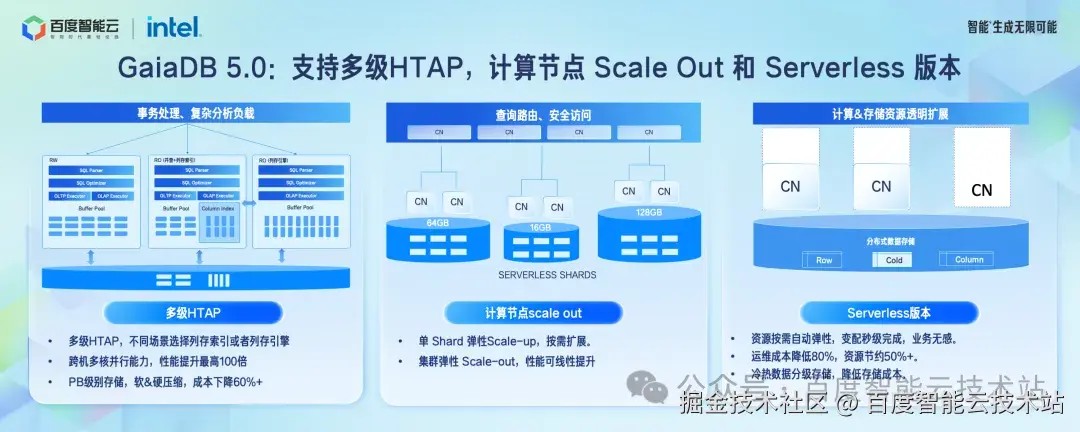
百度智能云在这个领域也持续投入,今天隆重发布 GaiaDB 5.0 版本。这个版本进一步拉开了和开源数据库的差距,产品能力齐平业界领先数据库。主要有以下几个关键的提升:
首先在计算能力上,扩展了开源数据库处理能力弱的问题,通过支持 HTAP 的能力,解决复杂分析负载的难题 ;同时,支持列存索引和列存引擎两级。轻负载的使用列存索引即可,如果数据量大,选择使用列存引擎。
第二个是计算引擎的 scale out,云原生数据库是通过存储计算分离解决了存储的扩展性问题。GaiaDB 5.0 正式引入计算节点的扩展能力,从而实现分布式云原生一体化的能力,不管是计算节点,还是存储节点都可以扩展。
- 第三个是针对开发者,或者有明细业务波动的业务,GaiaDB 支持 Serverless 版本。Serverless 通过计算节点的秒级弹性变配,存储的分级存储,从根本上压榨成本,从而实现用户超过 50% 计算资源和 80% 存储资源的节省。这个产品能力对开发者,以及需要弹性的业务非常友好。
GaiaDB 5.0 的一个里程碑的版本,未来会持续沿着位用户提供能力综合,稳定性强的数据库持续演进。
向量数据本质上是非结构化数据的高维特征,通过向量的相似度比较,成功的解决了非结构数据检索的问题。
随着大模型的火爆,向量数据库重新进入了一个高速发展。
相比在开源数据库基础上简单叠加向量插件,我们选择了自研向量数据库,因为自研向量数据库的天花板更高。
在今年 3 月份的时候我们正式发布了 1.0,截止目前为止有几千个客户。今天我们正式发布 2.0 版本。
2.0 版本相比 1.0 持续提升性价比,包括降低索引大小,提高超过 2.35倍的内存使用率。VDB 性能也处在业界领先, 相比开源向量数据库有超过 7 倍的提升。
另外,向量数据库主要服务于 RAG 场景,所以我们针对知识库场景,提供了 AI Search SDK,通过这个 SDK 可以快速的构建知识库应用。

在数据分析领域,根据业务的不同诉求,一般分实时分析和离线分析。
实时分析这个领域,应该很多人了解 doris。doris 是百度开源出去的数据仓库。Palo 就是基于 doris 做的云上服务。
今天我们发布 Palo 2.0 版本,相比开源版本,Palo 2.0 在稳定性上做了很多提升,修复了超过 500 个 bug。
Palo 2.0 版本 TPC-DS 盲测性能相比上一个版本提升超过 10 倍,通过支持冷热分离,存储的成本下降超过 80%。
大家可以到云上体验最新的稳定的 Palo 2.0 版本。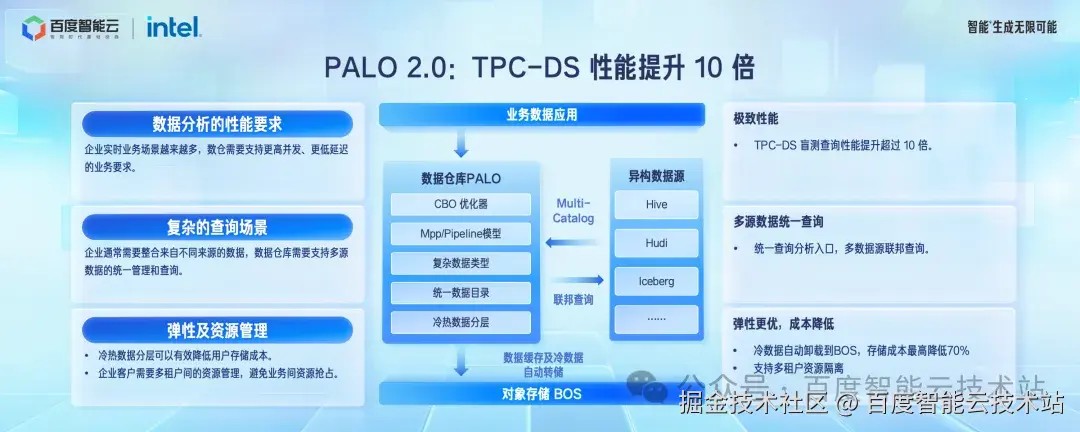
除了前面介绍的各种引擎的能力,平台的作用也非常大,他是决定数据平台是否好用,智能的关键。这部分主要有三个关键的平台。
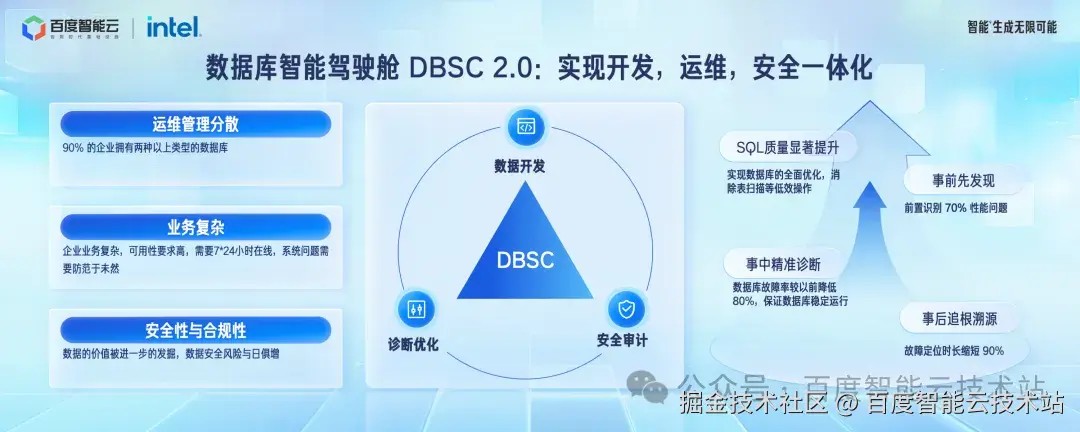
第一个是 DBSC,一站式数据库的 Devops 平台,实现数据库的开发,管理一体化。
第二个是 EDAP,大数据领域的,实现湖仓一体化开发治理平台,实现开发、治理、运行的一体化。
- 第三个是 DBStack,这个是数据库的私有化输出平台,支持多云多引擎。是全新推出的数据库轻量化平台。

DBSC 2.0 版本,相比 1.0 支持智能诊断等能力的基础上支持了数据库开发、安全审计等能力,实现了开发、运维、安全的一体化。同时在 1.0 支持MySQL的基础上,支持了如 GaiaDB,Redis ,openGauss 等十多种数据库。
数据湖,湖仓一体化是大数据领域最新的方向。
除了传统结构化数据的处理增强之外,随着大模型的出现,我们观察到业界有几个明显的趋势。
首先是大模型能更好的处理非结构化数据,所以带来非结构化数据的需求增多。
这也就带来了第二点,由于非结构化数据处理增多,大数据和 AI 之间非常多的能力需要打通和结合。
- 第三个特点是大数据平台原来都是一系列散件,有各类处理能力,开发和处理是分开的。但是对用户来说,一个简单的,容易使用产品是刚需,所以整个业界的整体趋势都是往一体化方向发展,给用户提供完整的开发体验统一的数据湖管理、数据治理的能力。
今天非常高兴宣布我们的 EDAP 2.0 发布,2.0 版本提供了四个方面主要的能力,
首先是数据湖的能力增强,全流程都支持非结构化数据治理,包括数据接入,元数据发现,血缘管理等等。
第二个是和 AI 平台深度打通,通过 EDAP 和 BML 的打通,实现了大数据、AI 在回到数据的闭环。
- 第三个是一体化的平台实现湖仓管理和开发治理的一体化,并且支持 Iceberg、Hudi、Deltalake 等主流格式。
- 第三个是计算引擎层全流程支持 serveless,包括数据集成、数据开发如 spark,flink,jdbc 等,以及数据分析和数据服务。
大家会发现,EDAP 2.0 从数据类型、执行能力、管理能力上都有非常大的提升,实现了更智能,更高效的湖仓一体化治理平台。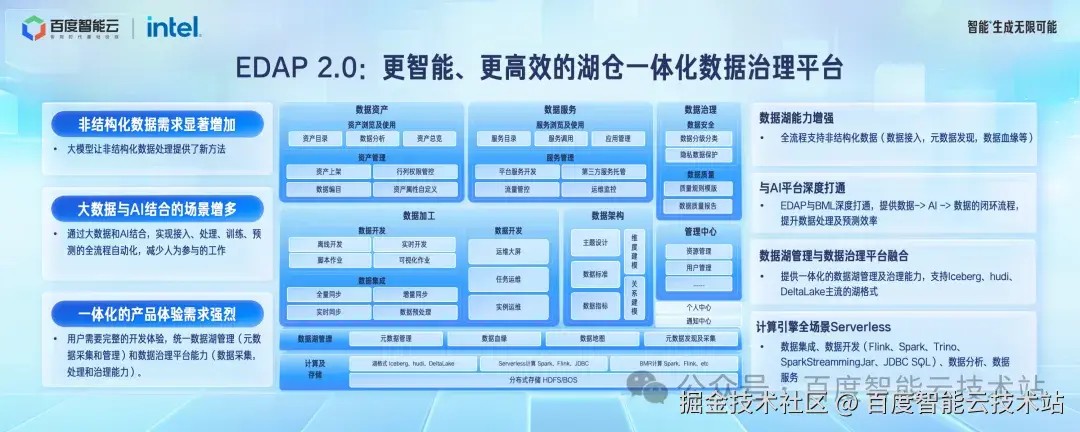
第三个平台是数据库平台 DBStack。
公有云上提供关系型数据库、NoSQL、数仓、数据开发工具等全套能力。私有化场景下,更多的厂商都是提供单一的产品。产品矩阵相比公有云可以说欠缺较多。但是私有化客户业务同样复杂,需要全套的能力。
DBStack 发布 1.0 就是补充这个 GAP,是目前业界唯一能提供完整数据库,包括开源、云原生、和商业数据库,还支持跨云,多云和混合云部署的能力管理平台。
DBStack 的诞生就是让客户不再受制于环境,可以享受到公有云一样的产品能力。
前面介绍了一系列数据库、大数据产品的重点更新。百度智能云提供一站式云原生数据底座,覆盖完整的数据库的关系型、NoSQL、工具、大数据的开发工具,离线计算,在线中间等全套产品和服务。
百度智能云的云原生数据底座也在持续演进,给客户提供更快、更强、更智能、更易用的能力,使能大模型业务,满足百行千业客户的诉求。
谢谢大家,我今天的分享就是这些。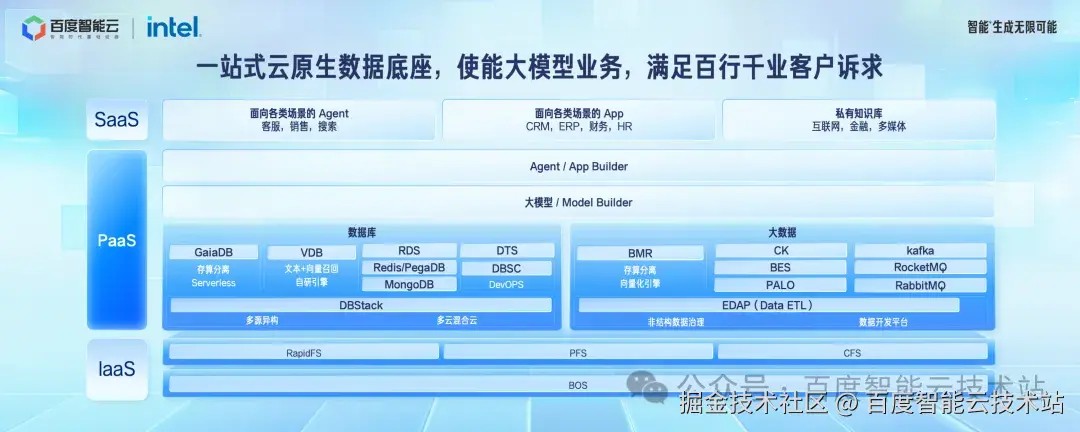
相关文章推荐
发表评论
关于作者

- 被阅读数
- 被赞数
- 被收藏数
登录后可评论,请前往 登录 或 注册