7种大模型风险及API 管理应对策略
作者:运维先锋2024.10.25 15:48浏览量:540简介:大模型(LLM)的发展带来的技术红利,本文来探讨如何通过 API 管理策略有效防范LLM的风险。
概况:大模型(LLM)的发展带来的技术红利,以及企业业务逐渐向AI转型,LLM 常见的安全漏洞、网络攻击手段变化已经成为企业要迫切关注的问题,本文来探讨一下,如何通过 API 管理策略有效防范LLM的风险。
近年来,随着大型语言模型技术的迅猛发展,各行各业对AI 应用或者业务与AI的结合的热情不断高涨。然而,无论是哪一种新兴的技术的出现,都不可避免地给使用者会带来或者暴露出新的安全漏洞问题。
那么下面,我们将结合 OWASP(Open Web Application Security)项目中列出的七大 LLM 漏洞,逐一分析和探讨一下有哪些 API 管理策略,可以用来应对这些风险的具体措施。例如:提示注入或不安全的输出处理,解释网络攻击者如何利用这些弱点等等,以及根据实际情况,实施哪些 API 管理策略可以预防这些安全威胁。
第一种:提示注入攻击
提示注入是指攻击者通过精心构造的恶意提示,诱骗生成式 AI 模型输出意料之外的内容。如果不对传递给 LLM 的提示进行限制,攻击者可能会构造恶意请求,导致模型产生不合预期的结果。例如:原本应该帮助用户的聊天机器人,可能突然转而对用户进行辱骂。
为防止这类攻击,开发人员应首先实施严格的身份验证和访问控制,确保只有授权用户才能与 LLM 交互。
此外,在将请求发送给模型之前,必须进行提示内容的检查。可以通过前后处理器来限制 LLM 的响应行为,或使用模板化的请求将实际输入限制在安全的参数范围内。也可以选择自有训练的 LLM 或使用第三方服务来审查提示请求及模型的响应内容,以确保安全。
第二种:不安全的输出处理
如果盲目信任 LLM 返回的响应,可能会无意中暴露后端系统,导致跨站脚本攻击、跨站请求伪造、服务器端请求伪造、权限提升或远程代码执行等安全问题。
应对这一风险的首要措施是进行提示范围限制,确保 LLM 的提示内容被控制在一个安全范围内。另外,响应内容在返回用户前必须经过严格审查。可以通过简单的正则表达式检查,或使用更为复杂的 LLM 自检机制,过滤潜在的有害内容。
第三种:模型拒绝服务攻击
当大量请求涌向 LLM 时,可能会导致服务性能下降或资源成本激增,这对企业来说是最不愿面对的结果。模型拒绝服务攻击正是基于这一原理:攻击者通过触发大量资源密集型操作,如生成过多任务或重复提交冗长的输入,造成模型资源消耗过高。
为防止这种攻击,企业应实施身份验证和授权机制,防止未经授权的用户访问 LLM。同时,还应对每个用户的令牌使用量进行限制,避免用户迅速耗尽组织的资源,导致高额的成本和计算资源的浪费,进而引发系统延迟。
第四种:敏感信息泄露
合规性团队对 LLM 的敏感信息泄露问题尤为关注,因为一旦发生,可能导致未经授权的数据访问、隐私泄露和严重的安全事故。
开发者可以通过使用专门训练的 LLM 服务来识别并屏蔽或模糊处理敏感数据,避免其被不当输出。这种方法不仅适用于 LLM 场景,也可以应用于其他非 LLM 的数据处理场景。此外,开发者还可以对 LLM 进行约束,指示其不返回特定类型的数据,从而有效降低敏感信息泄露的风险。
第五种:不安全的插件设计
如果对访问控制不严或输入处理不安全,系统可能会面临不安全的插件设计问题。这种风险通常发生在用户与 LLM 交互时,由模型自动调用的插件未经适当审查,允许攻击者构造恶意请求,触发各种不良行为。
为降低这种风险,首先要通过身份验证和授权机制,限制访问 LLM 的用户和操作,防止未经授权的插件调用。同时,还需要对提示请求进行严格的清理和控制,确保系统只允许安全的操作执行。
第六种:过度自主性
当 LLM 系统被授予过多的功能、权限或自主权时,可能会执行一些超出预期的操作,导致不可控的后果。
要应对这一威胁,开发者需要对系统进行持续监控,确保对所有与 LLM 交互的操作都有清晰的可见性。使用流量监控工具能够帮助企业实时了解哪些操作正在与 LLM 交互,并通过严格的授权机制限制敏感操作,确保系统安全运行。
第七种:过度依赖
过度依赖 LLM 可能导致信息误导、沟通错误,甚至因生成的内容引发法律或安全问题。尤其是当系统授予用户或其他子系统过多的自主权时,这类风险更加突出。
为降低这种风险,开发者应通过身份验证和授权机制对 LLM 的访问进行严格控制,特别是在敏感操作方面,需设置更高的访问权限。类似于过度自主性问题,企业也应对流量进行监控,确保交互操作的安全性。同时,需使用提示控制机制,限制用户与 LLM 的互动方式,以减少潜在风险。
LLM 的访问方式主要通过 API 调用实现,因而应对 LLM 可以实施与传统 API 流量相同的安全管理策略。研发部门可以通过实施纵深防御策略以及建立全面的流量监控机制,这样可以清晰掌握系统中流量的流动情况,并且确保 LLM 的安全使用。
基于AI 网关的大模型API管理策略实践
更进一步来说,选择具备专业集成能力的 AI 网关,能实现精细化管理 AI API 流量中的各种细节,有效增强系统的安全性。现在比如热门的Kong、APIPark等等开源AI网关项目也在进行探索,帮助企业更好地管理好LLM。
 ragmentbodyhtml.jpg">
ragmentbodyhtml.jpg">
如何部署AI网关
步骤 1:在5分钟内部署开源 AI网关。
代码仓:https://github.com/APIParkLab/APIPark
教程:跳转
APIPark 开源AI网关是基于Go语言开发,拥有强大的性能,开发和维护成本较低低。
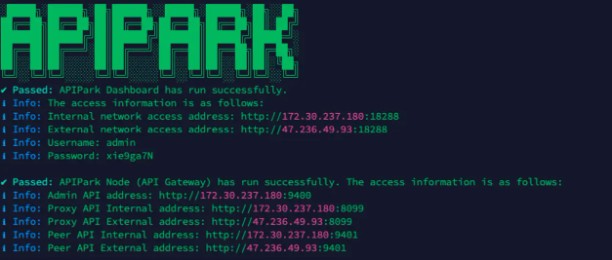
只需一行命令即可完成AI网关的部署。
curl -sSO https://download.apipark.com/install/quick-start.sh; bash quick-start.sh
按照提示进行部署即可,部署完成后,将会展示部署信息,如下:
步骤 2: 调用大模型 API
在具体的API管理实践中,选择kong、或者APIPark这类具备高集成能力的AI网关,借助AI的多层防护机制,企业可以将模型的调用控制与身份验证机制结合,确保了每次AI模型API调用都符合企业内部监管要求。
通过AI 网关流量限制、用户权限管理等功能,不仅能有效防范提示注入等外部攻击,还能有效保证研发部门在处理高频模型请求时避免资源超负荷,保持模型性能的稳定。
整体而言,企业在面对不断演进的对大模型外部的安全挑战时,选择专业化的AI网关作为安全防护策略,能有效增强API安全性和提升业务韧性。
相关文章推荐
发表评论
关于作者

- 被阅读数
- 被赞数
- 被收藏数
登录后可评论,请前往 登录 或 注册