让存储迈入百万 IOPS 时代,百度智能云用户态网络协议栈 Polar 全景解读
作者:xxinjiang2025.11.10 15:45浏览量:369简介:百度智能云用户态网络协议栈 Polar 全景解读
传统内核网络协议栈诞生于以通用性、兼容性与内核资源隔离为首要目标的时代:它通过在内核空间实现协议栈,并向用户空间暴露如 BSD Sockets 这类统一 API,为各种异构应用和硬件平台提供标准化、兼容性的接口;同时,采用系统调用与内存空间隔离等机制,确保应用之间、应用与内核之间的资源隔离。这些设计极大地增强了协议栈的通用性和兼容性,提升了多应用环境下的安全性和稳定性。
然而,时过境迁,如今云数据中心的规模早已不可同日而语,在其所面临的高并发、高带宽、低时延场景下,上述内核设计带来了显著的性能瓶颈:频繁的系统调用与上下文切换、多次数据拷贝、锁竞争与缓存失效共同放大了数据处理时延;协议栈的高度通用性和兼容性设计,也使其难以针对高性能计算、分布式存储、分布式数据库等特定应用场景进行深度优化。
面对上述云原生时代的网络性能挑战,业界迫切需要一种既能突破传统内核协议栈性能瓶颈,又能保持工程可用性及生态兼容性的解决方案。百度智能云 Polar(Polling-accelerated RPC-oriented Improved Stack)正是一套为此而生的解决方案,它包含两大核心组件:
Polar-TCP:本文重点介绍对象,它构建了「用户态驱动 DPDK(Data Plane Development Kit) + 用户态协议栈 + 工业级 RPC 框架 BRPC(Baidu Remote Procedure Call)」的全用户态链路,旨在通用网络环境下,实现接近 RDMA 的极致性能,并保持对现有 TCP 生态的广泛兼容。
Polar-RDMA:作为补充,在专用网络等受控环境中,为对性能有极致要求的场景提供额外的硬件加速路径。
针对分布式存储、分布式数据库等核心云服务,Polar 能够提供远优于内核协议栈的网络通信能力,以及良好的可扩展性,助力存储服务迈入百万 IOPS 时代。
本文将聚焦于 Polar-TCP,阐述其如何通过 Polling 线程模型改造和端到端零拷贝等设计,在数据面实现内核旁路,突破内核协议栈在吞吐与时延上的结构性瓶颈;同时在生态面实现协议兼容,继承传统协议栈的既有生态。
解决方案关键词:
数据面内核旁路(用户态协议栈 + 基于 DPDK 的用户态驱动) + 生态面协议兼容(非 TCP 协议仍走内核)=> 性能突破兼具生态兼容
轮询(Polling)模式驱动的 RTC(Run To Completion)每线程自治架构 => 高性能无锁并行处理
用户态协议栈 + BRPC数据结构重构 => 端到端零拷贝
基于 BRPC 深度性能优化 => 应用性能更进一步
解决方案关键词:
- 数据面内核旁路(用户态协议栈 + 基于 DPDK 的用户态驱动) + 生态面协议兼容(非 TCP 协议仍走内核)=> 性能突破兼具生态兼容
- 轮询(Polling)模式驱动的 RTC(Run To Completion)每线程自治架构 => 高性能无锁并行处理
- 用户态协议栈 + BRPC数据结构重构 => 端到端零拷贝
- 基于 BRPC 深度性能优化 => 应用性能更进一步
- RDMA(Remote Direct Memory Access)协议扩展 => 支持按场景选路
1. 行业背景与挑战
1.1. 云时代的网络瓶颈:从传统内核路径说起
在云原生负载全面升级的当下,网络已从够用即可的通道,变为决定业务性能天花板的关键基础设施。随着云存储追求更高并发与带宽、数据库等服务对低时延要求日益苛刻,传统内核协议栈的多重性能瓶颈被逐步放大:频繁的系统调用触发用户态与内核态的陷入切换,带来调度与 TLB(Translation Lookaside Buffer)失效开销;网络收发在硬中断、软中断与进程上下文间反复切换,带来切换开销;数据在用户缓冲区与内核缓冲区间多次拷贝,带来拷贝开销;多线程共享的队列结构与锁机制引发跨核竞争,严重影响 CPU 缓存局部性。这条路径在功能完备与兼容性上无可替代,却并非为高并发 + 低时延的数据中心工作负载而生。
如下图 1 所示,内核收发数据的长链路意味着,当连接数、QPS(Queries Per Second)与带宽逐步增加时,任何一个环节的轻微退化都会被放大成系统性抖动。于是,我们需要一种既能缩短数据面路径,降低上下文切换、拷贝、加锁等开销,又能保留工程可用性的方案。
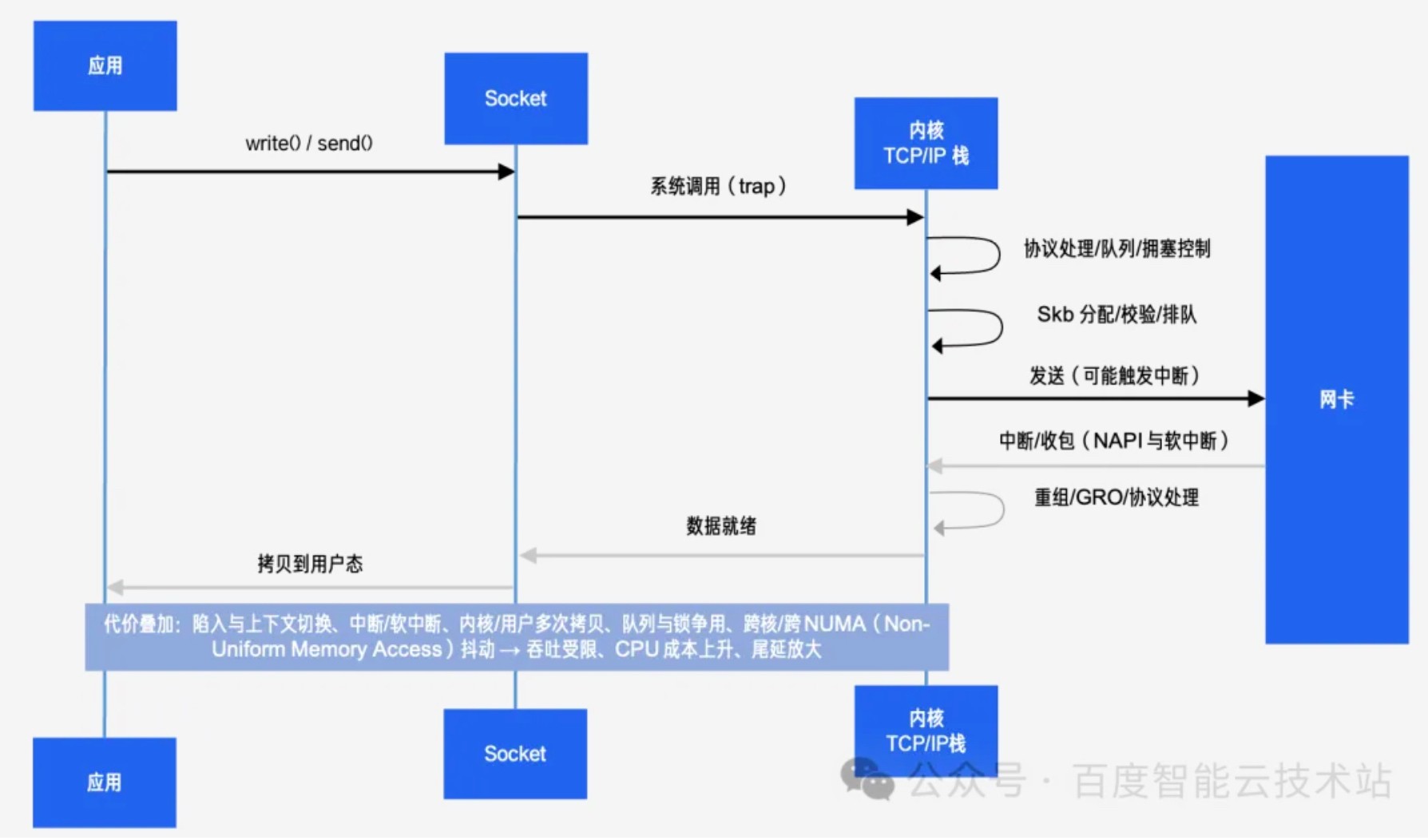
图 1 传统内核路径多次陷入/中断/拷贝的长链路
1.2. RDMA 的答案与难题:极致性能的另一面
在专用网络或受控集群内,RDMA(Remote Direct Memory Access)协议针对上述难题给出了极具吸引力的答案:通过 DMA(Direct Memory Access)将数据直接送达用户态缓冲区,数据面近乎零拷贝;以轮询 CQ(Completion Queue)替代频繁中断,缩短处理链路;将部分传输与重传能力下沉到硬件,显著降低单位吞吐的 CPU 占用。得益于上述优势,RDMA 在带宽与时延上的表现常常优于内核 TCP,尤其适合高并发与对时延极度敏感的场景。相较之下,传统 TCP 协议的优势在于通用性及跨域运维能力,方便沿用既有的四层负载均衡、服务治理、安全与观测体系。两者并非对立,而是面向不同工程边界的互补选择。
在大规模云环境中,要稳定兑现 RDMA 性能,需要对网络域及资源采取更精细的工程化措施:以 RoCEv2(RDMA over Converged Ethernet v2)为例,为解决 HOL(Head-of-Line)阻塞问题,往往需要在交换机侧实现基于 PFC(Priority Flow Control)/ ETS(Enhanced Transmission Selection)/ ECN(Explicit Congestion Notification)的拥塞管理策略。而且多租户环境下,内存注册、保护域与 keys 的管理成本会随连接数增长而快速攀升,网卡侧 QP(Queue Pair)/ CQ 资源与页表缓存亦需合理规划。
更为关键的是,RDMA 的这些优化措施往往要求网络环境具备较强的可控性和一致性。在企业级部署中,这意味着不仅需要统一的网络设备型号、一致的固件版本、标准化的配置模板,还需要成立专门的运维团队来维护这套精密的网络基础设施。正因如此,如何与现有的基础设施协同,并在跨 AZ(Availability Zone)或跨机型等复杂场景下持续保障网络环境的一致性,成为了使用 RDMA 的工程门槛。因此,RDMA 方案并不能普适推广至所有场景。
综上,RDMA 在云上更像是一把场景利器:在受控专用网络或特定业务场景下表现出色,但无法成为面向全量场景的通用解决方案。
2. Polar 的诞生:在通用性与极致性能之间,找到可规模化的路径
2.1. 设计思路
2.1.1. 工程目标
在上一章节中我们看到:传统内核路径在高并发 + 低时延场景下存在长链路放大效应,RDMA 则以更短路径与硬件卸载取得极致性能,但在大规模云环境中对网络域、资源与生态提出了更高要求。
面对此种行业难题,答案并非在「内核 TCP 与 RDMA」之间二选一,Polar 的设计思路是提供一个可灵活选择的、能够规模化的工程路线:
以 Polar-TCP 为核心:在数据面重构关键数据通路,获得接近 RDMA 的性能;在生态面复用 TCP 的成熟能力,为绝大多数云上场景(如多租户、跨 AZ)提供兼具高性能与兼容性的通用解。
以 Polar-RDMA 为补充:针对网络环境可控的专用集群,提供硬件加速选项,以追求极致性能。
通过这种组合,Polar 将选择权交给业务,使其可以根据不同场景的工程边界,在通用性与极致性能之间做出最合适的选择,实现真正的可规模化落地。
2.1.2. 技术路线
基于上述目标,Polar-TCP 构建了「用户态驱动(DPDK)+ 用户态协议栈 + 工业级 RPC 框架(BRPC)」的全用户态链路,数据面因此变得足够短、足够高效:
DPDK 直连网卡:旁路内核中断与拷贝,同时利用 Csum 计算卸载、TSO(TCP Segmentation Offload)、GRO(Generic Receive Offload)等硬件卸载技术,进一步释放 CPU 压力;
基于用户态实现轻量级 TCP 栈:采用基于 Polling 的 RTC(Run To Completion)模型、线程资源独享,最大限度消除锁与跨核访问开销;
深度打磨 BRPC:打通数据从 RPC 应用到协议栈的零拷贝路径,引入高效序列化算法,打造性能强劲的 RPC 框架。
结合上述优化手段,最终可实现吞吐与时延性能的跨越式提升,支撑分布式存储等核心业务迈向百万级 IOPS,显著降低 CPU 消耗。
同时,考虑到云上环境的规模化部署,Polar 在工程层面亦做了系统化设计:
存量兼容性:Polar-TCP 与传统内核 TCP 协议完全兼容,可实现无缝互通。业务可在对端无感知的情况下逐步切换至用户态 TCP 实现。
模块化设计:将拥塞控制算法和硬件卸载功能设计为可插拔模块,支持根据具体的网络环境和业务需求进行灵活组合。例如,在高延迟网络中可选择 BBR 拥塞控制,在数据中心内网可启用硬件 TSO 卸载。
多环境部署:支持主流网卡型号,可部署在物理服务器、容器、虚拟机以及 DPU 等不同计算环境中,满足多样化的基础设施需求。
RDMA 加速路径:针对网络环境可控且对性能有极致要求的场景,提供 Polar-RDMA 选项。通过智能路径选择,在保持大规模运维能力的同时进一步提升网络性能上限。
注:智能路径选择,即面向公网/跨AZ/多租户的前端流量采用 Polar-TCP,获得高吞吐与低时延并保持广泛兼容;在同 AZ、网络域可控的后端存储/计算集群上采用 Polar-RDMA 最大化时延与带宽上限。以百度智能云分离式存储网络为例:前端使用 Polar-TCP 承载海量 RPC 和 I/O 请求,后端使用 Polar-RDMA 完成数据高效传输,两者优势互补,协同发挥作用。
2.2. 底层架构实现
本节将拆解 Polar 技术方案的核心实现,通过阅读此节内容,你将了解到百度智能云高性能网络团队是如何将前述理念一步步落地到真实物理系统的。
如下图 2 所示,下文我们会按照自下而上、从硬件驱动到协议栈再到 RPC 框架的顺序,逐步剖析构成 Polar-TCP 全用户态链路的三大组件:DPDK(详见 2.2.1 章节)、Polar-TCP (详见 2.2.2 章节)与作为统一应用层的 BRPC 框架(详见 2.2.3 章节)。
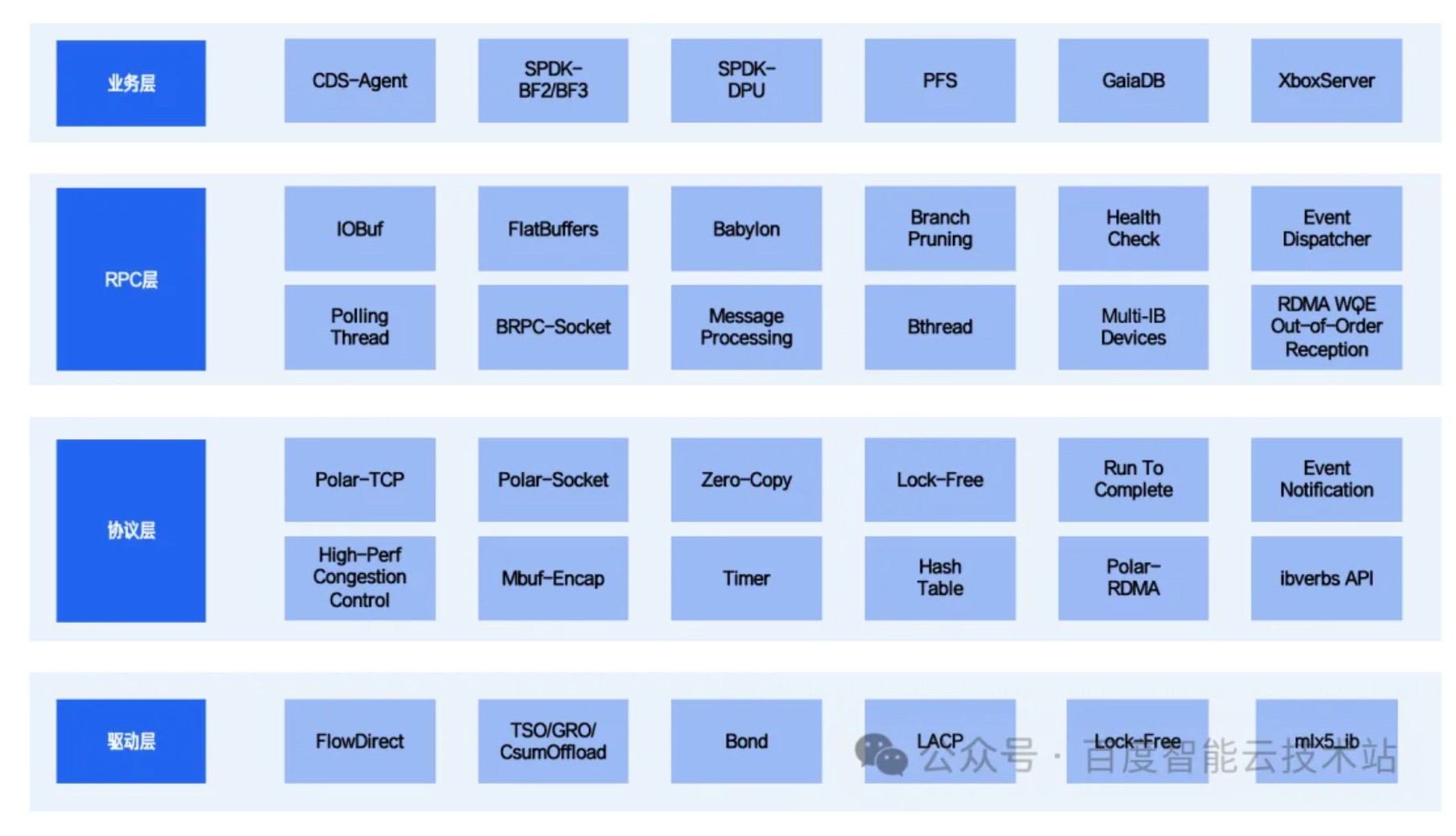
图 2 Polar 核心分层架构设计
2.2.1. DPDK —— 直达硬件极限
对于内核协议栈而言,数据包在内核和用户态之间多次拷贝、网卡与协议栈协同效率受限,影响高并发场景的性能上限。要让用户态链路真正跑起来,第一步是把数据包送得更快更稳。
本节聚焦 DPDK 用户态驱动,通过轮询与硬件卸载,使数据包可以绕过内核、直接在用户空间与网卡高速交互,降低延迟、释放 CPU,为 Polar-TCP 的高效传输奠定基础。关键实现概括如下:
智能分流(FlowDirect):单网卡部署时,通过 DPDK 下发特定分流规则(支持按端口、协议、连接状态等维度精细控制),实现对指定 TCP 流量精准接管。
硬件卸载支持:充分启用 TSO、GRO、Checksum Offload 等网卡特性,繁重工作交由硬件完成,进一步提升收发效率。
高可用支持:启用双口 Bonding 与 LACP(Link Aggregation Control Protocol),自动判别链路状态、分担流量,并与内核同步 LACP,兼顾带宽聚合与高可用。
广泛硬件/形态支持:适配 Mellanox(CX系列)、Intel(E810、82599)、博通等主流网卡,面向多租户/容器/虚拟化场景,覆盖物理机、DPU、容器等主流云服务器形态。
2.2.2. Polar-TCP —— 突破协议栈瓶颈
DPDK 直连硬件后,数据包进入用户态的路径变得更短,但要真正发挥性能优势,还需要在协议栈层面消除上下文切换、加锁及拷贝开销。
Polar-TCP 移植了 FreeBSD 协议栈的核心处理逻辑并进行精简,通过线程模型改造(Polling + RTC)、无锁化处理、端到端零拷贝、事件通知机制等技术,显著提升了数据路径的处理效率。同时,Polar-TCP 支持单端部署,保留了对传统内核 TCP 的兼容。下文将从核心架构设计与兼容性支持两方面展开介绍。
2.2.2.1. 核心架构设计
Polar-TCP 的核心架构设计着眼于解决云上业务面临的实际问题:在高并发场景下,传统协议栈的上下文切换和加锁开销会导致 CPU 资源大量浪费在协议处理本身,而非业务逻辑;数据拷贝则进一步加剧了延迟抖动,影响服务质量。这些问题直接转化为更高的资源成本和更差的用户体验。
Polar-TCP 通过线程模型改造、无锁化处理、端到端零拷贝、事件通知机制等核心技术,从根本上消除了这些开销。其带来的改变是直接的:网络吞吐提升数倍,时延抖动显著降低,CPU 得以将更多算力投入业务处理,最终体现为更少的服务器投入和更优的业务性能表现。
线程模型改造(Polling + RTC)
如图 3 所示,Polar-TCP 采用 Polling 模式的 RTC 处理机制,有效避免了传统事件响应带来的上下文切换开销,在高负载场景下能够得到更高的 CPU 利用率和更低的延迟。

图 3 Polar 线程模型示意图
核心实现要点如下:
进程启动时,创建 N 个 Polling Thread,每个 Polling Thread 上会被注入一组 poller 函数,这些函数会在主循环中被不断重复执行直至程序退出;
每个 poller 函数的单次运行时间是可控的,上层业务注入的 poller 函数是非阻塞的;
同一五元组的 TCP 连接对应的数据收、发工作在同一个 Polling Thread 上处理;
每个 Polling Thread 负责一对网卡接收/发送队列,完成数据包收/发工作。
注:Polling 是一种事件检测或任务调度方式,即程序或系统在不断循环中主动检查是否有事件或条件发生,然后做出响应。 RTC 是一种事件处理策略,RTC 强调事件处理必须一次性完成,在处理过程中不会被其他事件打断。
无锁化处理
Polar-TCP 通过如下技术手段,实现了近乎无锁的报文处理流程:
端口分配方案及分流规则设计:client 端采用 Per-Thread Per-Port 方案,server 端采用 port reuse 方案,配合不同的网卡分流规则,实现 Flow Affinity。即一组特定五元组连接的数据包只会被同一个 Polling 线程处理,避免了多线程之间的竞争和同步,极大提升了并发性能和cache命中率。
shared-nothing 支持:所谓 shared-nothing,即线程资源独享。以线程自治与内存/队列的局部性为原则,每线程独立管理数据与资源,原生支持多核并行场景,避免全局锁与跨核数据访问。
端到端零拷贝
- 发送方向:业务将可能发送的内存区预注册至 Polar-TCP 协议栈(预注册的内存区需提前锁住,防止物理页被操作系统移动),建立虚拟地址 → DMA 地址映射,发送时仅传输数据指针及其长度即可,消除业务 → 协议栈的数据拷贝动作,大致过程如下图 4 所示(注:图中的 IOBuf 是 BRPC 的核心数据结构,下文出现的 IOBuf 同理)。

图 4 Polar-TCP 发送方向零拷贝处理流程
- 接收方向:以 BRPC 应用为例,网卡收包后会将缓冲区数据直接上送 Polar-TCP,Polar-TCP 将数据封装为 IOBuf 后继续上送 BRPC,全程零拷贝。
事件通知机制
真正接入上层应用后,协议栈中会同时存在很多连接,但这些连接并非总是有数据需要发送或者接收。如果没有事件通知机制,协议栈将不得不依次检查所有连接,显而易见地,这在连接数较多时会给性能带来严重打击。
Polar-TCP 通过提供事件通知机制,可以指明一个连接是否有必要进行处理,具体实现思路为:
当有新的数据进入到一个连接的发送缓冲区且该发送缓冲区为空时,或有数据被ACK且发送缓冲区不为空时,意味着应发送新的报文,此时会产生事件,以便在下次发送数据时对该连接进行处理。
当一个连接的发送缓冲区可写或接收缓冲区可读时,会产生事件,以便在下次执行时将该连接拣选出来。
2.2.2.2. 兼容性支持
高性能协议栈的真正价值不仅在于技术先进性,更在于能否平滑落地到实际生产环境。Polar-TCP 的兼容性设计为业务平稳接入提供了重要保障,具体措施如下:
支持单端部署:兼容传统内核 TCP,实现了 Polar-TCP 与内核 TCP 的无障碍通信,在对端无感的前提下可单端部署、灰度放量。
提供类 socket 接口:实现 polar_socket、polar_send、polar_recv 等类 socket 接口,确保业务以最小改动成本接入高性能网络路径。
精简协议栈:删繁就简,只保留 FreeBSD TCP 的核心处理逻辑,兼容传统内核 TCP,非 TCP 数据交由内核处理,确保部署灵活性。
2.2.3. BRPC —— 高效应用交付
BRPC 作为 Polar 解决方案统一的应用层框架,其核心使命是将底层数据面的性能收益无损地传递给业务。为此,我们不仅需要为 Polar-TCP 路径进行深度优化,还需确保其能够高效承载 Polar-RDMA 路径,实现两条路径在 RPC 层的统一。
我们对 BRPC 的线程模型与数据通道进行了针对性重构:以 Polling+ RTC 的处理机制对齐底层协议栈,以 IOBuf 链式零拷贝打通应用到协议栈的路径,并对 BRPC 的序列化、健康检查与观测等方面做精简与优化,从而将数据面收益平滑传递到应用层,完成端到端性能收益兑现。核心实现思路概括如下:
线程模型改造(Polling + RTC)
重构 BRPC 线程模型,将 bthread 为核心的多线程异步模型改造为更契合用户态协议栈的轻量轮询模型,事件处理策略与 Polar-TCP 对齐。显著减少了线程切换与上下文开销,具备更低的时延与更高的 CPU 利用率。
端到端零拷贝
发送方向:BRPC 以 IOBuf 链的形式直接向下游 Polar-TCP 传递数据描述,避免在 RPC 层的二次拷贝与拼包/拆包中的冗余内存操作,形成「应用 — BRPC — Polar-TCP」的零拷贝快路径。
接收方向:Polar-TCP 收包后以 IOBuf 形式上送 BRPC,在解析阶段保持“引用传递”,若最终业务直接消费数据,则可形成端到端零拷贝链路。
BRPC 深度优化
序列化优化:引入更适用于高性能 I/O 场景的 FlatBuffers 协议,降低序列化/反序列化开销,同时保留对主流编解码(如 Protobuf)的兼容选择,便于平滑演进。
关键路径精简:聚焦高性能数据路径,简化无用分支;重写健康检查与故障探测逻辑,使其与轮询模型协同,减少对数据面 CPU 的扰动。
观测体系优化:引入 Babylon 指标体系替换原 Bvar 体系,在降低观测开销的同时,提供更细粒度的时延、队列与内存指标。
扩展性考量
API 与生态兼容:保持与社区 BRPC 使用习惯一致,服务定义与编解码器可沿用存量实践。
RDMA 增强路径:针对受控的专用网络场景,对社区 BRPC‑RDMA 进行改造,支持 WQE(Work Queue Element)乱序处理与多 IB 网卡并行,将 bthread 多线程模式切换为 RTC 轮询模式,实测带来 20%+ 的 RDMA 吞吐性能提升。
3. 工程落地与性能成效
在上述技术方案落地后,Polar 的价值从基准测试与真实业务两个角度分别得到了验证。
3.1. 基准测试
本节主要展示 Polar-TCP 的 benchmark 性能数据,测试数据以 kernel-tcp to kernel-tcp 模型为基准做了归一化处理。其中,测试平台采用AMD EPYC 7W83 处理器,内核版本为 Linux 6.6,网卡型号为 Mellanox ConnectX-6 Dx。
基于 Polar-TCP 的 benchmark 性能测试数据如下图所示,图中横轴 Mode 类型 k2k/k2p/p2k/p2p 分别对应 Client-Server 架构中的协议栈类型:kernel to kernel / kernel to polar / polar to kernel / polar to polar。其中
4k 读/写 IOPS 性能(图 5):
6 核 4k 随机写性能:Polar-TCP(p2p)是 kernel-TCP(k2k)性能的 4.9 倍。
6 核 4k 随机读性能:Polar-TCP(p2p)是 kernel-TCP(k2k)性能的 3.4 倍。

图 5 Polar-TCP benchmark 4k IOPS 性能(iodepth=512)
4k 读/写平均时延性能(图6):
4k 随机写性能:Polar-TCP(p2p)相较于 kernel-TCP(k2k)下降 52%。
4k 随机读性能:Polar-TCP(p2p)相较于 kernel-TCP(k2k)下降 52%。

图 6 Polar-TCP benchmark 4k 平均时延性能(iodepth=1)
3.2. 典型业务落地实践
如图 7 所示,依托于百度智能云多类核心云业务的深度集成,Polar 已在云盘、对象/文件存储、分布式 KV 与数据库等场景取得可观的性能与稳定性提升:
百度智能云块存储服务 —— CDS(Cloud Disk Service):接入 Polar-TCP,4 核 4K 随机写 IOPS 提升超 2 倍,8 核实现百万级 IOPS。
百度智能云文件存储服务 —— CFS(Cloud File Storage):接入 Polar-RDMA ,QPS 提升 16%,时延下降 50% 以上。
分布式 KV/检索/计算平台 —— 大商业 XBOX:容器化部署 Polar-TCP,单核极限 QPS 提升 60% 以上。
百度智能云数据库服务 —— GaiaDB 等:接入 Polar-TCP,QPS 较内核协议栈提升 2.5 倍以上,时延下降 50% 以上。

图 7 Polar 业务落地
4. 未来展望:重新定义云原生时代的网络软件栈
回顾网络技术的发展,我们能清晰地看到一条主线:硬件的性能潜力,必须由与之匹配的软件栈来释放。
今天的云数据中心,拥有着多核处理器、高速网卡和先进的内存架构,硬件层面早已为百万级 IOPS 和微秒级延迟的应用场景做好了准备。然而,以通用性为主要设计目标的传统内核协议栈,其固有的长链路、多拷贝和锁竞争等问题,成为了释放硬件潜能的封印。
面对日益分化的云原生工作负载,我们不再需要万金油式的通用产品,而是需要为特定场景打造的手术刀。这正是 Polar 的核心价值:它并非要取代内核,而是为分布式存储、数据库、AI 计算等核心负载,开辟了一条绕开内核瓶颈的高速专线。它代表了一种新的设计范式:以工作负载为中心,通过软件栈的深度定制,将硬件潜力精准转化为业务价值。
同时,Polar 通过提供 TCP 与 RDMA 双路径,将选择权交还给工程师,使其能根据不同场景的工程边界,在兼容性与极致性能间做出最优权衡,实现真正的规模化落地。
展望未来,我们将继续推动 Polar 与更广阔的生态开放合作,面向新一代 DPU、云原生数据库及大模型训练推理等前沿方向持续优化。我们的目标,是让高性能网络成为驱动所有 AI 及智能应用场景的普惠基础设施,为产业智能化转型赋能,最终在全局实现成本与效率的最优配置。
相关文章推荐
发表评论
关于作者

- 被阅读数
- 被赞数
- 被收藏数
登录后可评论,请前往 登录 或 注册