⻜桨⼤模型推理部署⾼性能优化
2023.08.03 14:44浏览量:3537简介:今天我们就介绍一下在大模型推理部署过程中的高性能优化方法。
这是 AI 大底座系列云智公开课的第 6 期内容。上一期我的同事给大家介绍大模型分布式训练过程中的优化方法,当大家完成大模型的训练后,接下来的工作就是需要完成上线部署,今天我们就介绍一下在大模型推理部署过程中的高性能优化方法。
今天将从如下三个方面开展开这次分享:
介绍大模型推理的背景、需求和难点;
介绍生成式大语言模型的推理部署高性能优化方法;
介绍文生图类多模态大模型的推理高性能优化方法。
1. 大模型推理的需求和难点
大家都知道近年来大模型一致保持着较高的关注度,像国外的 OpenAI、Google,国内的百度等都持续在大模型方向上做着长期的积累和探索。另一方面,在大语言模型上,随着去年年底 ChatGPT 这个爆款的发布,也引发了全民大模型的热潮,在国内百度首发了文心一言生成大模型,其后像阿里的通义千问、科大讯飞的星火也相继推出,国外也有像 Bard,ChatGLM 等模型陆续发布。而在多模态大模型上,文生图也是一个关注度很高的领域,百度也推出了文心一格文生图AI艺术和创意辅助平台,国外也有像 Stable Diffusion,Midjourney 等相关的应用推出。
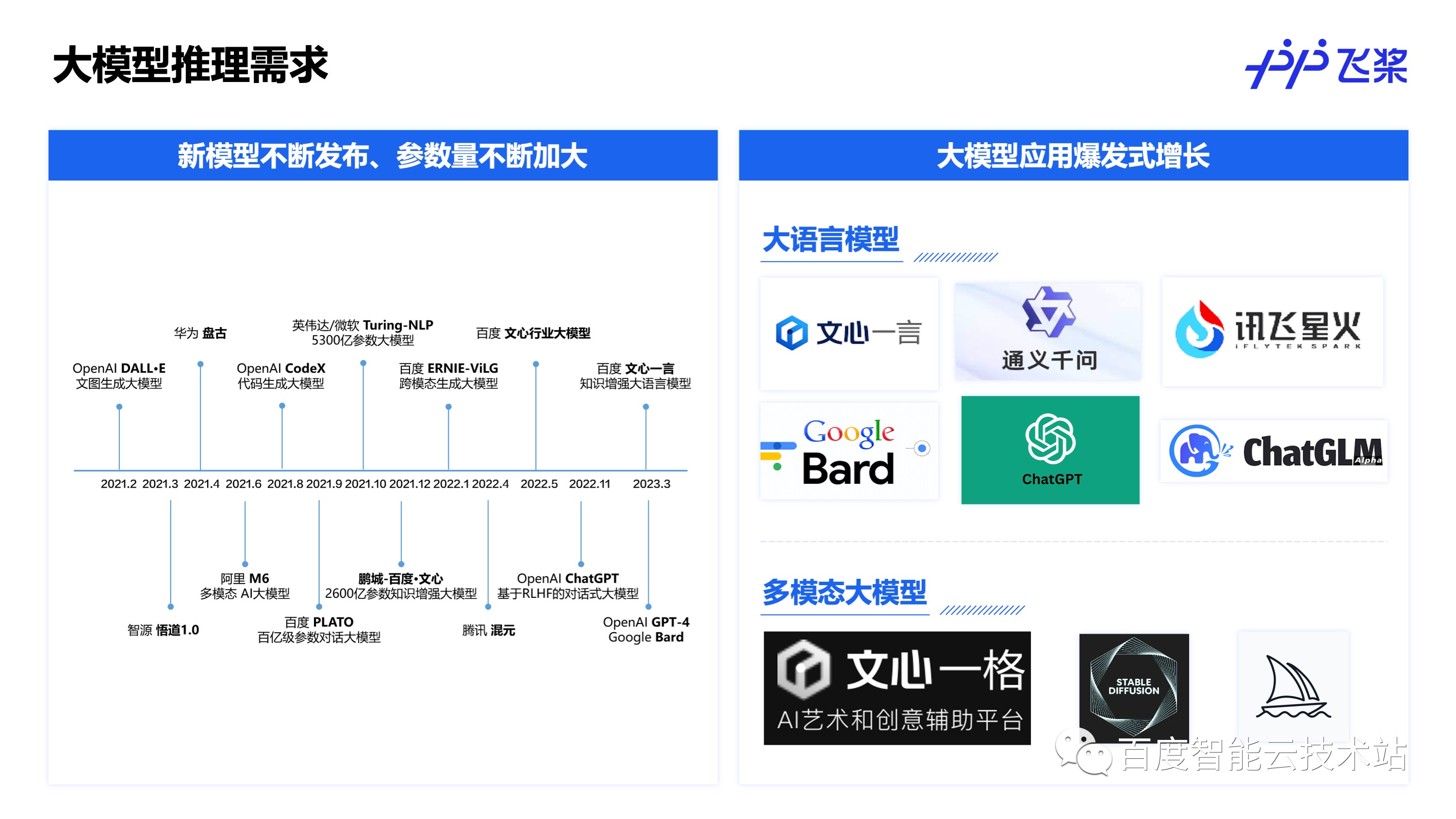
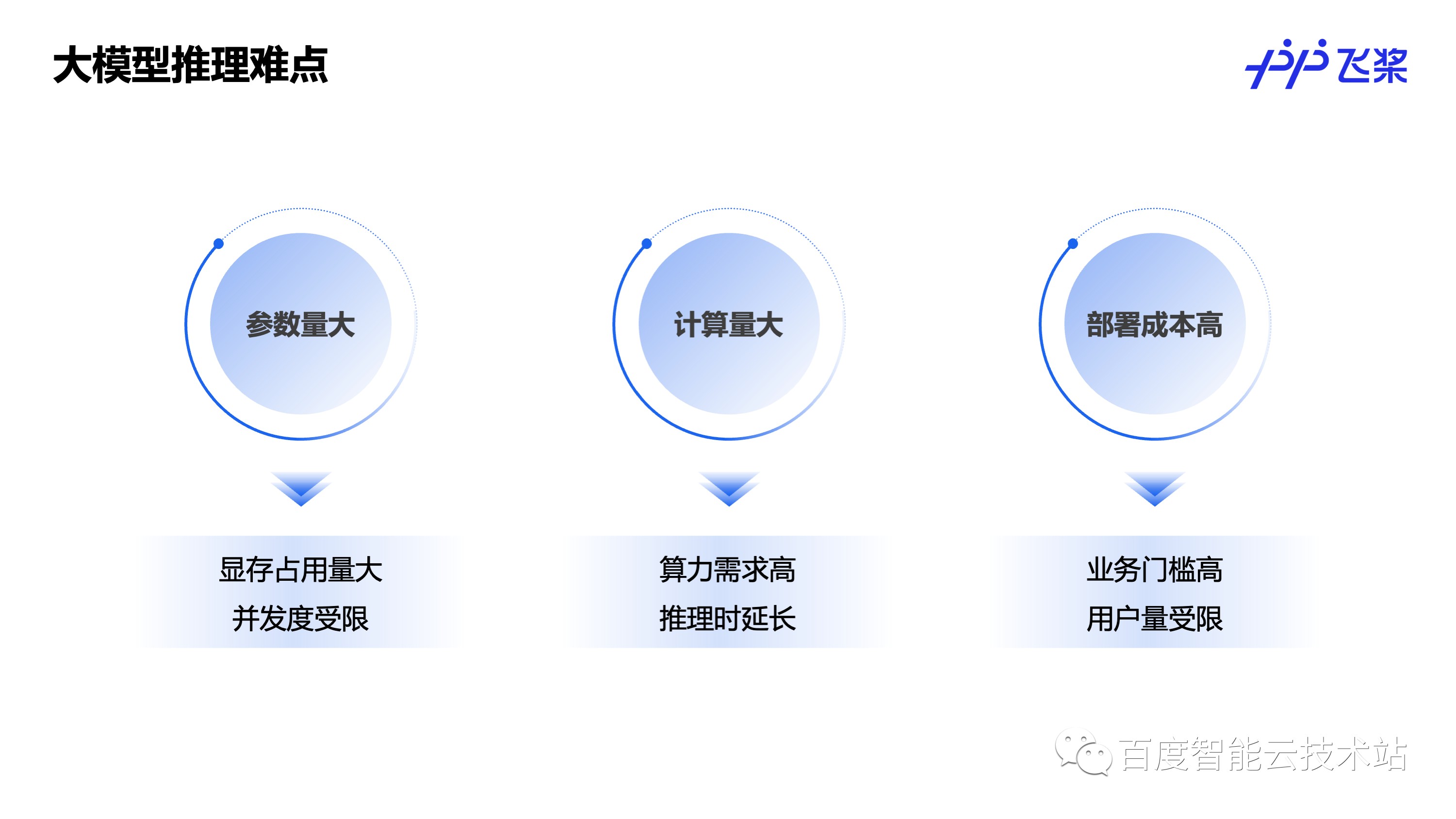
随着大模型相关的应用爆发式的增长,对大模型的线上推理部署需求也是越来越强烈,但是具体到去完成一个大模型相关的服务上线,又会遇到很多难点。对于大模型来说,优势是「大」,难点自然也是「大」。首先是参数量大,比如 175B 的GPT-3 模型,光权重就有 350GB 左右,权重会占用大量的显存,能顺利部署都是一大挑战,更别说提升部署的并发度了。
其次是计算量大,对算力的要求非常高,相应的推理时延也很长。由于「参数量大」和「计算量大」,大模型推理部署的成本就会非常高,使得业务想要接入、使用大模型的门槛会非常高,也会限制业务接入的用户量,像现在文心一言和 ChatGPT 都有用户需要排队的现象,就是因为部署成本高的原因。
鉴于大模型推理部署的强需求和部署过程中的难点,飞桨一直在致力大模型推理部署的高性能优化工作,下面就先介绍一下飞桨在大语言模型的推理部署上的高性能优化工作。
2. 大语言模型推理部署高性能优化
要进行生成式大语言模型的推理优化,首先我们来详细分析一下生成式大模型的推理过程。
2.1 生成式大模型推理流程分析
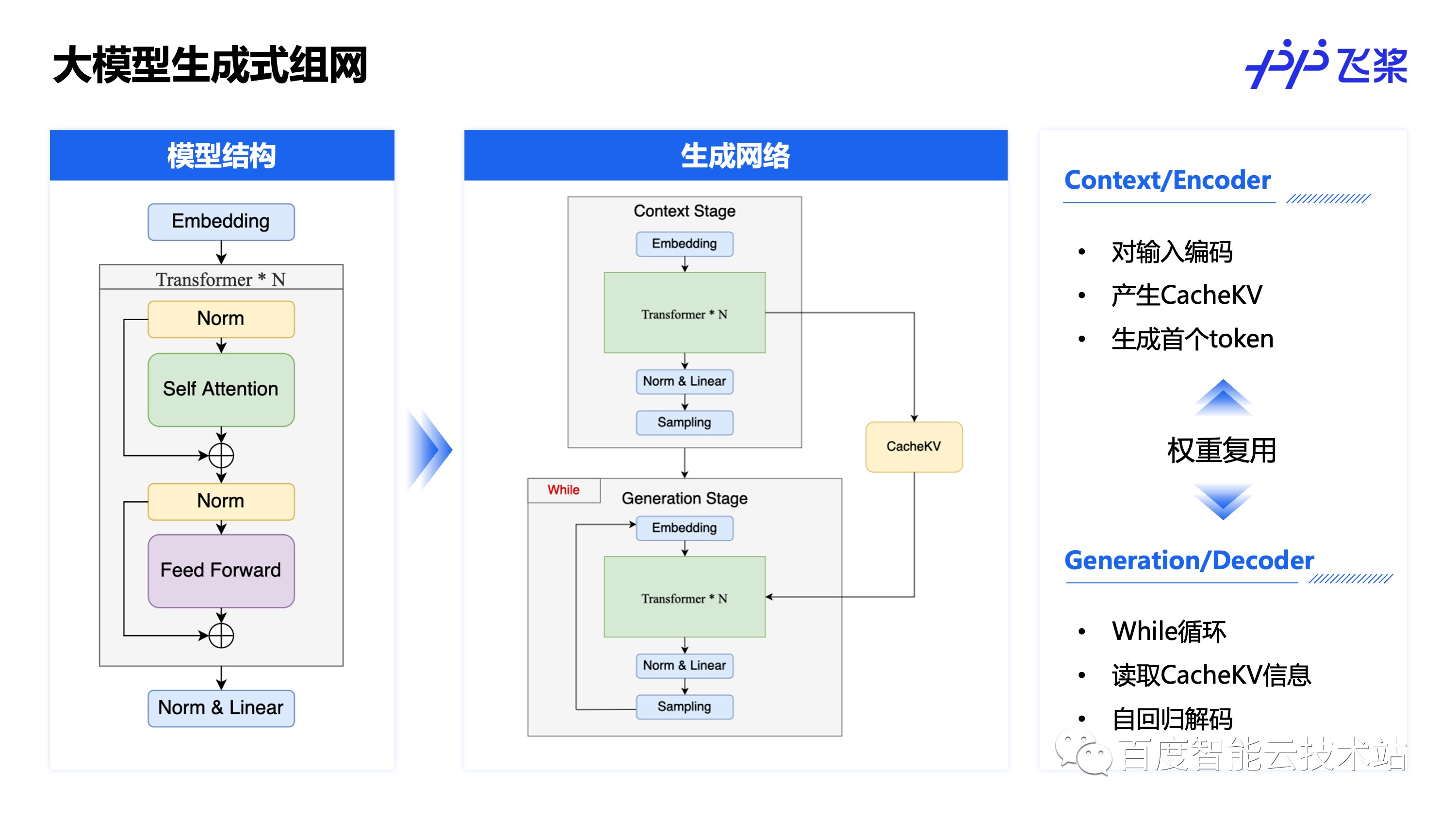
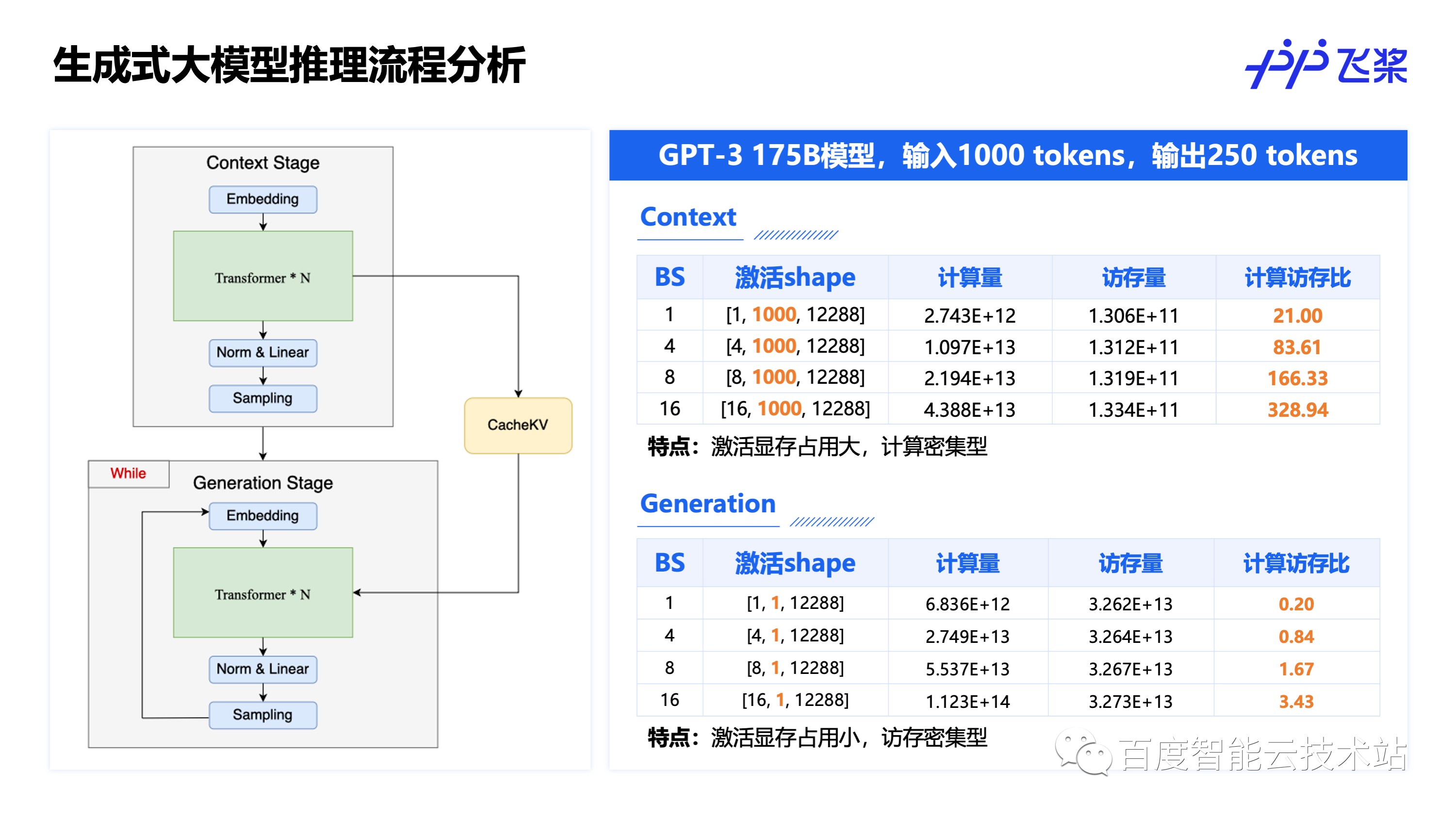
左边是一个常见的 Transformer 类大模型的结构示意图,用户问的问题一般会先经过预处理成为一系列的 token,这些 token 首先经过 Embedding 模型,可以理解为每个 token 会被转换成一个词向量。这一系列的词向量会进入多层 Transformer 结构进行计算,而对于每层 Transformer 结构,又可以划分成 Self Attention 和 Feed Forward(FFN) 两部分,这两部分前后一般会经过一个 Norm 结构,可以是 LayerNorm、RMSNorm、DeepNorm 等等,这样的 Transformer 结构会重复多次,一般被称为多层,比如 30 层,48 层 Transformer。完成了多层 Transformer 的计算之后,后再经过一个 Norm 和一个 Linear,这个 Linear 的输出就是我们常说的 logits 了,训练的时候后面再接一个 Softmax 和 Loss 就可以训练了。
如果是类似分类、检测这些传统任务,训练和推理的组网是一致的,主要的区别是最后是接 Loss 还是接 TopK,NMS 等,但是对于生成式任务推理组网却会不一样,可以看到推理过程中组网逻辑上分为两个阶段,Context 阶段(又称 Encoder)主要对输入编码,产生 CacheKV,在计算完 logits 之后会接一个Sampling 采样模块,采样出来第一个生成的 token,并将这个 token 和 CacheKV 作为 Generation 阶段(又称 Decoder)的输入,Generation 阶段在一个 While 循环里,读取 token 和 CacheKV 后通过自回归解码的方式每循环一次产生一个 token。
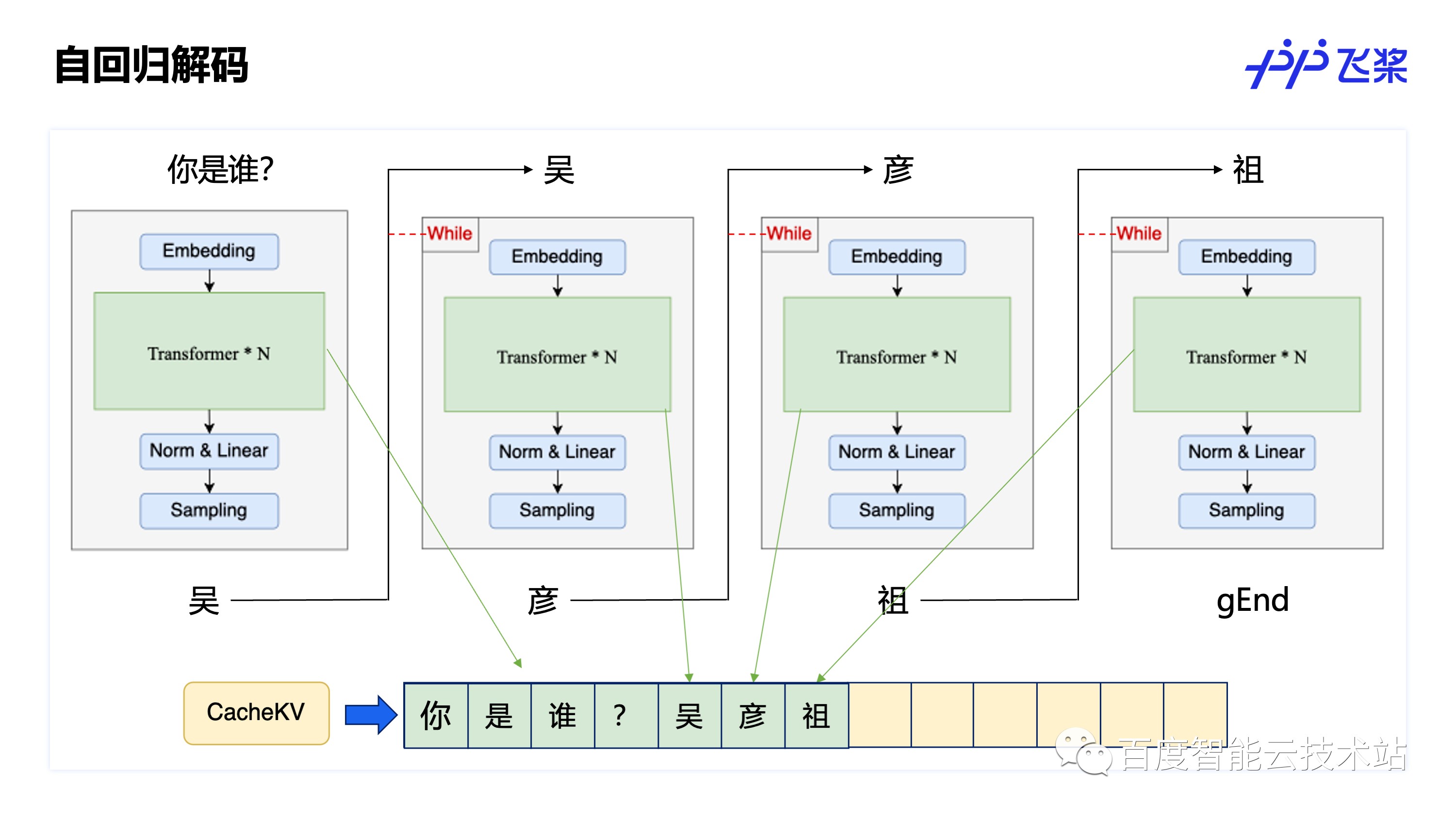
具体自回归解码的过程可以通过下图看出,假设输入「你是谁?」经过预处理变成 4 个 token,分别是「你」,「是」,「谁」,「?」,自回归解码流程如下:
这 4 个 token 会在 Transformer 计算时记录下 CacheKV 的信息(CacheKV 实际上记录的是 Transformer 中 Attention 模块中 Key 和 Value 的值)最终通过 Sampling 阶段采样出来第一个 token 为「吴」;
Context 阶段生成的 token “吴”会作 Generation 阶段的输入,「吴」在 Generation 阶段的 While 循环出判断,While 判断生成没有结束,执行 While 中的计算,计算中会在 Attention 中计算出「吴」对应的 CacheKV 信息存储下来,并拼接上所有的历史 CacheKV 信息进行计算,最后采样出来下一个 token 为「彦」;
「彦」传回来作为 Generation 输入再次执行,自己的输出作为自己的输入,不断回归迭代,就是「自回归」,同样在 While 处判断需要继续生成,计算和拼接 CacheKV 信息并采样出下一个 token 为「祖」;
最后在把「祖」作为输入生成下个 token 为「gEnd」, 「gEnd」为一个特殊的 token,用来标识生成结束,While 循环检测到「gEnd」生成结束,就会退出循环,本次生成推理过程结束。
了解了大模型推理过程的生成流程之后,我们再来详细分析一下这个生成过程。
以 175B 的 GPT-3 模型,输入 1000 个 token,生成 250 个 token 为例,那么 Context 阶段的激活 Shape 为 [B, 1000, 12288],其中 B 为 batch_size,第二维为输入 token 数,第三位为 hidden size。而对于 Generation 阶段,由于每次输入输出都是固定的 1 个 token,是通过循环多次来产生多个输出 token,所以 Generation 阶段的激活 Shape 的第二维始终为 1,Generation 的激活显存占用是远小于 Context 阶段的。
再来看计算量,这里可以看到挺多有趣的结论:
Context/Generation 的计算量均随 batch size 增大而正比增大,这个很好理解,因为 batch 内每个样本的计算量是一致的;
Context/Generation 的访存量随 batch size 增大却基本不变,访存量可以分为权重访存和激活访存,很显然激活的访存是随 batch size 增大而增大的,但是权重访存却不会随 batch size 变化而变化,而由于激活的访存量远小于权重的访存量,就会出现总访存量几乎不随 batch size 变化而变化;
Context 是计算密集型的任务,而 Generation 是访存密集型的任务,这是由于 Context 的计算量大,但是 Generation 由于每次都只计算 1 个 token,所以计算量远小于 Context,但是权重的访存量确实一致的,所以 Generation 阶段反而是访存密集型的任务。
经过上述分析,大家了解了大模型生成过程的流程和计算量,我们再来看一下大模型推理的常见优化方法。
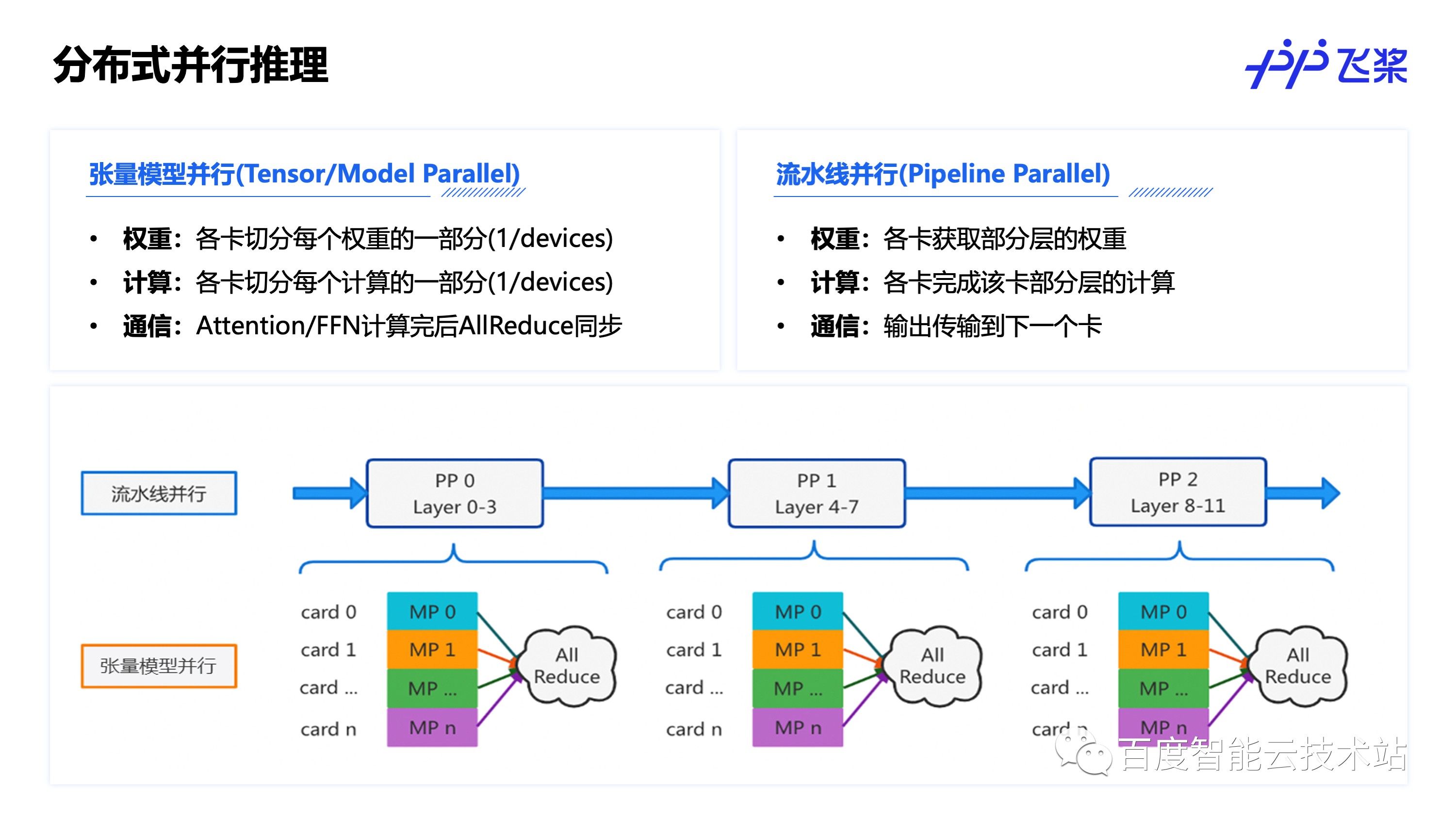
首先是分布式并发推理,由于大模型权重较大,经常出现单卡放不下的现象,因此通过分布式多卡并发的方式是常见的实现大模型推理可行性的方式。推理过程中的分布式并发和训练过程类似,常用的有张量(模型)并行和流水线并行两种方式,其中张量并行是将每个权重和相关计算都切分到多卡上,并在每次 Attention 和 FFN 计算完成后通过卡间通信来汇总计算结果,而流水线并行则是通过将不同层的权重和计算切分到多卡上,每次推理通过流水线的方式依次在各卡上完成推理。
2.2 推理时延优化方法
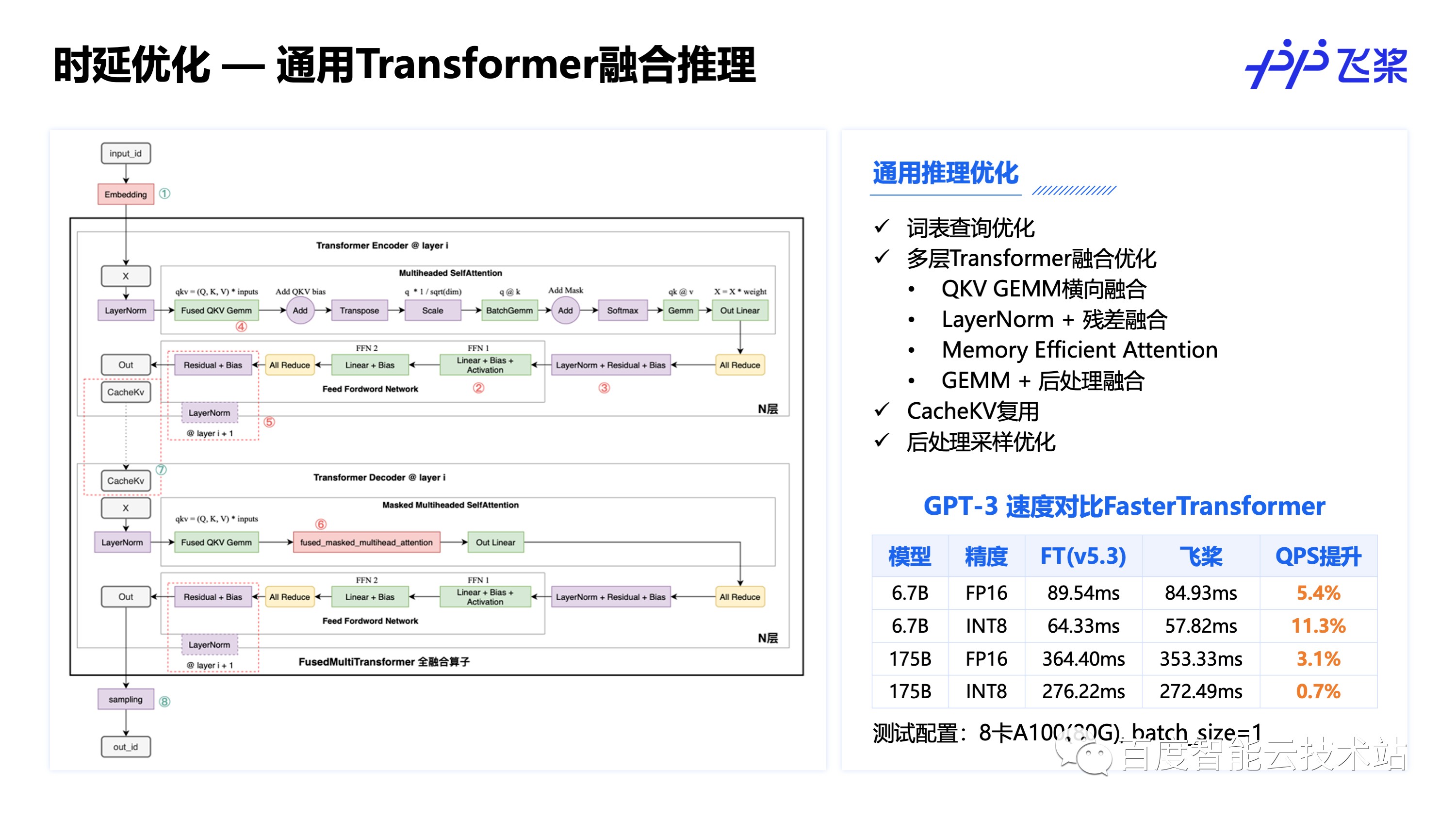
分布式并行更多是为了解决推理可行性问题,在推理时延优化上,通用的 Transformer 结构融合是常用的推理加速方式,这张图总结了常见的多层 Transformer 融合优化方法,业界也有很多相关的开源实现,飞桨通过这些优化后,推理速度可以打平或领先 NVIDIA FasterTransformer。
下面介绍一些进阶的推理时延优化方法。
动态量化是通过在推理过程动态的讲计算和激活转换为低精度的 INT8 计算来实现时延和显存的降低,但是为了保证精度无损往往需要进行特殊的算法设计,或者对量化部分做一些取舍。这里介绍了两种适用于生成式大模型的动态量化方法。
其中 LLM.int8() 结合大模型激活的离群点集中在少数通道上的特点,将离群点通道拆分出来做 FP16 计算,非离群点通道做 INT8 计算,计算完后再组装回去的方式来实现无损量化,适用于计算密集型的任务,而 Weight Only 量化则只对更易无损量化的权重,优化权重的存储和传输访存开销,适用于访存密集型的任务。
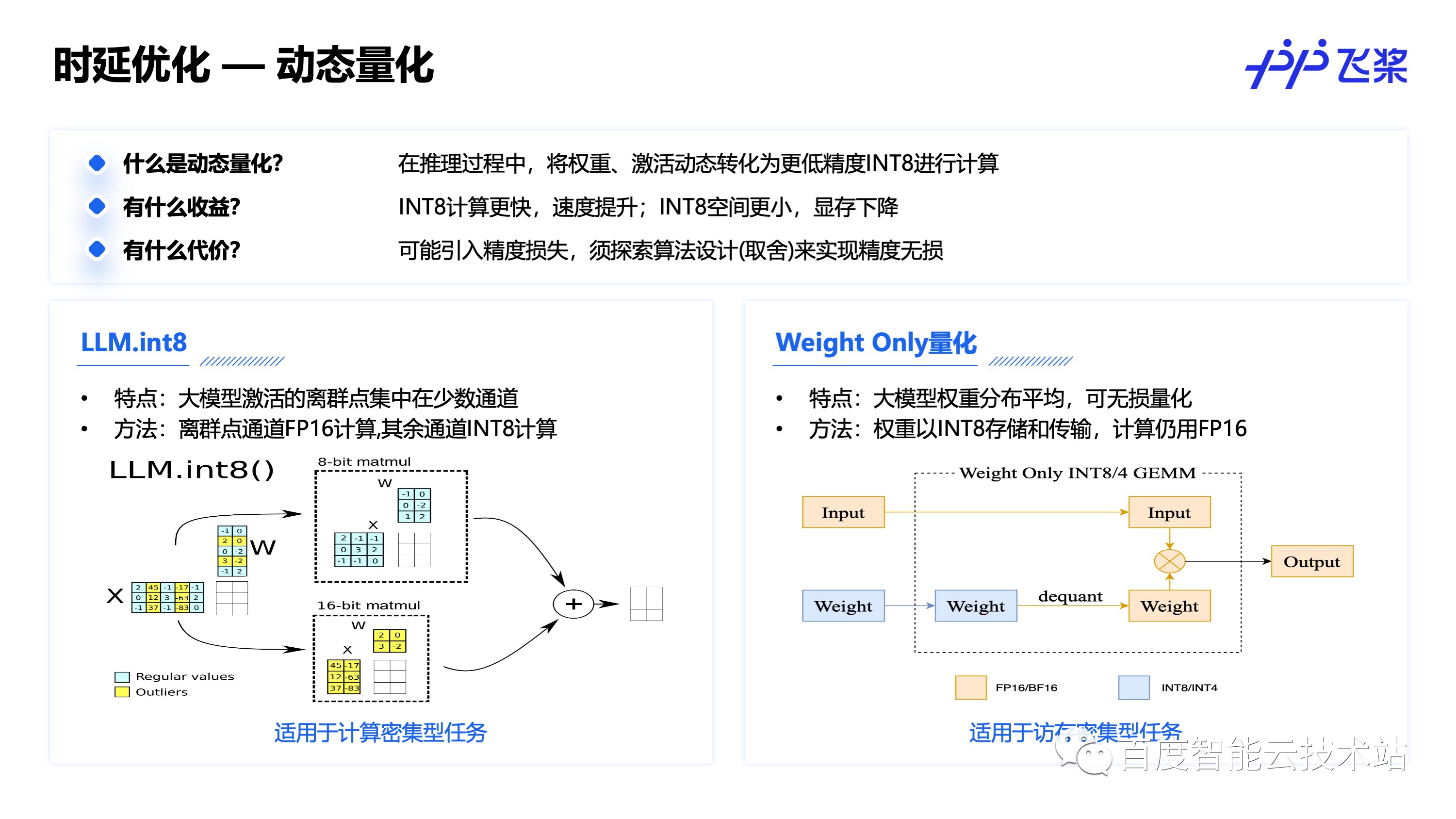
针对生成式大模型的特性,可以在 Context 阶段使用适用于计算密集型任务的 LLM.int8(),在 Generation 阶段使用使用访存密集型任务的 Weight Only 量化。
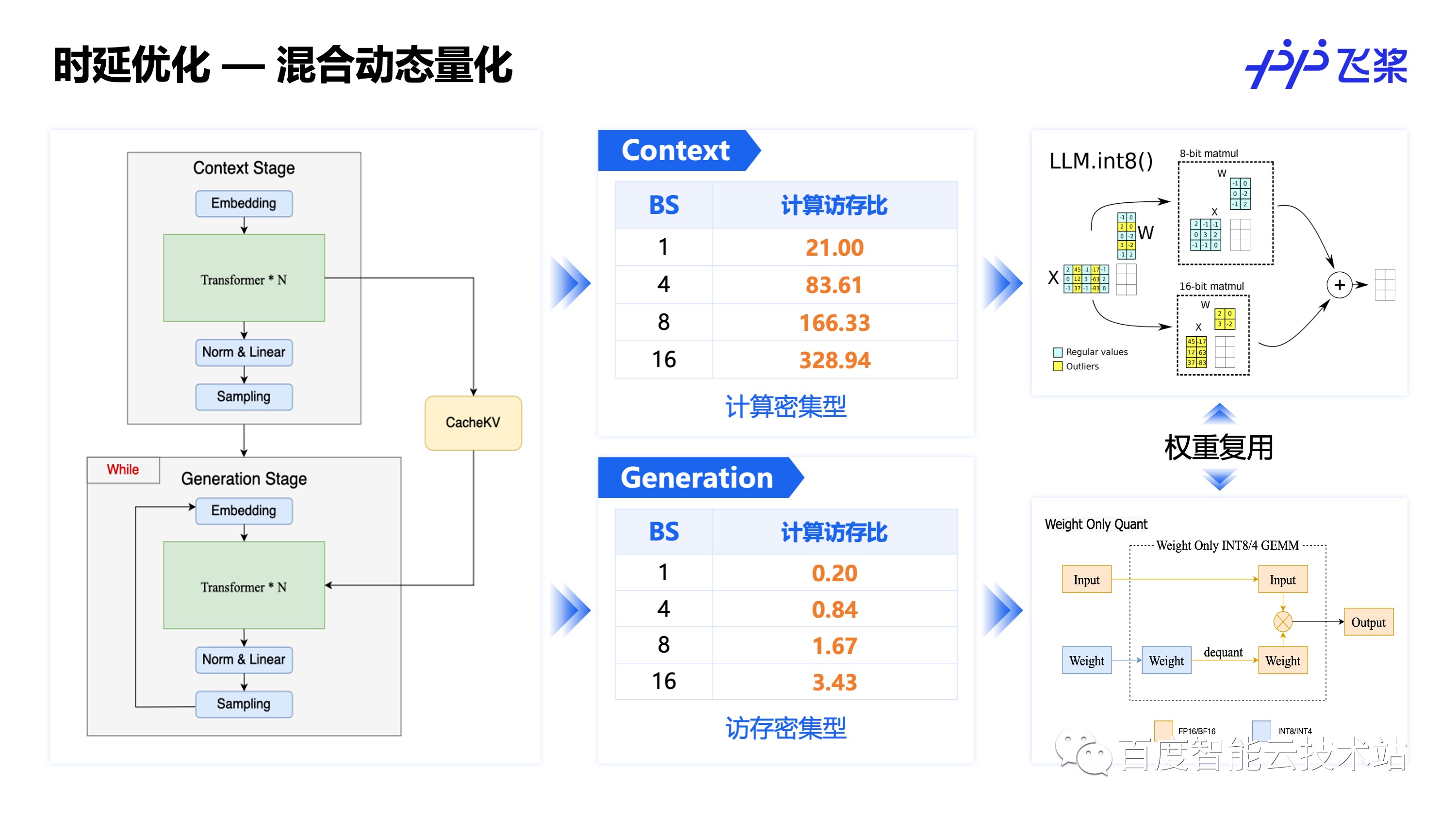
PTQ 量化相比于动态量化有更好的精度和速度,但是需要通过校准的方式计算量化 scale。SmoothQuant 是一种常用的大模型量化算法,由于生成式大模型激活离群点较多,比较难量化,而权重比较平滑,易于无损量化,SmoothQuant 通过等效变量,将激活的的离群点缩放到权重上去,平衡激活和权重的量化难度,从而实现更好的量化效果。

2.3 服务吞吐优化方法
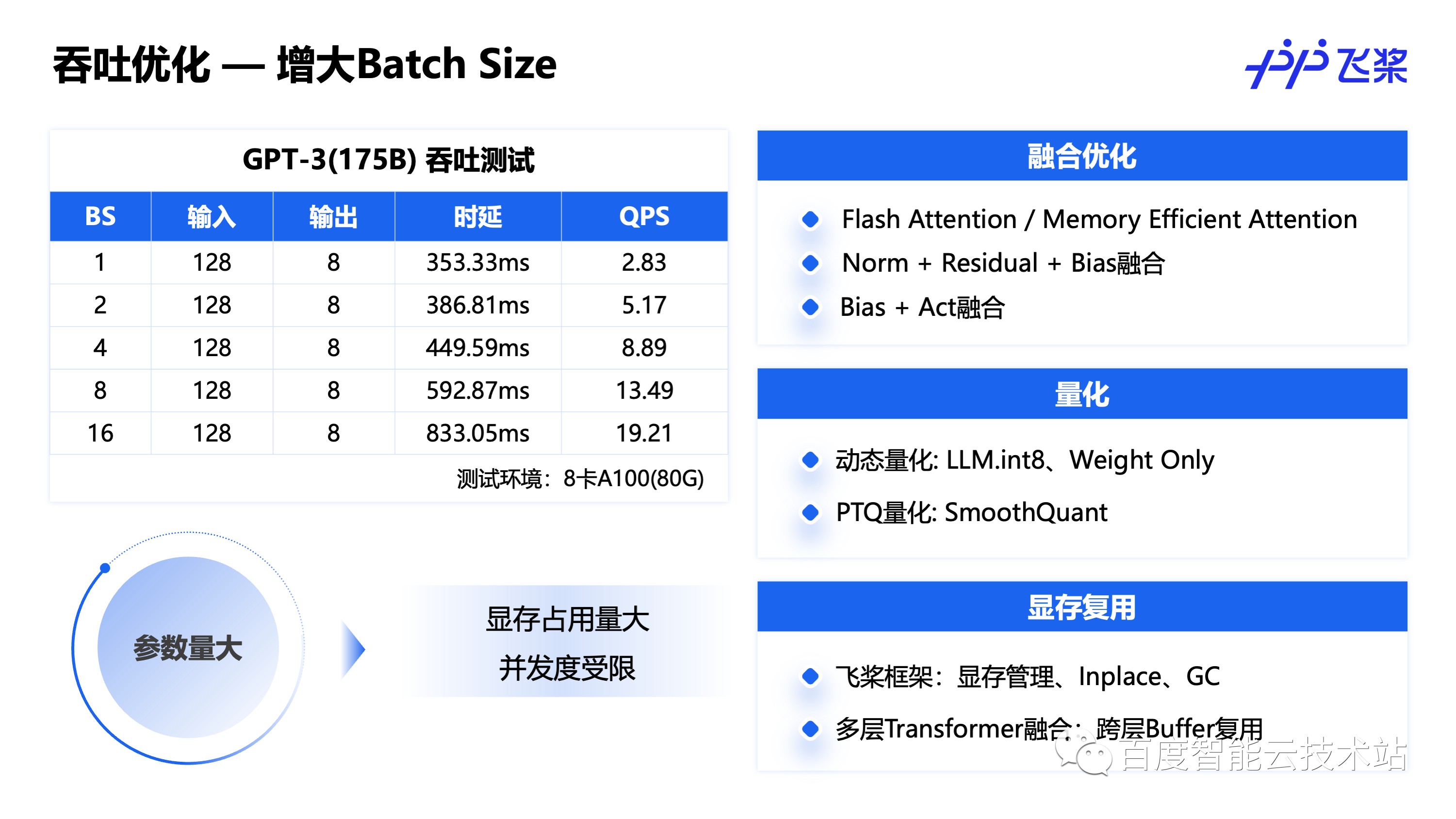
在服务部署上,除了推理时延优化外,还可以针对服务吞吐进行优化,增加 batch size 是常见的优化吞吐的方式,从表中可以看到,增大 batch size,虽然推理时延也会增加,但是 QPS 却能显著提升,但是大模型的显存占用大,增大 batch size 依赖对显存进行优化,其实上面介绍的时延优化方法中,融合和量化均能在优化时延的同时节省显存,同时也可以通过框架显存管理和多层 Transformer显存复用等方式进一步优化显存,从而开启更大的 batch size,提升推理并发度,实现吞吐提升。
增加 batch size 是常用的提升并发的方式,但是生成式任务有其特殊性,它是通过 While 循环来实现持续生成的,每次 While 循环 batch 内每个样本生成一个 token,但是由于不同样本的生成长度不一致,随着样本结束生成,实际生成过程中的并发度在持续变小,不利于并发度的提升,因此可以通过动态插入的方式来提升生成过程中的并发度。
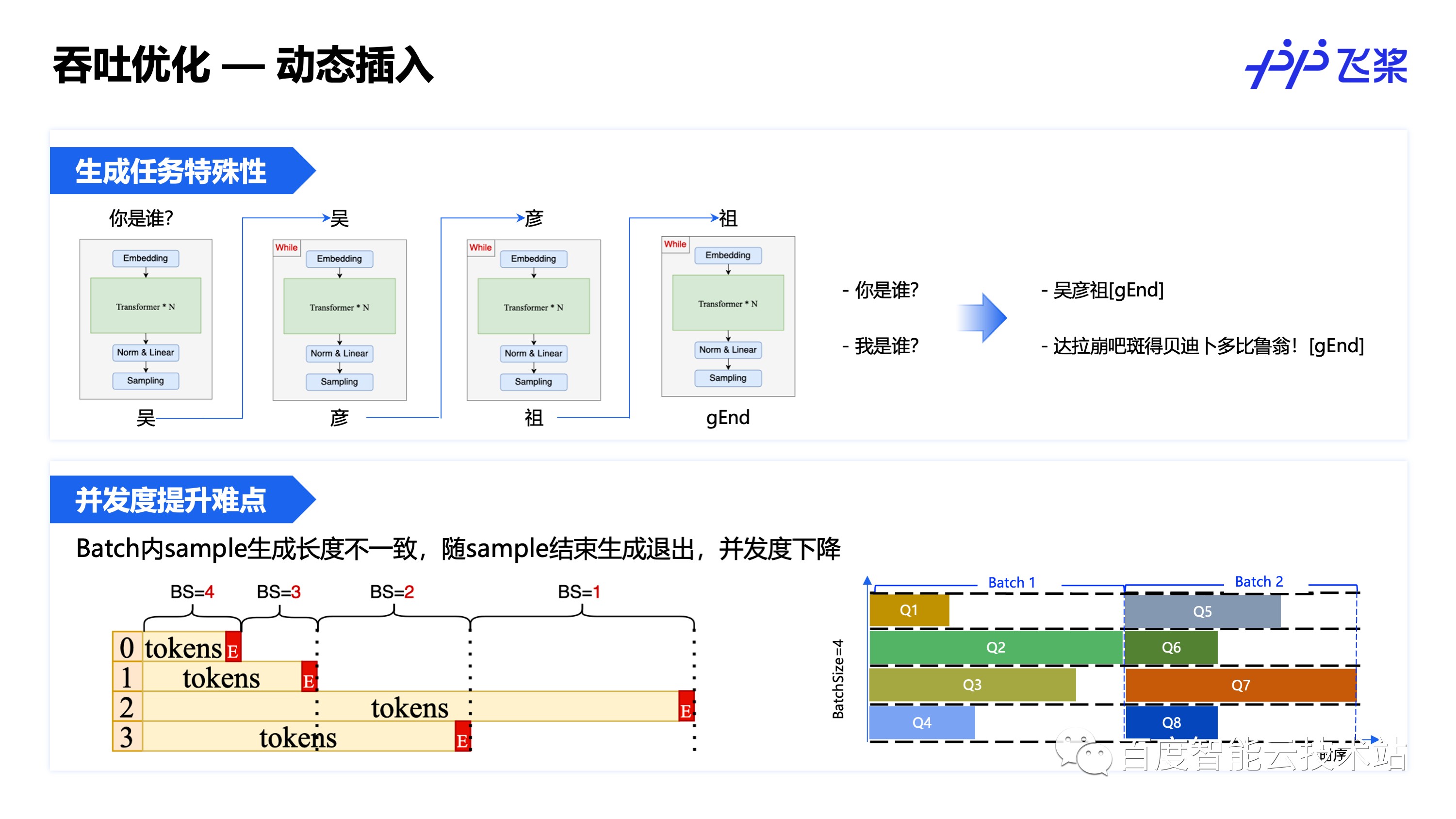
动态插入即在生成过程中实时地监控 batch 内样本结束生成的情况,当有样本结束生成时,动态地读取下一个 batch 的数据插入到上一个 batch 的空位中继续生成,从而实现生成过程中的并发度提升,实现更大的并发和吞吐。

以上介绍了生成式大模型的常用推理时延、吞吐优化方法,下表是对各优化方法的优化目标和使用场景的总结。

3. 多模态大模型推理高性能优化
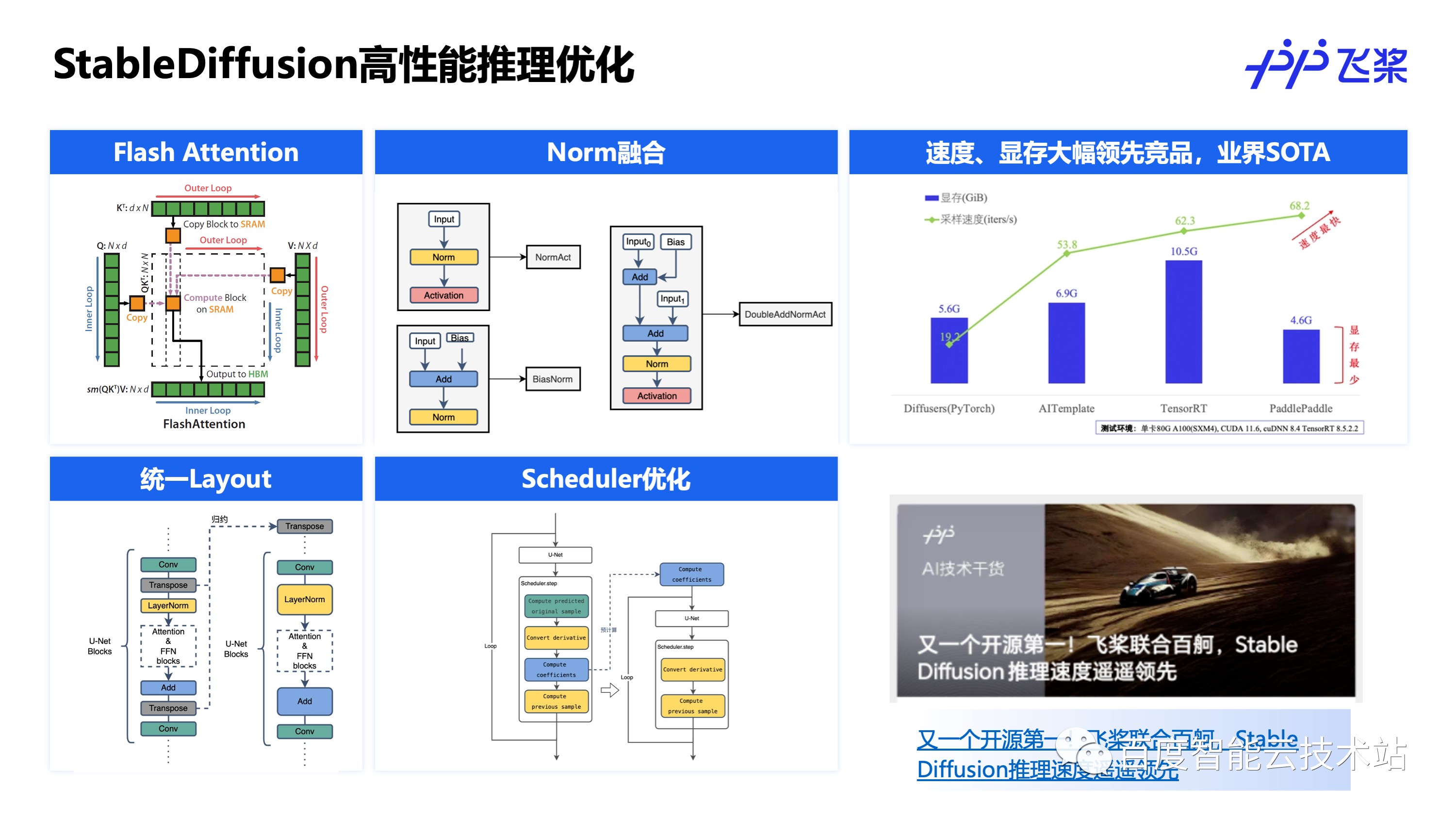
多模态大模型当前的热度也很高,目前在探索的方向也有很多,本文以文生图扩散模型 Stable Diffusion 为例介绍推理优化方法,由于 Stable Diffusion 推理中主要耗时 UNet 网络也是由 Attention 模块组成,因此可以复用大语言模型的优化方法。
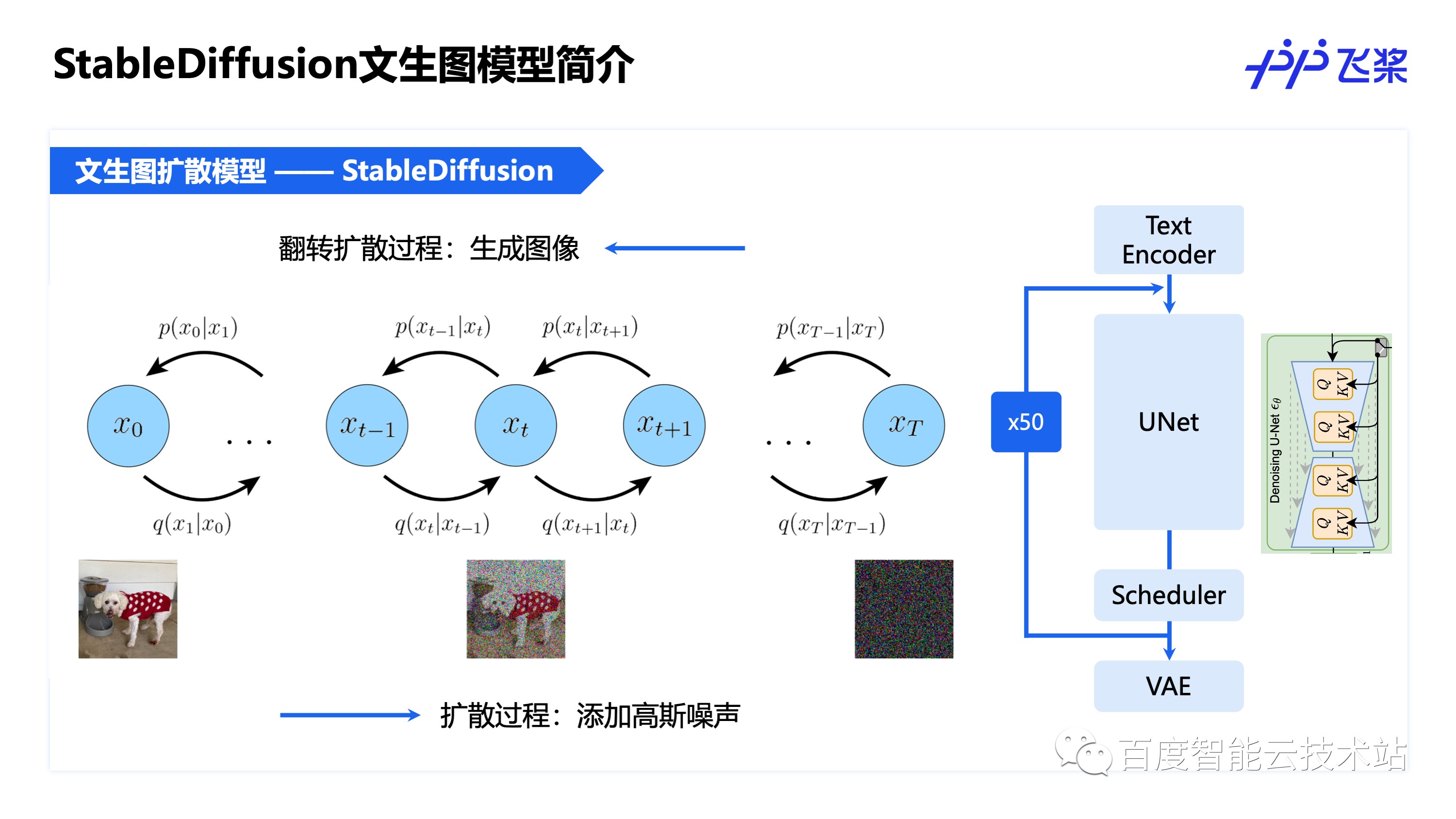
飞桨通过集成 Flash Attention,支持 4 中 Norm 结构共 90 多处融合、端到端统一计算 Layout 和 Scheduler 优化等多种方式,将 Stable Diffusion 的推理速度和显存占用均优化到了业界最优,优化方法细节可以阅读飞桨之前发布的文章:《又一个开源第一!飞桨联合百舸,Stable Diffusion 推理速度遥遥领先》

发表评论
登录后可评论,请前往 登录 或 注册