大数据的价值
作者:李不2021.05.25 14:56浏览量:610简介:大样本使大特征成为可能,大特征使大样本发挥价值。
很多人谈大数据都在泛泛的谈或者夸夸其谈,这里将站在一线实践者的角度讲解究竟大数据的价值在何处,大数据对机器模型来说意味着什么。
▌价值1:更细致的刻画

首先,从一个具体的案例开始:
我们选取全国3000名客户,考察客户对鞋子的喜好,并对客户的年龄、性别、居住地进行分类统计。经过统计调研后,得到两个非常重要的结论:
结论1:中国女性50%喜欢高跟鞋;
结论2:北京市海淀区5~10岁的女童,100%喜欢男性旅游鞋。
大家可以静下来思考下,结论1和结论2分别存在什么问题?
对于结论1,问题是进行的统计结论太宽泛了,即使我们知道中国女性50%喜欢高跟鞋这个统计结论,但实际上也不能做任何事;并且我们还发现,对于中国女性群体,是由非常多的不同类型的女性构成的。比如,一线城市月薪很高的年轻白领女性,这是一类群体;三四线城市赋闲在家带小孩的中年女性,这是一类群体。实际上,这两类群体的消费观念,对鞋子的喜好可能完全不一样。因此,如果对这两类群体进行统计的话,我们会发现二者对高跟鞋的喜好比例可能非常不一样。那么,当把二者合到一起放到一个更大的群体中国女性中,二者对商品的偏好就会被互相的掩盖和淹没掉,从而得出一个看起来非常中庸的结论,难以指导我们下一步的商业战略。
对于结论2,问题跟结论1恰好相反,正常来说我们应该非常喜欢这个结论,北京市海淀区5~10岁的女童100%喜欢男性旅游鞋,如果这个结论没有任何问题的话,我明天就会做一件事,就是跟老板提辞职,辞职之后,立马到海淀区专门开一家鞋店,专门卖男性旅游鞋给5~10岁的女童,肯定会赚很多钱。但是,虽然调研报告显示她们100%喜欢,但为什么没人真的做这件事?显然,这个结论是非常荒谬的,原因在于,当我们把3000名客户按照不同年龄性别和居住地进行划分时,发现落到北京市海淀区5~10岁女童的样本里只有一个,而这个小女孩目前对性别区分的不是很清楚。讲到这里,大家就会清楚的知道这个统计虽然非常细致,但是得到结论所基于的样本量太小了,其结果是不置信的。
通过上述的案例,我们可以体会到,当用大数定律从数据中理解统计结论时,往往面临两难:
一方面,我们期望数据足够细分,在每个细分中得到足够具体的认知,这样得到的认知,我们认为更加准确。
另一方面,我们又期望每个细分后的样本空间足够大。如上图中,当把所有数据样本按照年龄、性别和居住地三个维度进行切分后,可以看到三维空间中存在很多的小格子,我们期望每个小格子内有足够多的样本量,这样才能保证基于每个小格子得出的单独统计结论是足够置信的。
这两个问题是互相矛盾的,对吧?由于不断的切分数据,导致样本量不足,其结果必然不置信,反之则会导致结论没有价值,不够准确。那么,如何同时满足上述两点?答案就是大数据。
在基于大数据的情况下,我们可以同时满足上述两个条件。当样本量足够多近于无穷时,可以不断的细致的切分样本数据,同时,不管如何切分,每个数据格中的样本量都是足够的。所以当大家遇到对大数据概念各种吹嘘的人,可以用这句话去跟他们讨论下,就是大样本使大特征成为可能,大特征使大样本发挥价值。这句话很好理解,大样本使大特征成为可能,如果没有足够的样本量,而用太多的特征去切分数据,就会导致统计结论不置信,就像上面5~10岁女童的案例一样;大特征使大样本发挥价值,如果使用了大样本,但是没有特征,就会导致结论1的情况,可能最多几百个样本,就可以得到这样的结论,然而却使用了几百万个样本来得到这样的统一结论,这说明,这几百万样本的价值,完全没有得到发挥。
PS:刚刚提到过的置信和准确的衡量,其实在机器学习中有另外一个马甲叫过拟合和欠拟合。
讲到这里,大数据的第一个价值就是:更细致的刻画。
▌为何能学的重新理解
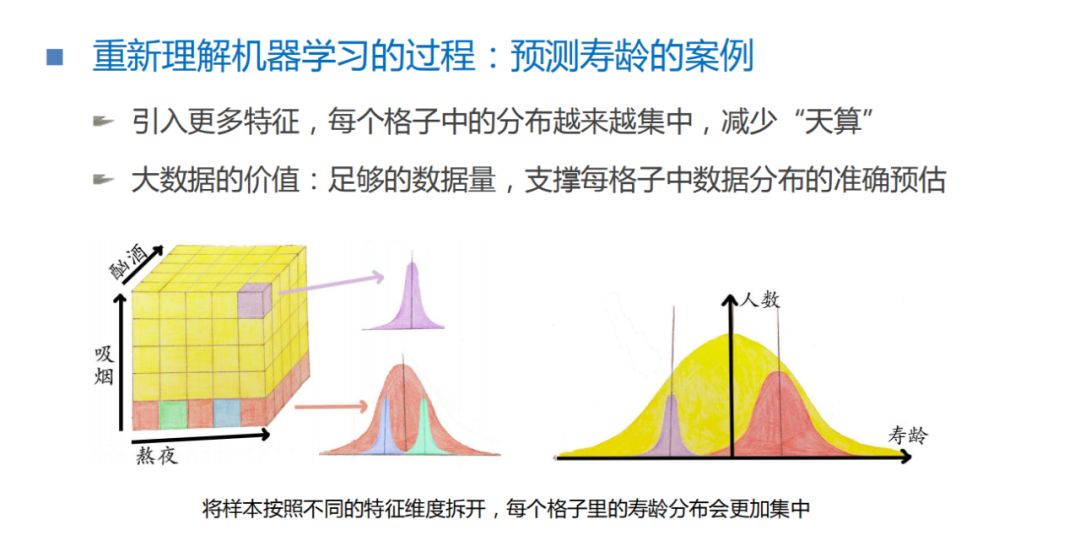
接下来用我们刚刚学到的理论,来重新理解机器学习的过程。假设,我们期望通过一个人是否酗酒、吸烟、熬夜,这样的特征来预测一个人的寿龄。首先,不考虑这些特征时,得到的寿龄分布是一个宽泛的分布,当引入同时吸烟、酗酒和熬夜这一细分人群时,发现寿龄的分布会变窄。从上图可以看到,随着不断的用各种生活习惯切分样本空间数据,就会把一个很宽泛的分布慢慢的变成一个很窄、很细、很尖的一个分布。也就是说,我们能更加准确的预测某种类别人类的寿龄。这样的过程,其实就是减少天算,加强人算的过程。这就是机器为什么能够学习,大家可以通过这样的例子去理解。
因此,大数据的价值,保证了不管对样本空间如何进行切分,每个格子里都有足够的样本量,能够准确的画出数据样本的分布。
▌大数据的价值2:更智能的学习
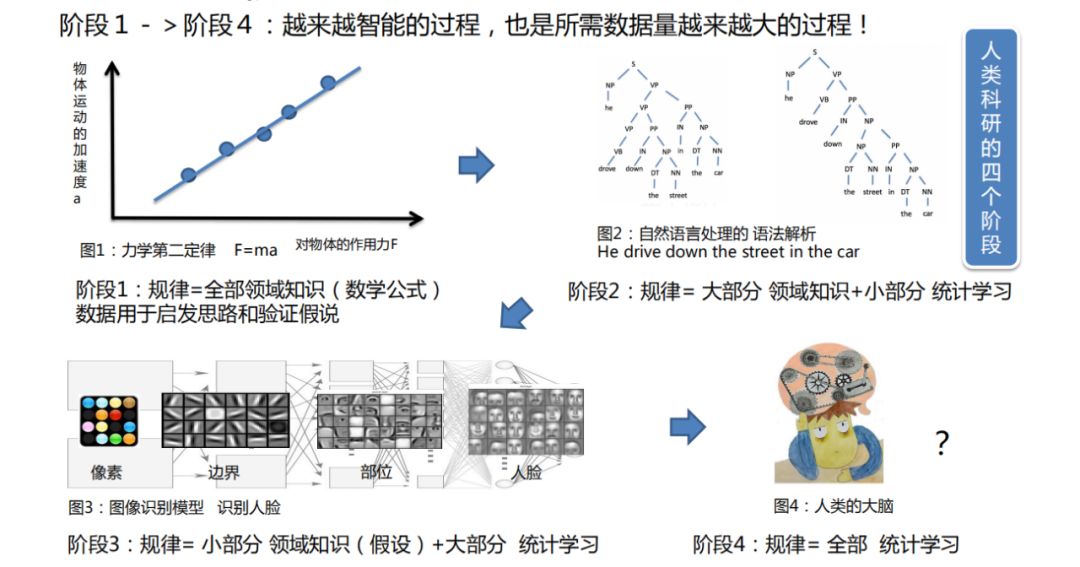
大数据的第二个价值是可以更智能的学习。如何理解?我们来看下机器学习或者是人工智能、泛人工智能领域,在这些年经历的不同发展阶段给出的启示:
阶段1:最典型的代表就是之前跟大家介绍的牛顿力学第二定律的例子。其验证过程是牛顿先通过领域知识(就是牛顿通过实验对事情的理解)做出来一种假设 F=ma,然后通过大量的实验数据来验证这个假设。这一个阶段,规律就好像等于全部的领域知识,数据仅仅用于启发领域知识的思路或者验证领域知识,并且数据量往往不是特别大。
阶段2:以自然语言处理中的语法解析为例,这是一段英文:He drive down the street in the car. 这句话如何进行语法解析呢?就是解析成语法树,大概谁修饰谁这样一个关系。那么 in the car 这个定语,按语法解析来说,有两种可能,第一种可能是修饰 drive down 的,就是开车再走。第二种可能是修饰 street,在车里的一条路。人类理解这个事情很容易,第二种是不可能的,肯定是第一种。但是机器如果单纯从领域知识也就是语法的角度去认识,这两种情况都是正确的。那么,如何解决这个问题?实际上,我们是把这两个符合领域知识的语法树全部建立出来,然后通过数据的方式统计哪一种在大量语料中发生的概率是比较大的。发生概率大的,就是正确解析的语法树。通过这个案例,我们可以知道,实际上是用大部分的领域知识+小部分的统计学习,来解决这样的问题。
阶段3:规律=小部分领域知识(假设)+大部分统计学习,典型的案例就是图像识别,比如人脸识别。当前,主要在图像领域,很多算法都被深度学习的算法所替代,对于深度学习的算法来说,并不需要太多的对图像领域知识的理解,更多的是当有足够的数据,就可以把图片的像素慢慢提取成边界的特征,慢慢提取成部位的特征,最后形成人脸的特征,完成人脸识别的任务。这个过程中特征的识别是机器自己做到的,这样做的前提,就是需要更多的数据。
阶段4:根据阶段3,我们可以畅想下,在阶段3发展下去,我们所要学的规律,完全靠统计学习和机器智能学习得到,而不需要任何的领域知识。我们从前面三个阶段发现,对领域知识的依赖越来越少了,基于数据学习的部分越来越多了,当然达到这一点,意味着需要更多的数据。
这就是大数据的第二个价值:更智能的学习。
▌总结:两个价值的效果

最后,总结下大数据给机器学习带来帮助的两个价值。首先,回顾下机器学习任务是解决什么问题,机器学习的任务是从已知的数据中学习出规律,即特征 X 跟预测值 Y 之间的函数关系。当不知道输出值 Y,但特征 X 已知时,可以达到自动判断 Y 究竟是多少,这样的效果。因此,对于机器学习任务或者监督学习任务,第一个价值,带来的是精细刻画的价值,释放了学习预测值 Y 跟特征 X 关系的可能。当 X 变得特别复杂特别多,或者 X 跟 Y 关系特别复杂的时候,需要更多的大数据的样本进行学习,否则就会出现不置信的情况。第二个价值,带来的是更智能的学习。随着学习技术不断的发展,对数据的使用变得越加智能,从一开始全部的领域知识和仅仅用一些数据去做验证,到用一部分领域知识再加上很多数据做判断,到现在的阶段,可能只用很少的领域知识优化模型的假设,但是用大量的数据,填充到没有用领域知识学习的部分。随着学习变得更智能,需要的数据量也越来越庞大。所以,只有在大数据的情况下,才能越来越智能的学习,释放自动学习特征的能力。通过这两个价值,可以思考下,假设(通常是人类对领域知识的认识)其实是被越来越弱化了,更多的是通过越来越大的数据量来不断的填充假设部分。
可以设想下,在未来,当有非常非常多的数据量时,只需要指定任务和学习的 Y 值,机器就可以把所有的学习和预测都搞定。这就是从一线实践者的角度来看,大数据对机器学习模型的意义所在。
相关文章推荐
发表评论
关于作者

- 被阅读数
- 被赞数
- 被收藏数
登录后可评论,请前往 登录 或 注册